A better user experience for footnotes ↩
Before I dive into some of the sublime text customizations, I want to cover a super simple tweak that will make your life better. And, if you're happy, I'm happy!
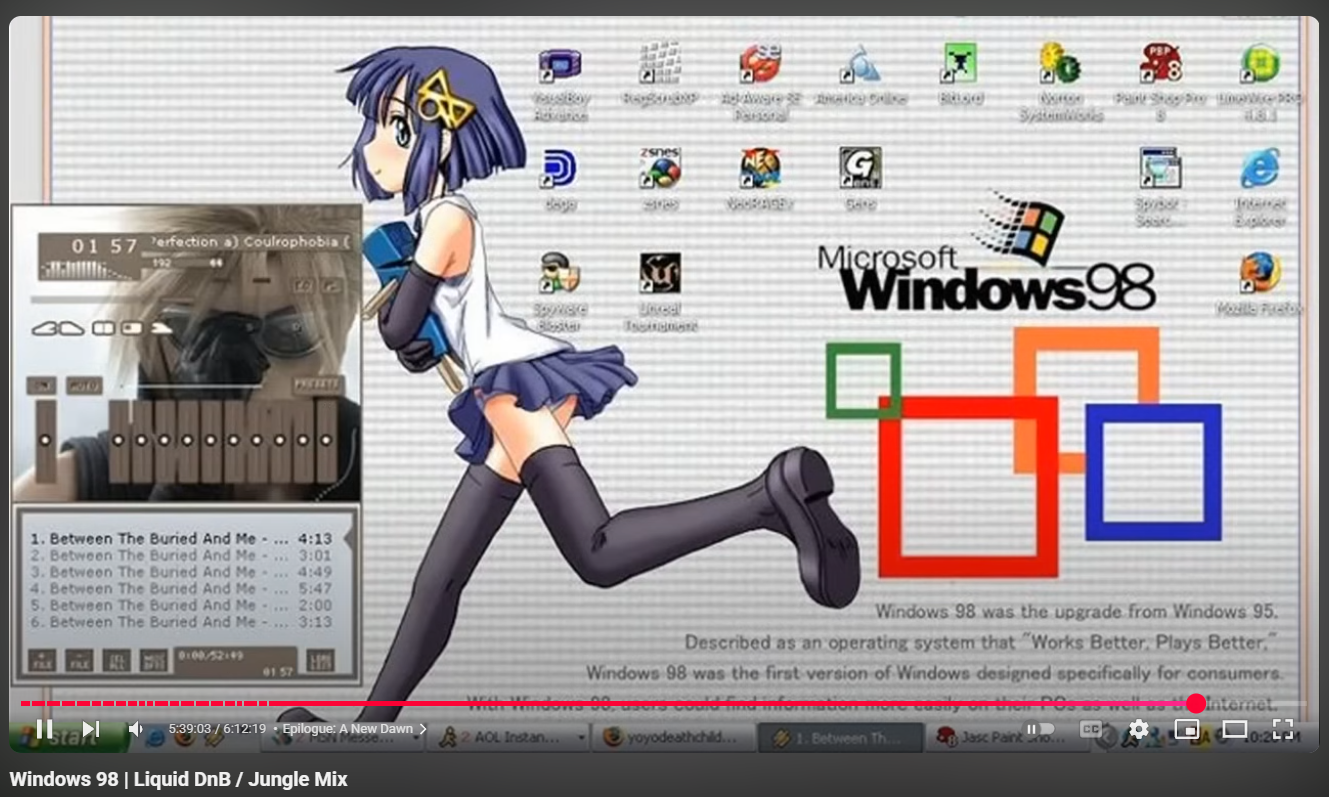
One of the nice things about blogging is that, assuming you provide a way for others to contact you, people do! And often, they have helpful and useful suggestions or observations. In this case, when you follow a footnote link to the bottom of the page 1, you'll notice that you can now see the original footnote reference that you clicked on.
Before I made a pretty simple CSS tweak, I hadn't noticed or realized that the sticky header for the section headings was obstructing your view of it! Which meant that if you were following the footnote, then following the arrow back up to where you had left off, you were confused and had to scroll just a little bit up to see where you were.
Obviously that's not ideal. And I was pretty happy when not only did someone
point this out, but they also clued me in on the existence of scroll-margin-top.
Which was the first step in figuring out how to fix this problem. The MDN docs are a decent place to start, but I also went digging
in stackoverflow for a while as well, surprisingly enough, no one really mentions that handy new property.
Though some do mention the use of margin-top and padding-top that
I ultimately landed on. If you examine the CSS for this page you'll see this:
:target {
margin-top: -8em;
padding-top: 8em;
}
I didn't end up using scroll-margin-top because it's controlling where the
browser will align when you scroll with your scroll wheel. I want to avoid you having to
scroll entirely! And so, a big negative margin and a padding along the top to fill it
results in each anchor having dimensions like this:
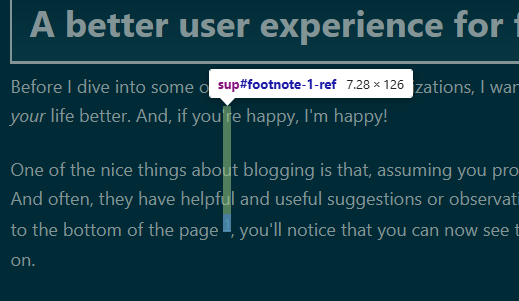
Which maybe feels a bit funny, but when you jump back to the anchor, it's going to align things to fit the entire anchor into your view, and so you end up with your context back. There is one other idea I had to make your life easier that I haven't tried yet though.
It still takes a moment for me to find and refocus back onto the 1 when I return from reading a footnote. And so, taking some inspiration from a lisp video I watched recently, I decided to add this:
/* Make it easier for the person to jump to the footnote
* reference without the sticky top being on top of it */
:target {
margin-top: -8em;
padding-top: 8em;
}
/* Will help find a general target, like the footnote li pulse */
:target {
animation: 1.0s linear forwards flash-target;
}
/* Will only work in modern browsers, but will flash the text
* of the paragraph when we return from a footnote back to its
* reference point.
*/
p:has(:target) {
animation: 1.0s linear forwards flash-target;
}
@keyframes flash-target {
0% {
color: var(--font-color);
}
50% {
color: white;
}
100% {
color: var(--font-color);
}
}
/* Prevent seizures for sensitive folks */
@media (prefers-reduced-motion: reduce) {
* {
animation: none !important;
transition: none !important;
}
}
If you've followed any footnotes, you'll have seen it in action already. But I think that this makes is easier for a reader to refocus back on the right paragraph where they left off. And if there are a lot of footnotes, then it will guide their eyes to the one that's relevant to what they were just reading.
As far as the point in the video where inspiration struck, I don't remember the specific timestamp. But at one point the instructor is talking about the balancing of the parenthesis and how lisp terminals, when you close a paren, will briefly highlight the opening paren as well. This makes it easy for a programmer to tell where the boundaries of their various compounds are. So, highlight the text I want the user to be drawn to. Simple. I just hope that a 1s pulse isn't going to be a problem for any epilitecs.
I also added in a bit of none-ing for sections and the toc since I don't think it benefits anyone to flash a wall of text or a set of list items:
section:target {
animation: none;
}
#toc:target {
animation: none;
}
But with that in place, I think we've improved the user experience! It was interesting to learn that you cannot animate a visited pseudo state due to "privacy restrictions". It sounds a lot like a bunch of bad actors abused link farming and JS to do some unpleasant and anti-user privacy things which is too bad. Why is it always the few who ruin it for the many? Anyway, hopefully this improves your time here at least and a few lines of css make many people have an easier time reading and jumping between footnotes and their reference points.
Now…, let's get back to improving my experience.
Live reloading web files ↩
Keeping with the theme of this post being a little bit more tangential than focused solely on sublimetext plugin coding, we've got to talk about one of the good thing VS Code has by default.
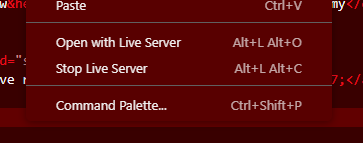
The ability to right click and pop open a live server to view your HTML is pretty nice. But, do I really want to spend checks task manager … 783MB on a single process for this? Not really. If I have a terminal open running livereload it takes 2MB and 0.1% of my cpu.
So, really the only thing that I want to see if I can do is easily run up livereload without having to leave my editor so that I have that similar "pop this HTML open in a browser real quick" feeling that VSCode gives you. First off, installing live reload is super easy:
$ pip install livereload
Collecting livereload
Downloading livereload-2.7.1-py3-none-any.whl (22 kB)
Collecting tornado
Downloading tornado-6.5.1-cp39-abi3-win_amd64.whl (444 kB)
-------------------------------------- 444.8/444.8 kB 1.1 MB/s eta 0:00:00
Installing collected packages: tornado, livereload
Successfully installed livereload-2.7.1 tornado-6.5.1
Then fire up the exe 2 with the quick and easy
livereload.exe .
and bobs your uncle. 3 We've got live reload happening for the folder we were running in. Great. That instantly makes me think about the fact that I've got multiple folders open in sublime right now. So there's our first little spec I guess:
- We should be able to start livereload in any folder we have open
Which begs the question of if I should make it possible for me to run it in a subfolder as well. Don't you love when you think about something as simple as "and open the thing" and it turns into "but how and why and where and so on…". My plan to manage that spiral in my head though is to just get started with some thing easier.
How would we open a file in the browser? If you remember from the first time we did any of this fun stuff we looked through a lot of reference material and one of those files is the command that appears in sublime if you right click inside of an HTML file:
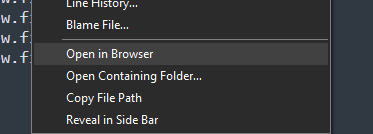
The code for the command is pretty tiny:
import webbrowser
import sublime_plugin
class OpenInBrowserCommand(sublime_plugin.TextCommand):
def run(self, edit):
if self.view.file_name():
webbrowser.open_new_tab("file://" + self.view.file_name())
def is_visible(self):
return self.view.file_name() is not None and (
self.view.file_name()[-5:] == ".html" or
self.view.file_name()[-5:] == ".HTML" or
self.view.file_name()[-4:] == ".htm" or
self.view.file_name()[-4:] == ".HTM")
The observation I'm making here though is that there's a webbrowser" module available to us and it's really easy to use. So, if I make something that's aware of any running livereload instances open, then I could technically, maybe potentially offer a command to open the file with that.
The hard part of this all of course is that, I'm not sure if I should go with the braindead simple: livereload from my terminal runs on port X so always use port X and call it a day. Or if I should try to spend extra time to actually run up the process, or rather, subprocess, in sublime and capture information about that or similar.
If I were to try to re-use the exec commands to do this with just sublime commands:
{
"caption": "Blag: start live-reload",
"command": "exec",
"args": {
"cmd": ["livereload.exe", "-p", "35729", "."],
},
"working_dir": "$folder"
}

And it claims to run, starting up in the window pane of sublime text with a
[I 250628 23:19:54 server:331] Serving on http://127.0.0.1:35729
[I 250628 23:19:54 handlers:62] Start watching changes
[I 250628 23:19:54 handlers:64] Start detecting changes
But, well... how do I stop it? There's always taskkill and tasklist I suppose, and we could even run those commands from sublime as well. They certainly work well enough:
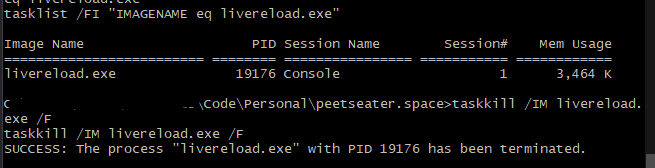
But more importantly. This "folder" variable is landing on "blag" here and not at what its docs imply
$folder The full path to the first folder listed in the side bar.
Certainly sounds like it should be "peetseater.space" if I have that whole folder open in my editor, doesn't it? I thought maybe it should be this one instead then:
$project_path The path to the folder containing the current project file.
But no dice. This is unfortunate, since opening the livereload server from the folder that the current file is in means that none of our images load. Obviously, I could run the command while I had the top level index file open, but that's not really any good at all. So, instead, we'll have to abandon the idea of using the .sublime-commands file and instead drop back down into python.
import sublime
import sublime_plugin
import os
import subprocess
class LiveReloadStartCommand(sublime_plugin.WindowCommand):
def run(self):
if not self.window.active_view():
print("no active view")
return
sheet_file_name = self.window.active_sheet().file_name()
if sheet_file_name is None:
print("file not saved yet")
return
longest_path = None
for folder in self.window.folders():
in_common = os.path.commonprefix([sheet_file_name, folder])
if longest_path is None or len(in_common) > len(longest_path):
longest_path = in_common
print(f"cwd will be {longest_path}")
return; # temporary stop before we run the command
Wiring this up in our sublime-commands file by adding
{ "caption": "Blag: start live-reload", "command": "live_reload_start" }
to the list lets me test that I haven't gotten my thoughts wrong about this so far:
reloading plugin HrefHelper.previewserver cwd will be C:\full\path\to\Code\Personal\peetseater.space
Worked first try! Man, I really love how simple the os.path.commonprefix
makes this type of stuff. Alright, since I can get what we want the current working
directory to be, we can use that when we run up the commands. But also, let's be smart!
Since I know I'll have multiple folders open, let's just make sure that we run multiple
livereloads if we need to:
...
folder_to_running_processes = {}
port_to_start_at = 35729
class LiveReloadStartCommand(sublime_plugin.WindowCommand):
def run(self):
... code from before finding the root folder our file is in...
if longest_path in folder_to_running_processes:
print("livereload is running and will be restarted?")
folder_to_running_processes[longest_path].kill()
global port_to_start_at
command = ["livereload.exe", "-p", f"{port_to_start_at}", longest_path]
try:
process = subprocess.Popen(
command,
cwd=os.path.dirname(longest_path),
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
shell=True
)
folder_to_running_processes[longest_path] = process
port_to_start_at += 1
print(command) # I am debugging :)
sublime.status_message(f"livereload.exe on port {port_to_start_at - 1}")
except Exception as e:
sublime.error_message(f"Failed to run command: {e}")
Though, this definitely isn't perfect. Let's not have the port increment every single time, since if I run the command 3 times I end up with
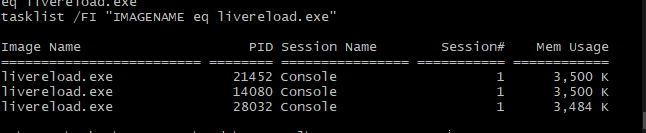
which isn't quite what I want. I want the port to stay consistent for the given folder so that I don't have to mess with my browser at all. So, if we track the process and its port in a tuple, then we can do this:
global port_to_start_at
process_port = port_to_start_at
if longest_path in folder_to_running_processes:
print("livereload is running and will be restarted?")
[process, previously_used_port] = folder_to_running_processes[longest_path]
process_port = previously_used_port
process.kill()
command = ["livereload.exe", "-p", f"{process_port}", longest_path]
try:
process = subprocess.Popen(
command,
cwd=os.path.dirname(longest_path),
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
shell=True
)
sublime.status_message(f"Started livereload.exe on port {process_port}")
folder_to_running_processes[longest_path] = (process, process_port)
if port_to_start_at == process_port:
port_to_start_at += 1
print(command)
except Exception as e:
sublime.error_message(f"Failed to run command: {e}")
Spamming the command a bit and swapping folders shows me that the expected thing is happening. New folder? New port! Old folder? Same port!
['livereload.exe', '-p', '35729', 'path\\to\\Personal\\peetseater.space'] ['livereload.exe', '-p', '35730', 'path\\to\\Packages\\HrefHelper'] livereload is running and will be restarted? ['livereload.exe', '-p', '35730', 'path\\to\\Packages\\HrefHelper'] livereload is running and will be restarted? ['livereload.exe', '-p', '35729', 'path\\to\\Personal\\peetseater.space']
So that's good! Now, if I reload my plugin however, I lose my variables and that's no good. So, let's make it easy to kill off any and all livereloads that are going. As before, we can update our .sublime-commands file with a reference to the command we're about to make:
{ "caption": "Blag: stop all live-reload", "command": "stop_all_live_reload_servers" }
And then make a window command that matches the command's name:
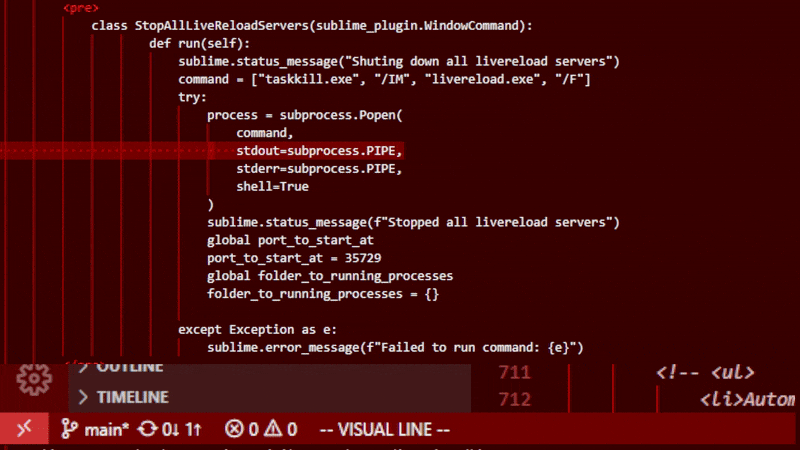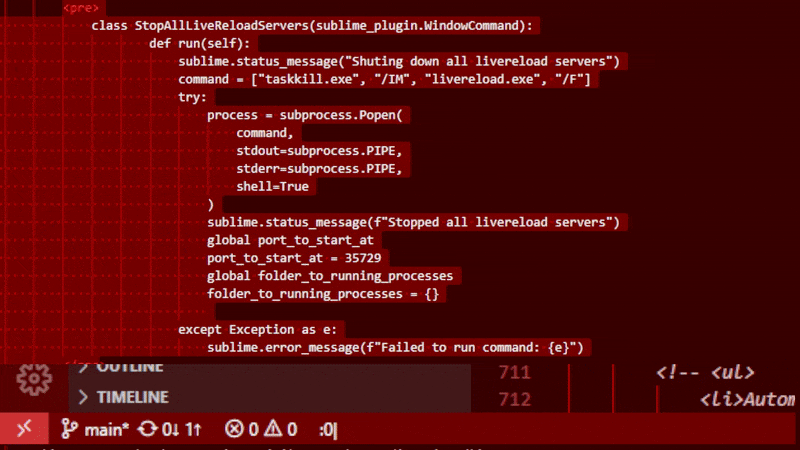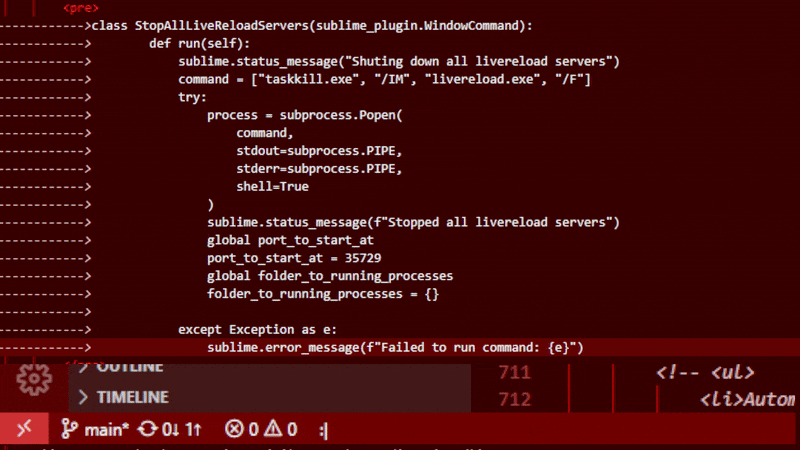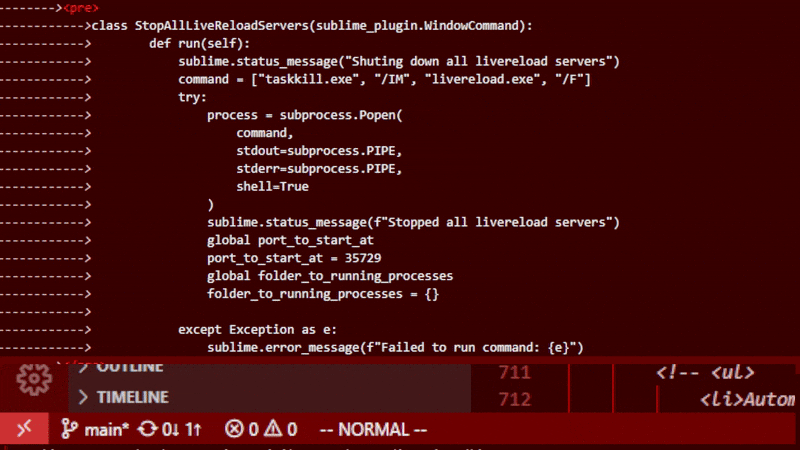
class StopAllLiveReloadServers(sublime_plugin.WindowCommand):
def run(self):
print("Shuting down all livereload servers")
command = ["taskkill.exe", "/IM", "livereload.exe", "/F"]
try:
process = subprocess.Popen(
command,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
shell=True
)
sublime.status_message(f"Stopped all livereload servers")
global port_to_start_at
port_to_start_at = 35729
global folder_to_running_processes
folder_to_running_processes = {}
except Exception as e:
sublime.error_message(f"Failed to run command: {e}")
Now obviously this is only going to work on windows. So, if we were trying to make this work on any and all machines, I'd need to tweak things a bit, but for the time being I'll just leave it as is. 4 Mainly because we haven't even gotten to the replacement command yet! We've got the server running, and we've got a reference to it in sublime text, and so now we can add in a new menu command!
I'll add in a context menu similar to VSCode's for the sake of old habits, but I'd bet you at least 1 dollar that I'll probably trigger it mostly from the command palette since typing is faster than moving my hand to the mouse and back. In Context.sublime-menu in my package I can add this in:
[
{ "caption": "-", "id": "file" },
{ "caption": "-", "id": "blag" },
{ "command": "open_in_live_reload", "caption": "Live reload this folder" },
{ "caption": "-", "id": "end" }
]
And this will produce the following menu for me:
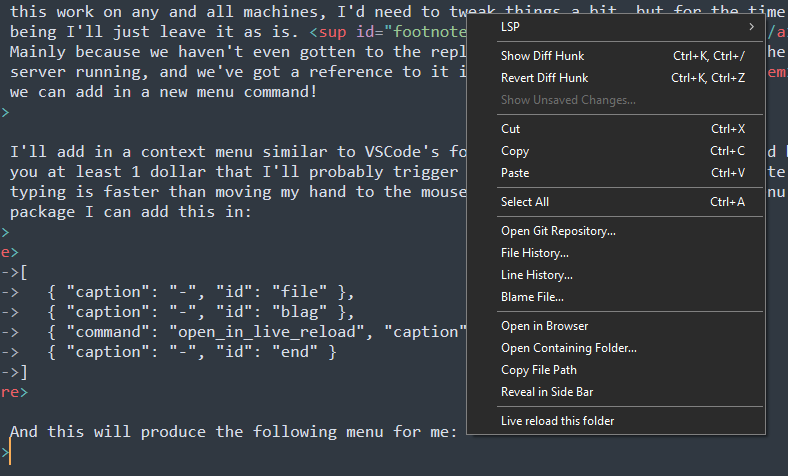
The id and the order thereof in the context file helps sublime
figure out where to put in my new slot. In this case, I've specified both
file and end slots so that the blag area can be
at the bottom. I thought about tring to slip it into the same area as the
"Open in Browser" command, or maybe even replace that, but for ease of
testing, I'm just going to use a new section.
This doesn't even do anything yet, so let's fix that! This is going to be a mix of what we saw with the Open in browser command and the live reload commands so far, hold your nose, we're using globals again!
class OpenInLiveReloadCommand(sublime_plugin.TextCommand):
def run(self, edit):
if not self.view.file_name():
return
sheet_file_name = self.view.window().active_sheet().file_name()
if sheet_file_name is None:
print("file not saved yet")
return
longest_path = None
for folder in self.view.window().folders():
in_common = os.path.commonprefix([sheet_file_name, folder])
if longest_path is None or len(in_common) > len(longest_path):
longest_path = in_common
global folder_to_running_processes
if longest_path not in folder_to_running_processes:
print("No running live reload yet!")
sublime.run_command("live_reload_start") # <-- this doesn't work!
if longest_path not in folder_to_running_processes:
print("Could not get a livereload port determined, bailing out")
return
[process, process_port] = folder_to_running_processes[longest_path]
relative_file_path = os.path.relpath(self.view.file_name(), longest_path)
web_path = "/".join(relative_file_path.split(os.sep))
url = f"http://127.0.0.1:{process_port}/{web_path}"
webbrowser.open_new_tab(url)
def is_visible(self):
return self.view.file_name() is not None and (
self.view.file_name()[-5:] == ".html" or
self.view.file_name()[-5:] == ".HTML" or
self.view.file_name()[-4:] == ".htm" or
self.view.file_name()[-4:] == ".HTM")
putting aside the ugliness of the print statements, the repeated code, and the callout that I've got something in here that doesn't work, this works! 5 I can right click (or use the command palette) and my current html file I'm in will open up in the default browser of my OS.
There's not a ton to say about the code except for os.path.relpath, much
like os.path.commonprefix is handling the heavy thinking here for us on
relativizing the path for us. In Java I believe I'd be using Path.resolve()
between then and forgeting the order of whether the parent or child should be doing the
call. But, in Python, the docs
are pretty good and the signature of os.path.relpath(path, start=os.curdir)
is clear.
Let's make sure that when we run this command, context menu or palette driven, that if a live reload server is not currently running it boots one up for us. This will give us the same functionality as VSCode's built in helper. To do this, first thing's first, let's refactor!
The code that I wanted to run via sublime.run_command is in LiveReloadStartCommand,
basically the bit that comes after all the guard checks. Let's lift that up into a plugin level function:
def start_live_reload(folder_path):
global port_to_start_at
global folder_to_running_processes
process_port = port_to_start_at
if folder_path in folder_to_running_processes:
print("livereload is running and will be restarted?")
[process, previously_used_port] = folder_to_running_processes[folder_path]
process_port = previously_used_port
process.kill()
command = ["livereload.exe", "-p", f"{process_port}", folder_path]
try:
process = subprocess.Popen(
command,
cwd=os.path.dirname(folder_path),
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
shell=True
)
sublime.status_message(f"Started livereload.exe on port {process_port}")
folder_to_running_processes[folder_path] = (process, process_port)
if port_to_start_at == process_port:
port_to_start_at += 1
print(command)
except Exception as e:
sublime.error_message(f"Failed to run command: {e}")
With this in a helper method, the two commands can just re-use that and things
will be both slightly DRY-er and also I won't have to wonder why run_command
did not, in fact, run the command.
class LiveReloadStartCommand(sublime_plugin.WindowCommand):
def run(self):
...
longest_path = None
for folder in self.window.folders():
in_common = os.path.commonprefix([sheet_file_name, folder])
if longest_path is None or len(in_common) > len(longest_path):
longest_path = in_common
start_live_reload(longest_path)
class OpenInLiveReloadCommand(sublime_plugin.TextCommand):
def run(self, edit):
...
if longest_path not in folder_to_running_processes:
print("No running live reload yet!")
start_live_reload(longest_path)
And with that, I've got the functional equivalent to something that requires over half a gig in the bloatware VSCode users call an editor. Except of course, mine's better:

That said, before we move onto the next little improvement. I want to get rid of all
these print statements. They're super useful for debugging while I'm actively
thinking about the plugin, but in my usual, if something goes wrong, I'm not going to want to
pop open the debug shell for that.
I've been using sublime.status_message here and there. But that is quickly
overridden and isn't suited for letting my know that something went wrong in a visible
way. So instead, let's consider using either
sublime.error_message or
sublime.message_dialog for our purposes.
I don't think I need to spend the screen space here to repaste each of the code snippets so far
to tell you that all I did was search for each print and then replace them with
an appropriate call. If it was an error, error_message. If it felt like something I'd want to stop
my world for and call attention to via a pop up, message_dialog. If it was
something that was happening thats noteworthy but transient, status_message.
Speaking of code snippets though…
Escaping code ↩
In a way, this sort of thing is actually why I stuck with VSCode for as long as I did.
In addition to the autocomplete I replaced in the first post of this series, it also has
good support for vim motions and some basic vim-like commands. And so, for doing something
like taking a <pre> tag's contents and adding in <!----> to cover the indentation
whitespace and then make sure that the common HTML entities for < and friends are escaped
properly, I'd take some code snippet between pre tags, quickly swap to visual mode and expand
the selection out to the tag boundaries with shift+V vat and then scroll up to
my usual replacements like so:
If there's a < in the code snippet, or an & or similar, I'd run a replace for that before fixing up the whitespace indentation. This doesn't take much time, but it was satisfying that little itch in the back of your head that says: learn vim commands and get the dopamine from executing commands in visual mode!
In sublime, there's something that almost works for this built in from the HTML plugin:
import sublime_plugin
from html.entities import codepoint2name as cp2n
class EncodeHtmlEntities(sublime_plugin.TextCommand):
def run(self, edit, **args):
view = self.view
for sel in view.sel():
buf = []
for pt in range(sel.begin(), sel.end()):
ch = view.substr(pt)
ch_ord = ord(ch)
if not view.match_selector(pt, 'meta.tag - string, constant.character.entity') and \
ch_ord in cp2n and \
not (ch in ('"', "'") and
view.match_selector(pt, 'string')):
ch = '&%s;' % cp2n[ch_ord]
buf.append(ch)
view.replace(edit, sel, ''.join(buf))
I say almost works because if you're trying to run it on an HTML snippet then it behaves in a pretty interesting way:
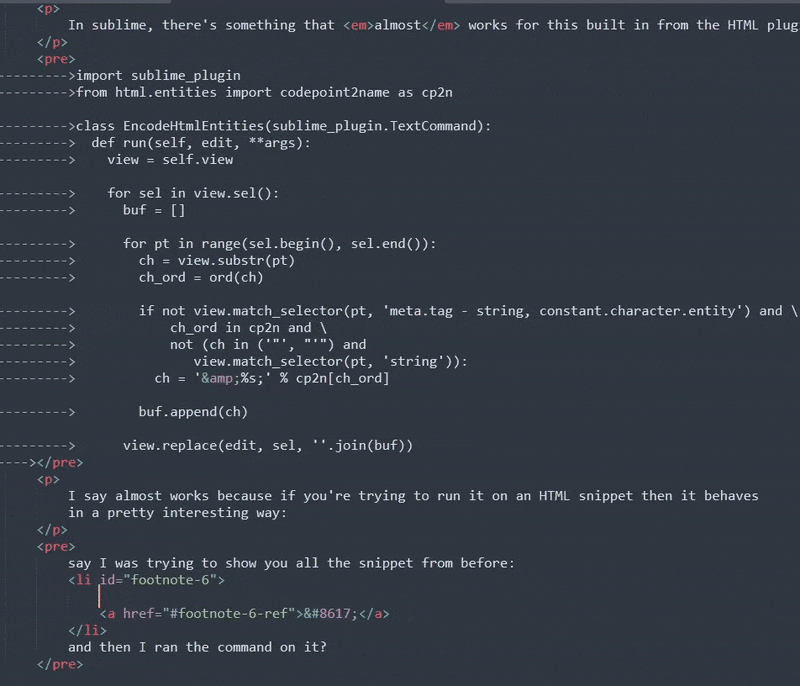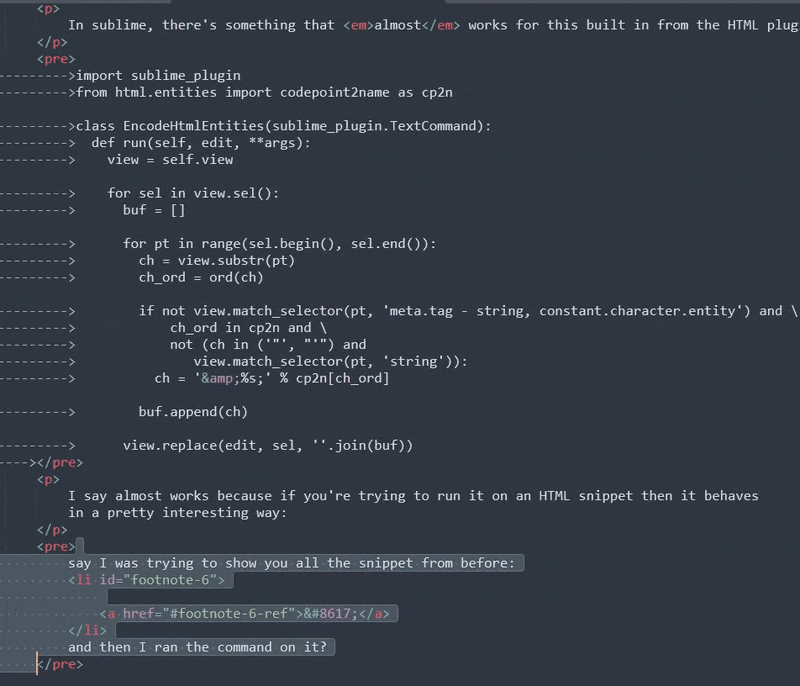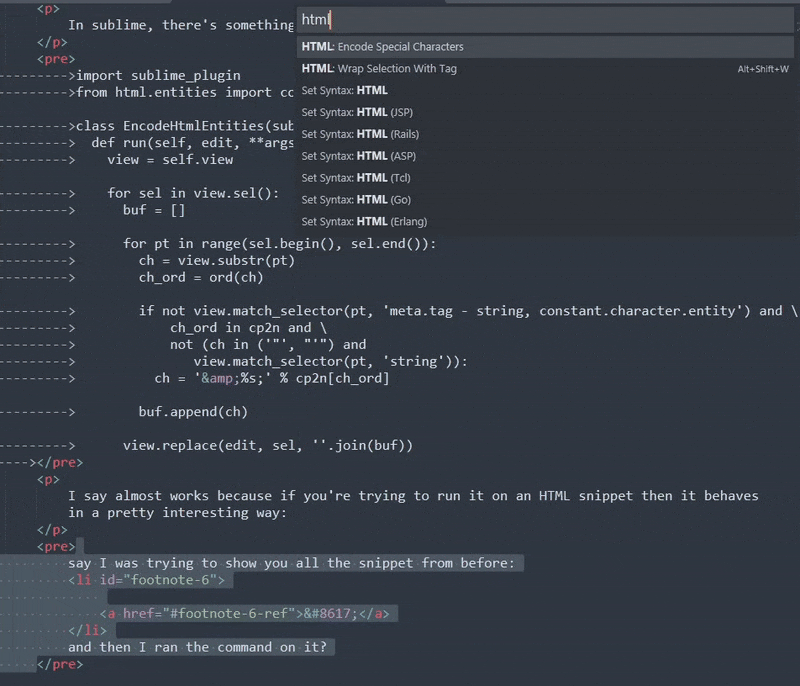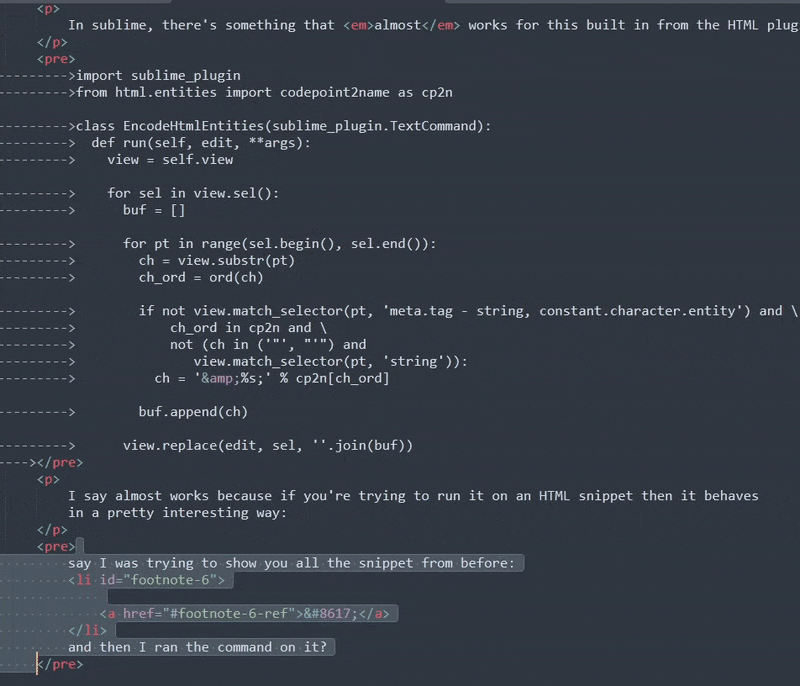
If you're saying to yourself: "okay, I assume he ran the command... why did nothing change?" Congrats, you're asking the same thing I did when I first discovered it!
My assumption here is that the intending context for when you'd be running the encode_html_entities
command is when you've got a full HTML file open and want to tell the whole thing (or selection)
to take any plain text strings intermixed with your HTML and escape only the text and leave any
tags you added for markup alone. That makes a lot of sense! But isn't what I need.
So let's see if we can figure out how to do this. My first question is if there's an easy way to tell that the current scope is a pre tag or not. Running ctrl+shift+alt+P gives the answer:
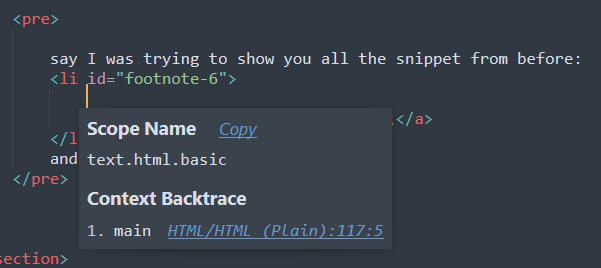
Not really. If you watch the gif above again, you can see the selection creeping out 7 because I'm pressing ctrl shift A each time. That knows how to expand...
so maybe we can learn something from that if we can pry open the source code and understand it.
Looking in the Default.sublime-keymap file:
…
{ "keys": ["ctrl+shift+a"], "command": "expand_selection", "args": {"to": "smart"} },
{ "keys": ["ctrl+shift+m"], "command": "expand_selection", "args": {"to": "brackets"} },
{ "keys": ["ctrl+m"], "command": "move_to", "args": {"to": "brackets"} },
{ "keys": ["ctrl+shift+a"], "command": "expand_selection", "args": {"to": "tag"}, "context":
[
{
"key": "selector",
"operator": "equal",
"operand": "(text.html, text.xml) - source", "match_all": true
}
]
},
…
We can see that there's both a regular "expand_selection" command, and one which takes precedence
when the context is within html files. It's neat to see to: tag here as part of
arguments. Since this fills me with a bit of hope that I might be able to potentially specify
a specific command here.
however, upon looking for a class named ExpandSelectionCommand or similar, I found
nothing in the Default plugin within sublime text. That said, I did find a reference
to view.expand_to_scope within the ToggleCommentCommand class:
class ToggleCommentCommand(sublime_plugin.TextCommand):
def remove_block_comment(self, view, edit, region):
scope = view.scope_name(region.begin())
if region.end() > region.begin() + 1:
end_scope = view.scope_name(region.end() - 1)
# Find the common scope prefix. This results in correct behavior in
# embedded-language situations.
scope = os.path.commonprefix([scope, end_scope])
index = scope.rfind(' comment.block.')
if index == -1:
return False
selector = scope[:index + len(' comment.block')]
whole_region = view.expand_to_scope(region.begin(), selector)
...
Which clued me into the fact that we've got a number of expansion related methods on the view itself we could maybe use. But if we want to do that, then we need to determine if the HTML plugin defined a scope that allows us to target the pre tag itself, or if we're stuck with something more brutish. Within the HTML.sublime-syntax file I can see:
variables:
html_text_content_tags: |-
(?xi: blockquote | cite | dd | dt | dl | div | figcaption | figure | hr
| li | ol | p | pre | ul ){{tag_name_break}}
And that's the only place that pre is mentioned. Looking in the un-official documentation from the community site:
At their core, syntax definitions are arrays of regular expressions paired with scope names. Sublime Text will try to match these patterns against a buffer's text and attach the corresponding scope name to all occurrences. These pairs of regular expressions and scope names are known as rules.
…
Syntax definitions from separate files can be combined, and they can be recursively applied too.
source
Oh boy. So basically, syntax is a bunch of regex. This sounds nightmarish to me since there's nothing that
really melts my brain faster than trying to read a lot of regular expressions and hoping that my mental
model somehow constructs the correct finite state machine the computer will execute. With this in mind,
the html_text_content_tags variable I saw before is actually just a declaration of a regex,
and that's included within another variable named html_block_tags which is then used in the
contexts section of the syntax file like so:
contexts:
tag:
- include: tag-html
…
tag-html:
- include: script-tag
- include: style-tag
- match: (</?)({{html_structure_tags}})
captures:
1: punctuation.definition.tag.begin.html
2: entity.name.tag.structure.any.html
push: structure-tag-content
- match: (</?)({{html_block_tags}})
captures:
1: punctuation.definition.tag.begin.html
2: entity.name.tag.block.any.html
push: block-any-tag-content
…
All of which is to say: a pre tag is a block html tag and that's all I can really get from the scope defined by the syntax. Dang.

Wait a minute though. What was that last bit that I read before?
Syntax definitions from separate files can be combined, and they can be recursively applied too.
Could I define my own little extension to get the pre tags to be their own scope?
When extending a syntax, the variables key is merged with the parent syntax. Variables with the same name will override previous values.
Variable substitution is performed after all variable values have been realized. Thus, an extending syntax may change a variable from a parent syntax, and all usage of the variable in the parent contexts will use the overridden value.
source
So... well, let's see if we can do this?

After an hour of fiddling, copying, crying, and trying to make sense of the documentation around this stuff. I got a syntax file defined and it appeared in the listing for selection:
But, if I tried to swap to it?
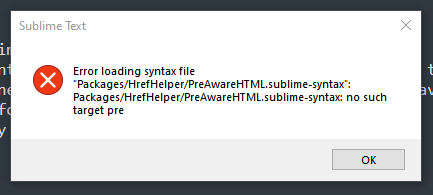
Hm. Remember how I just said that regex generally makes my brain melt? Well, turns out that beating my head against the wall to try to understand how to understand inheritance within a yaml file and how to properly define variables in a way that makes any degree of sense did, as expected, melt my brain. In the interest of not wasting my entire afternoon on this, I'm going to consider this approach a bit beyond me at the moment as stuff like this:
contexts:
main:
- include: html
tag:
- include: tag-html
- include: tag-other
- include: tag-incomplete
tag-html:
- include: pre-tag
- match: (</?)(?xi:pre)({{tag_name_break}})
captures:
1: punctuation.definition.tag.begin.html
2: entity.name.tag.structure.pre.html
push: pretag
pre-tag:
- match: (<)((?i:pre)){{tag_name_break}}
captures:
1: punctuation.definition.tag.begin.html
2: entity.name.tag.pre.html
push: pre
- match: (</)((?i:pre){{tag_name_break}})
captures:
1: punctuation.definition.tag.begin.html
2: entity.name.tag.pre.html
push: pre-close-tag-content
While, seemingly sensible with the ideas, just doesn't work for me yet. And I'm not clever enough or well versed in these particular internals to understand exactly why. With no ground to speak on, I think I'll shift back to where I'm more comfortable. Let's do this in code instead.
I know that punctuation.definition.tag.begin.html is where the pre tag is going to start.
We just don't know if we're at the correct tag or not. It seems like I should be able to
recursively expand from whatever point the cursor is at until I find one though. Let's write a little
debug command for this. First, a quick hello world:
import sublime
import sublime_plugin
class EscapeCodeSnippetCommand(sublime_plugin.TextCommand):
def run(self, edit):
html = "<strong>hi</strong>"
self.view.show_popup(html, max_width=512, max_height=512)

And then let's try out expanding.
selector = 'punctuation.definition.tag.begin.html'
whole_region = self.view.expand_to_scope(sel[0].begin(), selector)
html = f"<strong>hi {pre_tag_locations}</strong>"
self.view.show_popup(html, max_width=512, max_height=512)
And... this only ever shows something in the popup if I'm directly on the
start of a pre tag, it doesn't give me anything beyond None elsewhere,
which is odd. But, well, if this expand method on view isn't the same sort
of thing that those keymapped commands we saw is, then I guess we'll just
have to do this the old fashioned way! Screw your fancy expansion, we're loopin!
import sublime
import sublime_plugin
class EscapeCodeSnippetCommand(sublime_plugin.TextCommand):
def run(self, edit):
current_caret = self.view.sel()
pre_tag_locations = []
previous_region = None
regions_backwards = reversed(self.view.find_by_selector("text.html.basic meta.tag.block.any.html entity.name.tag.block.any.html"))
for region in regions_backwards:
# Keep track of the region in front of our current one
if previous_region is None:
previous_region = region
continue
tag = self.view.substr(region)
if not tag == "pre":
continue
if current_caret[0].begin() > region.end() and current_caret[0].begin() < previous_region.begin():
pre_tag_contents_region = sublime.Region(region.end(), previous_region.begin())
pre_tag_locations.append(pre_tag_contents_region)
self.view.sel().add(pre_tag_contents_region)
previous_region = region
if current_caret[0].begin() > region.end():
break
html = f"<strong>hi {pre_tag_locations}</strong>"
self.view.show_popup(html, max_width=512, max_height=512)
The self.view.sel().add(pre_tag_contents_region) is a sort of
debug thing for myself to confirm that yes, we're really doing it right. And,
if I run this from my editor inside of a random pre tag?
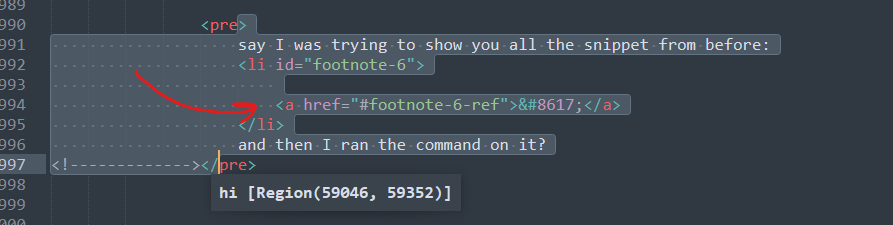
The little red arrow is where my cursor started before I ran the command. And so you can easily tell that it expanded correctly. Awesome. My edges are a bit messy here, since we're not seeing the / in the closing tag, and I suppose in general we'll need to figure out what level of indentation we're at, but I think we're pretty close to what we need. So let's add in some more code.
# We now have the regions where pre>[0] ends and [1]</pre starts.
# Escape the content inbetween for HTML:
modified_html = ""
for region_to_escape in pre_tag_locations:
unescaped = self.view.substr(region_to_escape)
escaped = html.escape(unescaped)
# then we need to handle whitespace indentation with HTML comments
ending_line = self.view.substr(self.view.line(sublime.Region(region_to_escape.end(), region_to_escape.end())))
# Tabs need to be converted to spaces so we can build the comment's dashes properly
tab_size = get_tab_size(self.view)
line_with_only_spaces = ending_line.expandtabs(tab_size)
character_space_for_comment = line_with_only_spaces.find("</pre>")
comment_dashes = "-" * (character_space_for_comment - 3)
comment_prefix = f"<!{comment_dashes}>"
for line in escaped.split("\n"):
modified_html += f"{comment_prefix}{line[len(comment_prefix):]}\n"
print(modified_html)
self.view.show_popup(html.escape(modified_html), max_width=512, max_height=512)
This is close but not quite right yet:
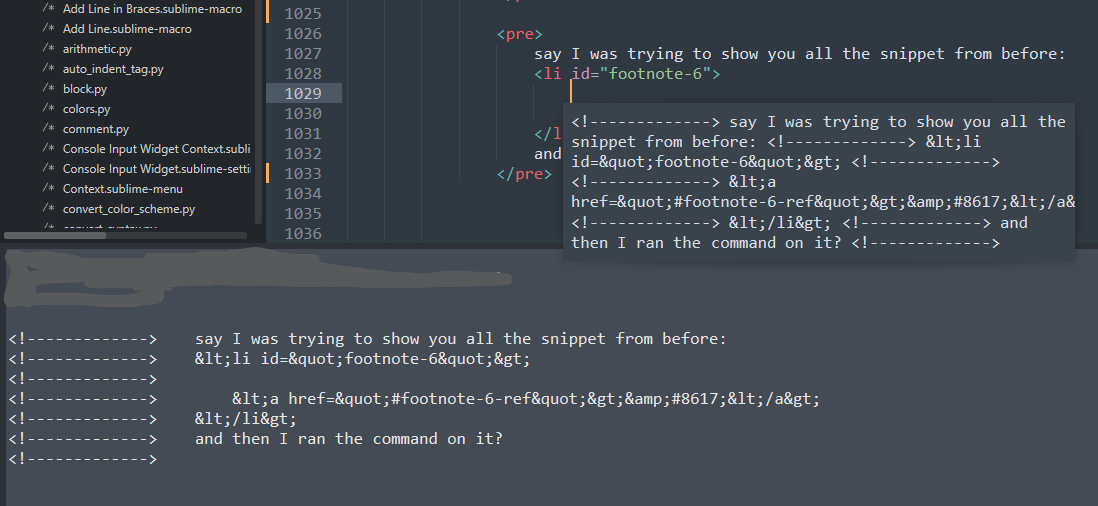
It's a bit easier to see the print here, but our indentation is
a bit off here since it's only indenting as far as the pre tag. When I escape the
code for the blog, I escape all the way to the > so that no extra whitespace
exists in order to keep the horizontal space as small as I can. The indentation
is correct for the level of the tag, but not for the body of said tag.
That said, that should be pretty easy to do! We know how long the tag is after all, and we can just expand it out, but one other thing I'd like to be careful of is if I haven't indented the code in the pre tag at all, we should pad things out! This will really make it possible to just run the command and call it a day even if I just dumped a bunch of code in and it's all over the place indentation wise.
That said, all those little edges make for a bit of gnarly code and I'm sure there's a better way to do it, but here's my first pass that's almost almost there:
character_space_for_comment = line_with_only_spaces.find("</pre>")
comment_dashes = "-" * (character_space_for_comment - 3)
comment_prefix = f"<!{comment_dashes}---->" # align > with ending > of <pre>
comment_prefix_endingline = f"<!{comment_dashes}>"
region_lines = self.view.lines(region_to_escape)
last_index = len(region_lines) - 1
for index, line_region in enumerate(region_lines):
if index == last_index:
comment_prefix = comment_prefix_endingline
padding_length = len(comment_prefix)
this_line = self.view.substr(self.view.line(line_region))
this_line_notabs = this_line.expandtabs(tab_size)
# Ensure that even if there's not enough space, we get some
space_at_start = 0
for c in this_line_notabs:
if c.isspace():
space_at_start += 1
else:
break
if space_at_start < padding_length:
padding = " " * (padding_length - space_at_start)
this_line_notabs = f"{padding}{this_line_notabs}"
escaped = html.escape(this_line_notabs[len(comment_prefix):])
new_line = f"{comment_prefix}{escaped}\n"
modified_html += new_line
Like I said, this is almost there, the problem is, as you can see, my usage of
the self.view.line method:
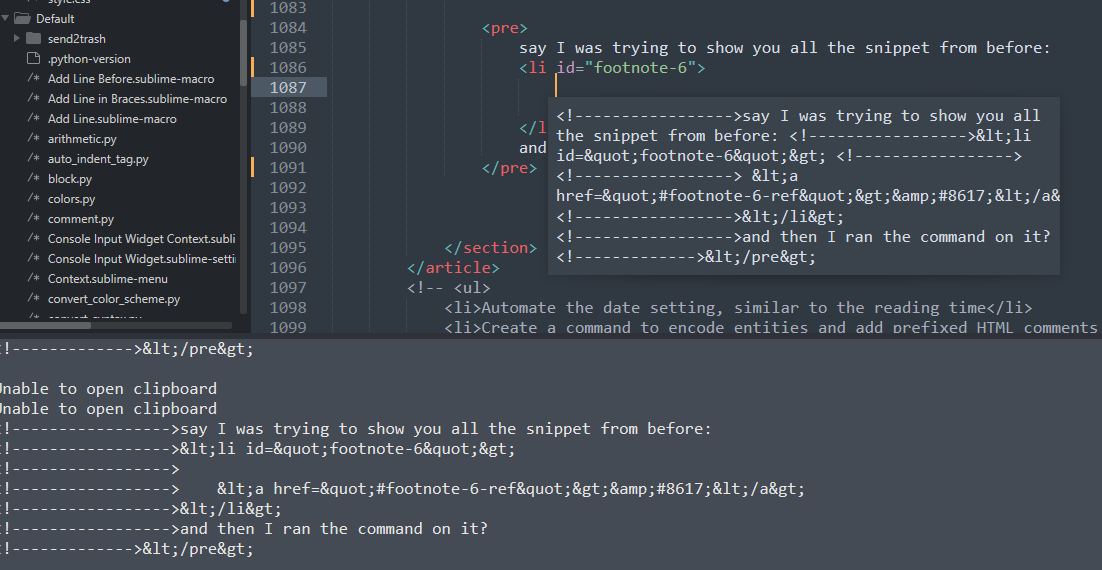
Unlike the previous code snippet, which only used the boundaries of the region expanded up until the pre tags, this one uses the lines helper to fetch each line overlapping with said region. That's great for most of the lines, but not the last one. So, we'll just be a bit cheeky here instead of getting complicated:
if index == last_index:
modified_html += comment_prefix
else:
modified_html += new_line
And then?
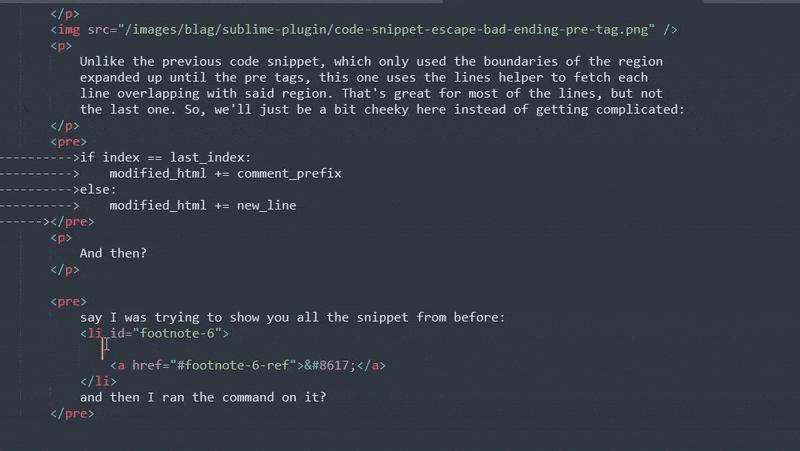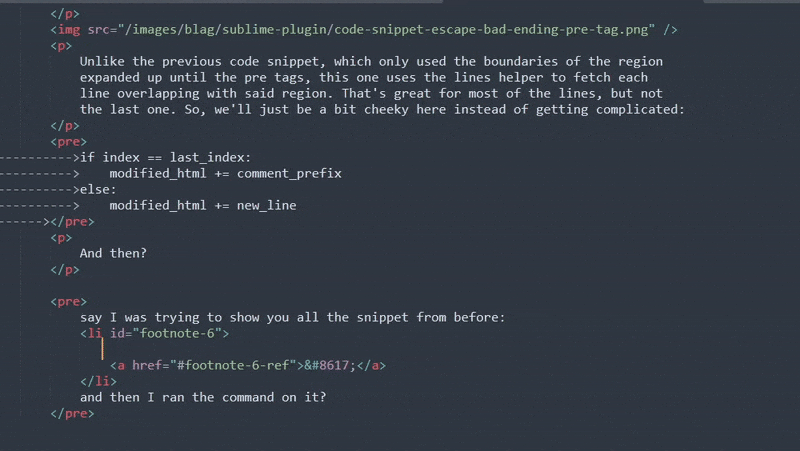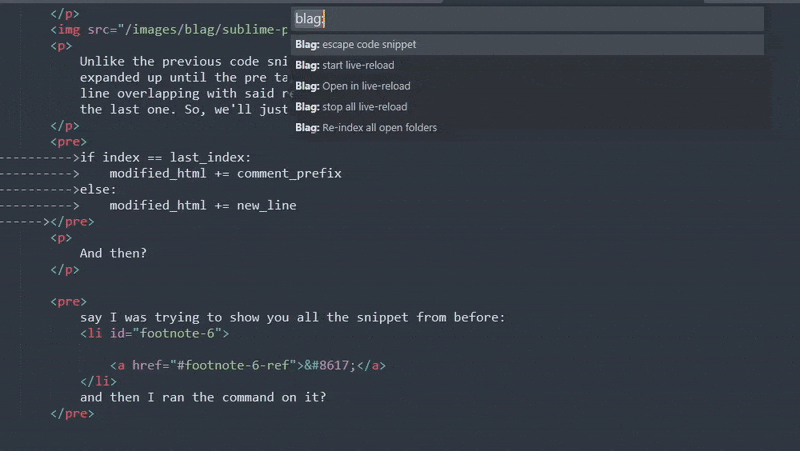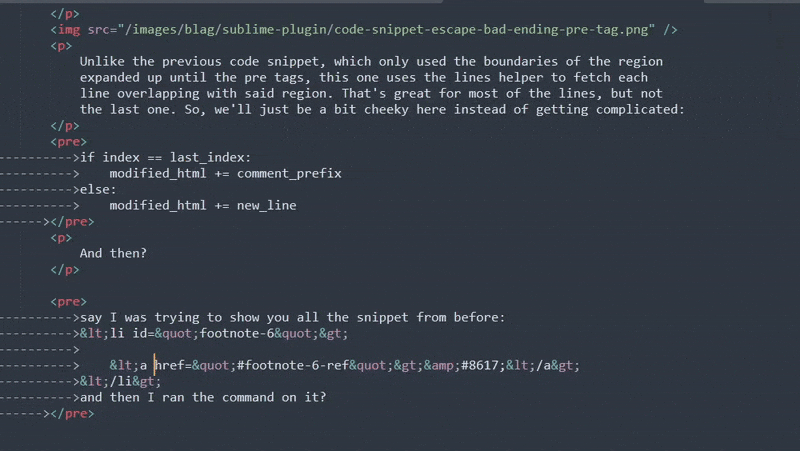
Escaping? Check. Didn't eat away at the content? Check! It's always nice when something works after a hard sunday afternoon's work.

RSS Snippets ↩
While the subject of my HTML snippets was covered quite heavily in the previous entry of this series. I don't just manage HTML for this blog. There is also a handy dandy RSS feed for the blog posts. This XML file is one which I edit, and more-often-than-not screw up in some way.
Thankfully we have validator websites, but I think it'll be better if I just use a snippet to help me set my dang dates right and avoid nonsense from happening without needing an internet connection. The main thing that trips me up, is the timestamp format and making sure that I write it in the current timezone. A typical RSS feed item looks like this:
<item>
<title>Dynamic snippets in sublime text</title>
<link>https://peetseater.space/blag/2025-06-21-sublimetext-blogging-customizations.html</link>
<guid>https://peetseater.space/blag/2025-06-21-sublimetext-blogging-customizations.html</guid>
<pubDate>Sun, 22 Jun 2025 02:47:00 GMT</pubDate>
<description>
![CDATA[
Continuing my adventures in sublimetext plugins, I figured out how to dynamically
insert content based on the current file's context into a snippet! I also made
a few other neat features for me to use while I blog!
]]
</description>
</item>
As we saw last time, if you want to write everything yourself, you can just use sublimetext's standard snippet methods. But if you want dynamically generated values in the output? You've gotta create the python snippet yourself. So, we'll be extending our view listener we made before. The little pattern I established last time was creating the snippet in the class init.
class DynamicSnippetsViewEventListener(sublime_plugin.ViewEventListener):
def __init__(self, view):
self.view = view
self.footnote_snippet = inspect.cleandoc("""
<li id="footnote-{0}">
$0
<a href="#footnote-{0}-ref">↩</a>
</li>
""")
…
And then creating helpers to construct the snippet itself for sublime
def footnote_completion(self):
new_snippet = self.footnote_snippet.format(f"{self.number_of_footnotes_in_file + 1}")
return sublime.CompletionItem(
"blag_footnote",
annotation = "A footnote for the bottom of the page",
completion = new_snippet,
completion_format = sublime.COMPLETION_FORMAT_SNIPPET,
kind=sublime.KIND_SNIPPET
)
And then returning them as needed:
def on_query_completions(self, prefix, locations):
for point in locations:
in_html_scope = self.view.match_selector(point, "text.html.basic")
if in_html_scope is False:
return None
if "blag" not in prefix:
return None
self.calculate_footnote_count()
self.calculate_section_count()
prefilled_snippets = [
self.footnote_completion(),
self.footnote_ref_completion(),
self.new_section_completion()
]
return sublime.CompletionList(prefilled_snippets)
Looking at this last snippet, we can spot a bit of a snag. Our dynamic snippets helper is only currently caring about HTML scopes. Unsurprisingly, an XML file has a different scope:
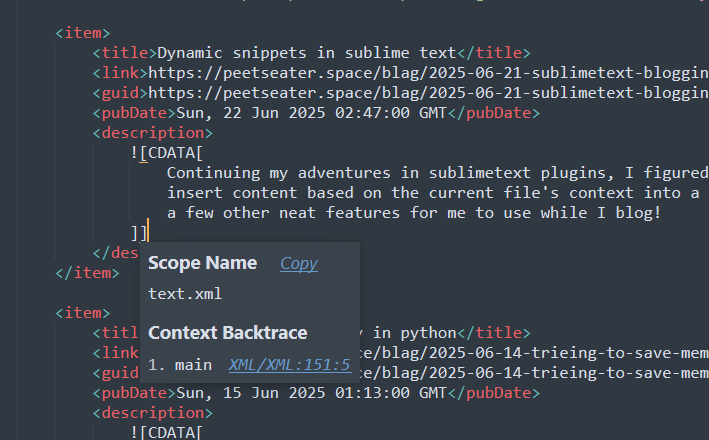
So, I can either created a separate class for the XML related snippets, or I could tweak
our on_query_completions method to pull out the appropriate completions
based on the results of the match selector. Decisions, decisions. I think that future me
will appreciate a clear dilineation, and so let's rename DynamicSnippetsViewEventListener
to DynamicHTMLSnippets and make an XML one.
class DynamicXmlSnippets(sublime_plugin.ViewEventListener):
def __init__(self, view):
self.view = view
self.feeditem_snipet = inspect.cleandoc("""
<item>
<title>$1</title>
<link>$2</link>
<guid>$2</guid>
<pubDate>{0}</pubDate>
<description>
![CDATA[
$0
]]
</description>
</item>
""")
Just like the HTML one, I'm going to declare the snippet once in the class.
One Noteworthy thing here are that my link and guid are just the canonical url
for the website, so they both get $2 so it will be fill in both
as I type. The only other bit is that we've got the sublime text replacements
reflected with the dollar sign prefixed numbers, and then the dynamic part ready
to be formatted by python with {0}.
from email.utils import formatdate
...
def new_feed_item_completion(self):
# Current time in RFC 822 format for RSS
todays_date_in_gmt = formatdate(timeval=None, localtime=False, usegmt=True)
new_snippet = self.feeditem_snipet.format(f"{todays_date_in_gmt}")
return sublime.CompletionItem(
"blag_xml_item",
annotation = "a new rss item",
completion = new_snippet,
completion_format = sublime.COMPLETION_FORMAT_SNIPPET,
kind=sublime.KIND_SNIPPET
)
a helper method to perform the actual dynamic inclusion of the date and return the sublime text helper isn't anything new. The only fun bit is that I didn't know about formatedate until I started searching around for RFC 822 python code and stumbled across it. So that's always nice to put in the back pocket.
Lastly, the query completions method sublime will use to fetch back out anything we have to offer:
def on_query_completions(self, prefix, locations):
for point in locations:
in_xml_scope = self.view.match_selector(point, "text.xml")
if in_xml_scope is False:
return None
if "blag" not in prefix:
return None
prefilled_snippets = [
self.new_feed_item_completion()
]
return sublime.CompletionList(prefilled_snippets)
It's really quite similar to the other, if I was doing this for a few more file types I'd probably consider creating a generic template method type class to extend from. But since we're not nearly at that point, I think copying and pasting is just fine for the time being.
And the moment of truth, does it work?
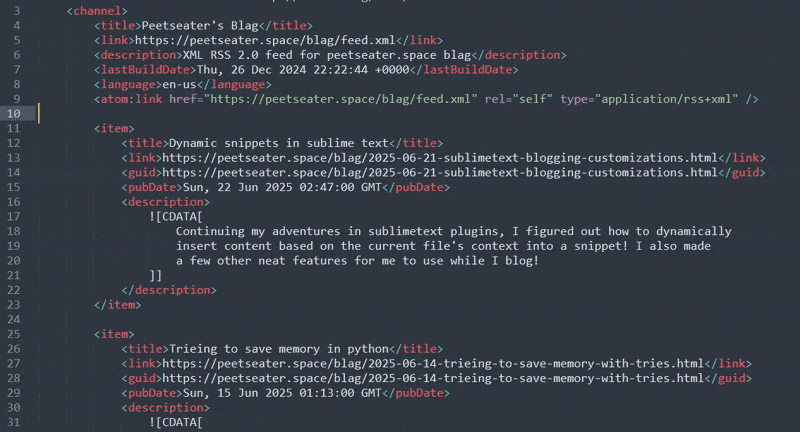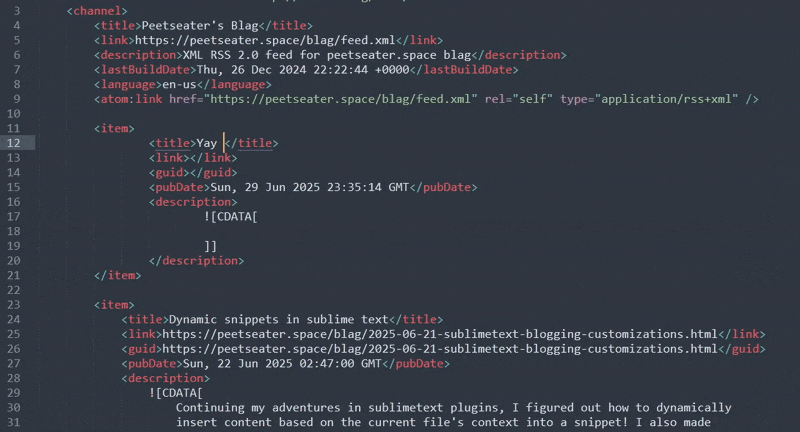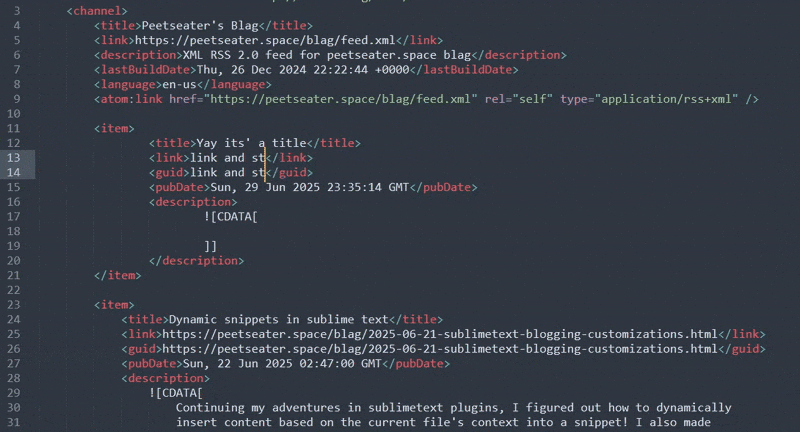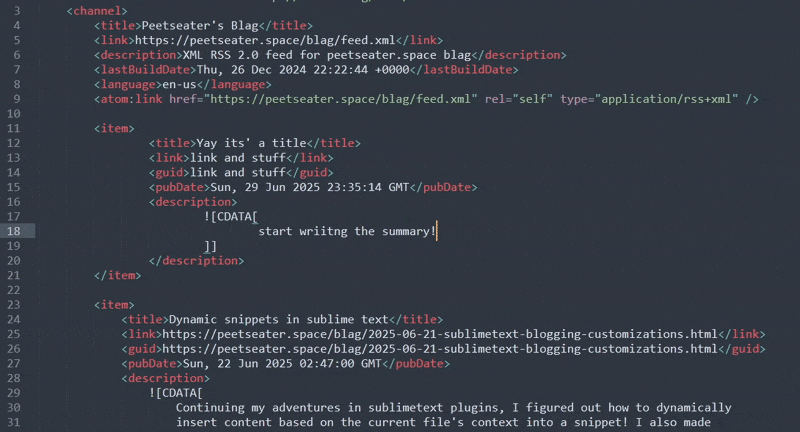
Like a charm! My snippets that I'm using for the web paths aren't active in the XML context though, which means it's a bit harder than neccesarily to get the full path to the blog post I just wrote. Looking back at that completion helper:
class IndexedFilesCompletionsViewEventListener(sublime_plugin.ViewEventListener):
def on_query_completions(self, prefix, locations):
# If someone is using multicursors, ensure all cursors
# are within the correct context before we offer ourselves
# as an option
for point in locations:
in_html_scope = self.view.match_selector(point, "text.html.basic")
if in_html_scope is False:
return None
in_meta = self.view.match_selector(point, "meta.string.html")
if in_meta is False:
return None
in_href = self.view.match_selector(point, "meta.attribute-with-value.href.html")
if in_href is False:
return None
return sublime.CompletionList(href_files)
It wouldn't be too hard to do one little tweak... adding in something like
in_xml_scope = self.view.match_selector(point, "text.xml")
if in_xml_scope:
return sublime.CompletionList(href_files)
but the only problem with that is that now those autocompletes take up a ton of space in any context of the XML:
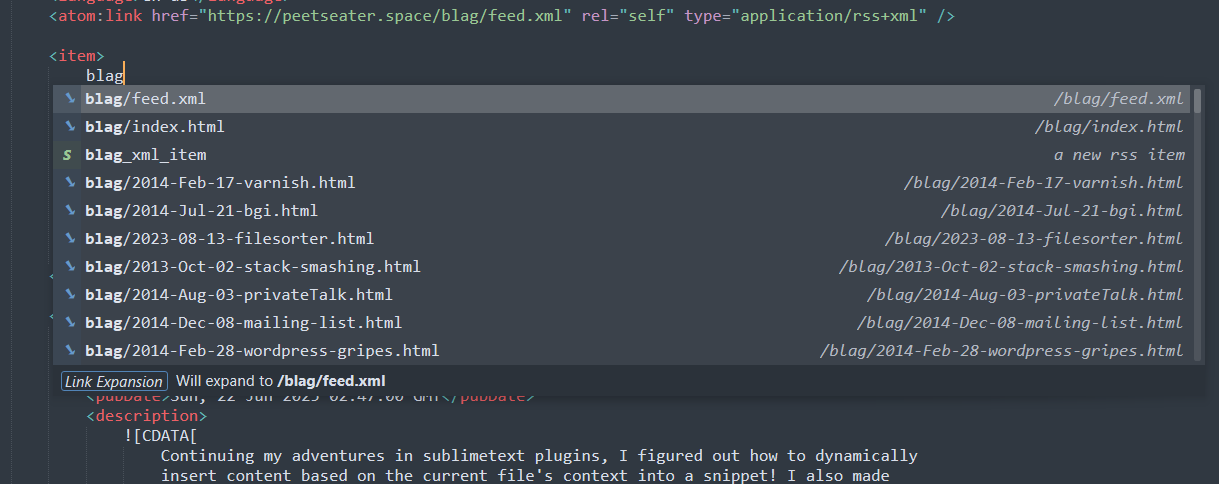
I could maybe check the prefix as being the website name. But typing out https://peetseater.space
then pressing tab will result in only space being passed to the on_query_completions
method in the prefix variable. Which, sorta could work, except for the fact that it'll do this when you
complete it:
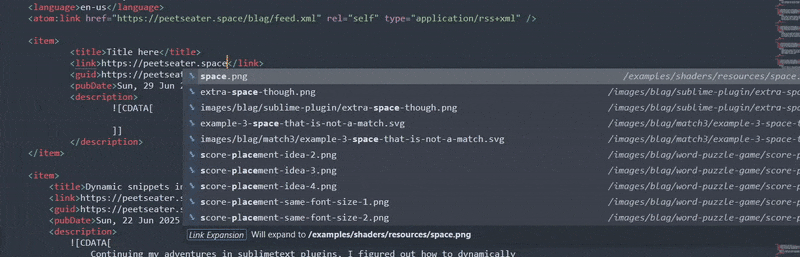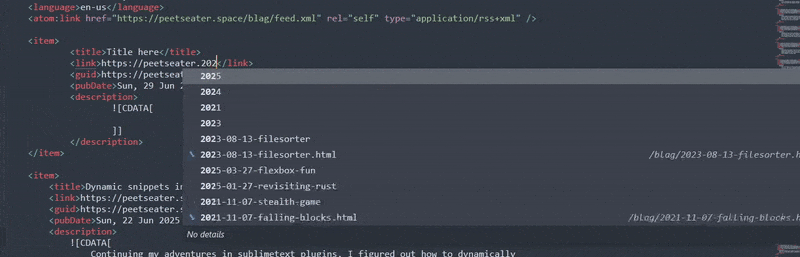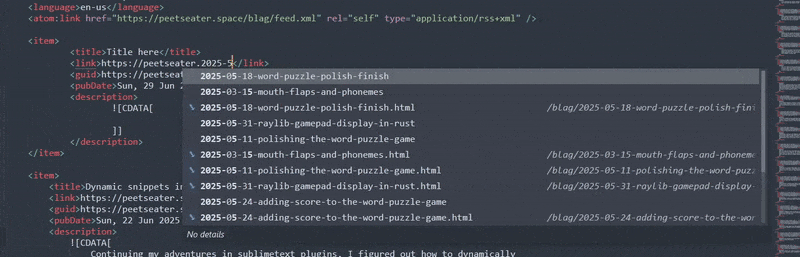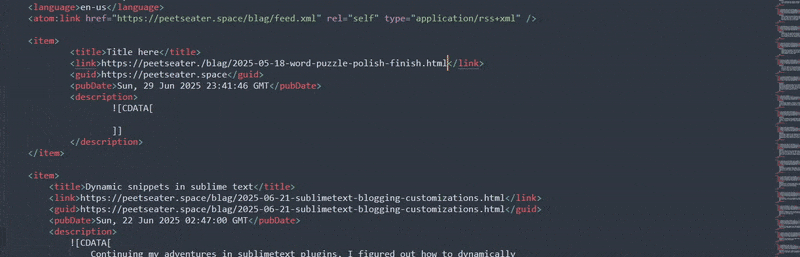
And that's not putting aside the fact that you have to backspace to be able to search for the right file,
it screws up the domain name, and the very very important bit: you can only tab compete if you're not using
tab to jump between parts of the snippet! Pressing tab when you're in snippet-creation mode doesn't wake up
the autocomplete, it jumps you to the next $number placeholder. so, for the time being,
I think we'll give up on using our indexed files for this XML autocomplete for now.
Wrapping up ↩
Well, this felt like a slightly shorter post. Though looking at the scrollbar, that maybe isn't actually the case. It felt like we tackled a few BIG things rather than a bunch of small ones like last time.
I didn't use VSCode to write this post at all, well, besides booting it up to grab screenshots and such for comparison, and was pretty happy with the experience. From the moment I got the code snippet helper working, it became way way faster to include each of those in. I think there's still a few things I could probably do, such as add in some autocompletes for common HTML entities or maybe look into using livereload's API directly in order to avoid having to hack around sublime's lack of file watch.
But, honestly? I think we'll take a break from some of these editor tweaks! Why? Because I had some really good ideas on a plane ride this past week for some projects! Specifically, and hey, no stealing my ideas, but:
- A variant on the Trie puzzle game I made before
- Investigating RDF and how one might use it to make a site search
- Raylib keyboard overlay to capture keystrokes for better blog gifs and such
- Adding sqlite to my file deduper rust util
- Whatever things happen when I get my hands on a new computer and start using PopOS
No commitments from me on which one of these you might see show up here. But we'll see where the future months take us! For now, I'm going to finish up the last bit of listening I had on the nice music I was listening to whilst programming all this stuff!