What is dupdb? ↩
I like art, and unfortunately, "the algorithm", and especially twitter and other social media platforms, often never show you the same post ever again unless you explicitly try to seek it out. Because of this, it's not uncommon for artists to repost work multiple times. Which is great for them in trying to garner likes and such. However, for someone in love with their works, trying to preserve the art for future enjoyment gets tricky. Filenames aren't the same, you'd have to remember every picture you ever download, and well… I'm, bad at that.
According to my git log, On March 29th around 11pm I decided to finally do something about that. It's unfortunate that windows explorer doesn't have anything built in for this, but we have the power of the computer on our side! 1 So, I read through the documentation on notify-rust and notify and then got to work deciding how I wanted to keep track of things.
To keep things easy, I decided to make a dot folder with a .dat file in it. Dat files are just a generic extension for any sort of binary data that an application wants to store, and I feel better using that rather than having an extensionless file for some reason. As I tweaked and tested during development, being able to wipe out the folder and start fresh was really nice. The code to initialize the database is pretty simple. Though, for the purposes of this blog post, I kind of wonder if I should go over the tweaking and modification of each piece, or just give you the final cut and explain it.
Looking at my git log, I wrapped up the project at 10pm the day after I started, so it's not like this was a mountain of work and some long arduous journey. So, I think I'll give you a rundown of the API 2 and then drop into each method with a brief explanation so that you've got an idea of where we're starting, so that when we get into the journey itself to tweak things, you can more easily follow how we'll get to where I want us to be.
fn dupdb_initialize_hidden_folder() -> bool fn dupdb_reset_database_from_existing_files( path: PathBuf, duplicate_database: &mut DuplicateDatabase ) fn dupdb_database_path() -> PathBuf fn dupdb_save_to_file(duplicate_database: &DuplicateDatabase) fn dupdb_database_load_to_memory() -> DuplicateDatabase fn dupdb_watch_forever(watch_folder_path: &Path, duplicate_database: &mut DuplicateDatabase) fn dupdb_update_hashes_for(paths: Vec<PathBuf>, duplicate_database: &mut DuplicateDatabase) fn dupdb_notifications_send(duplicate_paths: Vec<PathBuf>) fn dupdb_debug_file_path_print(path: String, duplicate_database: &DuplicateDatabase)
I'll go into detail in a sec, though I think the names here are decently indicative
of what's going on. But as you can see by the signatures, we're primarily concerned
with the management of the DuplicateDatabase type. This is a pretty
simple struct:
#[derive(Serialize, Deserialize, Debug)]
struct DuplicateDatabase {
hash_to_files: HashMap<u64, Vec<String>>,
files_to_hash: HashMap<String, u64>
}
impl DuplicateDatabase {
fn add(&mut self, hash: u64, full_file_path: String)
fn contains_duplicate_for_hash(&self, hash: u64) -> bool
fn remove(&mut self, full_file_path: String)
fn debug_key(&self, full_file_path: String)
}
The data we're tracking is just a two way map between hashes and file paths. You can probably guess how this all works under the hood: essentially we treat the struct as a sort of Set, with some basic add/removal methods and a contains check. This is used by those other functions I listed already in conjunction with a file watch and hashing function to produce what we need to detect duplicates. The main method is pretty small which sets all this up:
fn main() {
let folder_name = env::args().nth(1).unwrap_or("./test".to_string());
let folder_to_watch = Path::new(&folder_name);
// Initialize .dupdb in folder.
let needs_reset = dupdb_initialize_hidden_folder();
// Load database
let mut database = dupdb_database_load_to_memory();
if needs_reset {
dupdb_reset_database_from_existing_files(folder_to_watch.to_path_buf(), &mut database);
dupdb_save_to_file(&database);
println!("Initial database saved to {:?}", folder_to_watch);
}
// if 2 arguments are sent, then second is key to look up for debugging
// because I'm getting a lot of conflicts on files that aren't actually duplicates.
if let Some(file_path) = env::args().nth(2) {
dupdb_debug_file_path_print(file_path, &database);
return;
}
dupdb_watch_forever(folder_to_watch, &mut database);
}
When I'm just doing cargo run while iterating on it, I don't bother
passing a specific folder and instead use a test directory that I can easily
clone files in to trigger it. In the same way, if I delete the .dupdb folder where
the data is stored, then the needs_reset section will fire and the
existing data will be zeroed out. After that, there's really two options here.
I either called the program like this
./duplicate-file-monitor dir file
Or like this
./duplicate-file-monitor dir
Where the second option is how I run it "in production" to have it do my daily
use of it. And the first is what I do if I want to check on, well, exactly what
my comment says. On weird cases where a dup is reported but it wasn't actually
a dupe. Whether or not something is considered a duplicate is a function of the
hashing algorithm I'm using. Which, we can see in the details of the dupdb_update_hashes_for
method:
fn dupdb_update_hashes_for(paths: Vec<PathBuf>, duplicate_database: &mut DuplicateDatabase) {
let mut duplicates_in_aggregate = Vec::new();
let mut db_dirty = false;
for path in paths.iter() {
let absolute_path = path::absolute(path)
.expect("Unable to get absolute path for file to hash").to_str()
.expect("Unexpected file name containining non utf 8 characters found").to_string();
if !path.exists() {
duplicate_database.remove(absolute_path);
db_dirty = true;
} else {
// We don't care about directories, only files we can hash.
if path.is_dir() {
continue;
}
match fs::read(path) {
Ok(bytes) => {
let hash = seahash::hash(&bytes);
duplicate_database.add(hash, absolute_path.clone());
if duplicate_database.contains_duplicate_for_hash(hash) {
// send notification
println!("Duplicate detected {:?} {:?}", absolute_path, hash);
duplicates_in_aggregate.push(path.clone());
duplicate_database.debug_key(absolute_path.clone());
db_dirty = true;
}
},
Err(error) => {
eprintln!("Unexpected failure to read path: {:?} {:?}", error, path);
}
}
}
};
if db_dirty {
if !duplicates_in_aggregate.is_empty() {
dupdb_notifications_send(duplicates_in_aggregate);
}
dupdb_save_to_file(duplicate_database);
}
}
The input to the method, paths is a list of paths that need to be hashed. This
can come from either a reset from dupdb_reset_database_from_existing_files or
from a list of files that have been changed according to the filewatch that's setup by the
dupdb_watch_forever function. A file watch might report that a file has been
deleted, in which case it's normal and expected. So the path.exists()
check lets us handle that.
The more common case of course is that of a regular file. Then we do the core functionality
of the program via seahash::hash
and a quick call to duplicate_database.contains_duplicate_for_hash. These two
hash the file into a simple number and then our struct tells us if its double mapping has an
extra item in the list or not:
fn contains_duplicate_for_hash(&self, hash: u64) -> bool {
let contains_hash = self.hash_to_files.contains_key(&hash);
if !contains_hash {
return false;
}
if let Some(files) = self.hash_to_files.get(&hash) {
return files.iter().count() > 1
}
return false;
}
We should always have a hash in the dupdb at this point, since we add the hash
to the database struct first. So our contains method is really just focused on telling us
if we've got more than one or not. Simple. The last thing the large chunk of code I shared
above does is emit the notifications via dupdb_notifications_send.
I suppose, thinking back on it a bit, I could have had the method return the list of
duplicates, but I don't know. The name dupdb_update_hashes_for doesn't
really sound like it should return that, though, nor does it sound like it
should be emitting anything either. I guess if I wanted to lock shared state into one
place, then I'd have made it possible to dump the duplicates into the
duplicate_database argument. But, well, we can think about that later.
If it makes sense.
Anyway, to wrap up the tail end of the functionality walkthrough. Sending the notifications
is done through the notify-rust library like I said before. The dupdb_notifications_send
function takes care of constructing the message, an image to display, and shuffling it along out
the door:
fn dupdb_notifications_send(duplicate_paths: Vec<PathBuf>) {
if duplicate_paths.is_empty() {
return;
}
let first_image = path::absolute(duplicate_paths[0].clone())
.expect("Unable to get absolute path for file to hash").to_str()
.expect("Unexpected file name containining non utf 8 characters found").to_string();
let mut listing = String::new();
for dup in duplicate_paths.iter() {
if let Some(name) = dup.file_name() {
listing.push_str("\n • ");
listing.push_str(&name.to_string_lossy());
};
}
let handle = Notification::new().summary("Duplicate Files detected")
.appname(APPNAME)
.body(
&format!("Duplicate files were saved to the watched directory by dupdb.{listing}"
).to_string())
.image_path(&first_image) // Shouldn't happen becuase we already grabbed the abs before
.finalize()
.show();
handle.expect("Could not send notification for duplicates");
}
When I originally put this together, I was so excited about "ask the user to do something" part of the docs. Since I figured that I could easily construct a way to have the dup cleaned up right then and there if I decided. However… if you drop open the platform differences section of the docs you can see:
| method | XDG | macOS | windows |
|---|---|---|---|
fn wait_for_action(...) | ✔︎ | ❌ | ❌ |
fn close(...) | ✔︎ | ❌ | ❌ |
fn on_close(...) | ✔︎ | ❌ | ❌ |
fn update(...) | ✔︎ | ❌ | ❌ |
fn id(...) | ✔︎ | ❌ | ❌ |
Notice how wait_for_action has a big X on it? Well, for macOS and windows at least.
Sadly, I'm on windows! So, no cool handy action on dupe for me. Obviously, I could make
it remove the dup on its own, but, given that hash conflicts can and do occur, and sometimes I
actually do mean to copy a file twice, I don't want to automatically clear out a file with no
human oversight. So, instead, we just pop up the notification like so
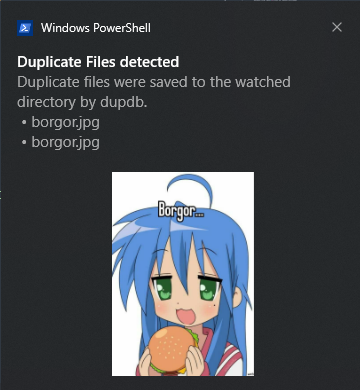
No fancy buttons or anything to let a user choose what to do.
Bummer huh? That said, just because we can't use a feature doesn't mean we can't do something
kind of cool and fun! Or well, re-use something cool and fun! Back in
my blog post about a nav update tool, I created a little helper named RecursiveDirIterator.
I am happy to report that I was able to re-use it for this project!
fn dupdb_reset_database_from_existing_files(
path: PathBuf, duplicate_database: &mut DuplicateDatabase
) {
println!("Reseting database according to files within {:?}", path);
let entries = RecursiveDirIterator::new(&path)
.expect("Could not load path to reindex database");
let paths = entries
.filter(|dir_entry| dir_entry.path().extension().is_some()) // Remove dirs, keep files.
.map(|file| file.path())
.collect();
dupdb_update_hashes_for(paths, duplicate_database);
}
I really enjoy treating the file system as if it were a list, responding to my query for all the data underneath the path we started at. I went over it in that blog post I linked, but basically the core of it is a double ended list
#[derive(Debug)]
pub struct RecursiveDirIterator {
q: VecDeque<fs::DirEntry>,
}
Which we populate lazily whenever a user constructs the struct, or when they call next
impl Iterator for RecursiveDirIterator {
type Item = fs::DirEntry;
fn next(&mut self) -> Option<fs::DirEntry> {
let n = self.q.pop_front();
match n {
None => n,
Some(dir_entry) => {
let path = dir_entry.path();
if path.is_dir() {
if let Ok(entries) = fs::read_dir(&path) {
for entry in entries.flatten() {
self.q.push_back(entry);
}
} else {
eprintln!("Could not read entry in path {}", path.display());
}
}
Some(dir_entry)
}
}
}
}
It's a simple thing. First in, first out, and so we treat the directories as a tree and
traverse it breadth first search. Allowing the user to look at both directoy and
files in one go. Which is handy! But also, directories are useless for our dedupper, and
so, that .filter that we had in the previous code snippet takes care of that.
I think there's only two other things that are left to mention for you to understand the
core of the program.
First, the file watch that's keeping an eye on the directory that we've told the program about via its cli arguments. I'm using the notify_debouncer_full crate to do this. The "full" version of the crate (as oppose to just plain notify) handles debouncing in a way that helps cut back on getting a bunch of notifications for stuff that doesn't matter. Windows seems to like to update the metadata of a file somewhat often, and using just plain notify was getting me dup updates for something "atomic" feeling like cutting a file from one place to the next. 3
The number of things potentially being reported on is pretty easy to tell from the Enum that the library exposes:
fn dupdb_watch_forever(
watch_folder_path: &Path,
duplicate_database: &mut DuplicateDatabase
) {
let (tx, rx) = mpsc::channel();
let mut debouncer = new_debouncer(Duration::from_secs(1), None, tx)
.expect("Failed to configure debouncer");
debouncer.watch(watch_folder_path, RecursiveMode::Recursive)
.expect("Failed to begin file watch");
for result in rx {
match result {
Ok(debounced_events) => {
let paths: Vec<PathBuf> = debounced_events.into_iter().filter_map(|event| {
match event.kind {
EventKind::Remove(_) => Some(event.paths.clone()),
EventKind::Create(_) => Some(event.paths.clone()),
EventKind::Modify(_) => Some(event.paths.clone()),
EventKind::Any => Some(event.paths.clone()),
EventKind::Access(_) => None,
EventKind::Other => None,
}
}).flatten().collect();
dupdb_update_hashes_for(paths, duplicate_database);
},
Err(error) => eprintln!("Watch error: {:?}", error),
}
}
}
The "Access" event was often the source of what felt like a duplicate thing
during my testing with just plain notify. The events are aggregated in different
ways from the underlying library it seems, and its very platform dependent,
so, your mileage might vary here as well. But, basically, if a file was actually
changed in some way, then we can produce the path to be hashed and handled
by the code I've gone over already in dupdb_update_hashes_for.
The only other thing of note here is that the debouncing is 1s, so if I save
an image to a folder and it was a duplicate, it will take at least 1 second to
be detected. The other parameter, None, sets the "tick rate",
which is basically how often the library is going to check (within the timeout of 1s)
for an update. By default, this is 25% of the timeout, and so every 250ms the
system is querying the file system for updates, and if it finds any, it holds
out for 1 second before emitting a list of paths that have been changed. Or well,
a list of events that need to be matched against!
The last thing I want to mention, before we start in on modifying this tool of ours, is that we've got file detection, we've got hash calculation, we've got updating the struct with a mapping that lets us know when to send a windows notification. But what we don't have, is persitent data yet. That's where a pair of twin functions come in:
fn dupdb_save_to_file(duplicate_database: &DuplicateDatabase) {
let folder = dupdb_database_path();
let mut index_file = folder.clone();
index_file.push(NAME_OF_HASH_FILE);
let mut file = File::options()
.read(true).write(true)
.truncate(true).open(index_file)
.expect("Could not open index file");
let mut buf = Vec::new();
duplicate_database.serialize(&mut Serializer::new(&mut buf))
.expect("Could not serialize empty DuplicateDatabase");
file.write_all(&buf)
.expect("Did not write bytes to file");
}
fn dupdb_database_load_to_memory() -> DuplicateDatabase {
let folder = dupdb_database_path();
let mut index_file = folder.clone();
index_file.push(NAME_OF_HASH_FILE);
let handle = File::open(index_file)
.expect("Could not open index file");
rmp_serde::from_read(handle)
.expect("Could not deserialize DuplicateDatabase")
}
Saving and loading are both handled by the handy dandy serde crate, or, well, specifically that and rmp_serde which handles MessagePack encoded data. The msgpack-rust README file on github explains it a bit, but basically, it's like a useful binary JSON-ish format. It's actually almost readable as a plain .txt file, which made it useful for debugging and confirming that things were going in the right direction. Also, I sort of just wanted to try out using serde for fun at the time.
There's not a ton to say about these two methods. Serde does the hard part, and instead,
we just annotate the struct with #[derive(Serialize, Deserialize, Debug)] and let the
compiler spend some cycles on it. Very convenient. As you can see, I do rewrite the entire
file on each save, but since we've got the debounce and we aggregate the hash updates and such, I have
yet to accidently corrupt the stored map.
So! We've got a perfectly working program. Let's arbitrarily decide to "improve" it and see where we land! 4
How to use sqlite and rust? ↩
We could just start replacing the guts of each function with calls to the database. But, I think before we do that I should make sure I've got a good handle on actually using SQLite first. I think the last time I used it was as an embedded database for testing.
That didn't last long, because while the idea of being able to spin up a SQLite db on the disk for integration testing that exercised my database code was seemingly good, the fact that I was using MySQL for the "real" database and the alledged interactibility between MySQL and SQLite's querying language should have let me write the same queries for the data, that wasn't true in practice. I specifically remember running into annoying bothersome things where I'd write a database migration in flyway, get it to happily work with MySQL, and then the same thing would fail because of some arbitrary thing that SQLite couldn't handle properly.
Sorry. This isn't a comparison of how to do your testing against live databases. There is no My in our SQL here! We're using sqlite for everything, so the problems I had before shouldn't apply! So. Let's define our database schema, write a bit of code to exercise it from the rust code, and then nod our heads sagely before we integrate the previous and current section together into the final product of our imagination.

First up. We have to decide what library to choose. If I go and search on docs.rs there's quite a few that show up.
- sqlite
-
The first hit is just called sqlite, and looking at the github issues,
I found a kind soul providing a more in-depth example
which showed how to bind and do transactions which is pretty nice.
Looking at another issue
I saw someone having some trouble with an
inquery and their workaround. I don't think we'll need to use an in query, but it's good to see more. The maintainer responds to most questions with "does sqlite support this?", which seems like a good approach to avoiding feature creep. It looks useable enough, so maybe we'll use it. - rusqlite
-
Mentioned by the first issue in the sqlite repo, rusqlite seems pretty well regarded.
Their example shows how to bind your data to a struct, and looking at the README on
the github repo shows quite a bit
of love. The first thing has a note about cargo and how the library will bring in
sqlite for you without being dependent on a global one if you'd like. Which seems
super useful to me. Additionally, there's a whole bunch of features including
serde_json implements FromSql and ToSql for the Value type from the serde_json crate.
Which sounds like I might be able to maybe use the existing rmp_serde serialization I have right now. Or well, that was the initial thought and then I realized I'm being silly since we're replacing the thing that's using serde. So, that's not as big a boon as initially thought. - sqlite-tiny
- The other one that caught my eye was this "Tiny" one. Which sounded kind of nice because it ships with everything together and didn't really have any dependencies. Which is sort of nice since I assume that that would keep my compile times short. That said, the README felt a bit lacking, and while the code had a few lines of documentation for each method, and I found myself reading through a good amount of the source code, it felt like more of a hobby/personal library than something meant to be used by other people.
There were other options as well. Such as libraries that tried to provide a full ORM experience. However, I don't really like ORMs very much. In general I find that the abstraction and the way folks almost always try to hide away important details causes me more grief than if I had just written plain old SQL. It's not hard to write a prepared statement, and if you declare some constants for table names or field names or whatever then it's really NOT hard to keep everything in sync. Since this is my own personal project, I'll happily avoid any ORMs for the time being!
So, let's decide on a library to use and then set up our database schema!
Given how well it's regarded, I'm going to try out rusqlite first. So, let's do something super simple:
$ cargo add rusqlite
Updating crates.io index
Adding rusqlite v0.37.0 to dependencies
Features:
42 deactivated features
Updating crates.io index
Locking 6 packages to latest compatible versions
Adding fallible-iterator v0.3.0
Adding fallible-streaming-iterator v0.1.9
Adding hashlink v0.10.0
Adding libsqlite3-sys v0.35.0
Adding rusqlite v0.37.0
Adding vcpkg v0.2.15
This added rusqlite = "0.37.0" to my cargo toml file, and then I remembered
that I wanted the bundle version. So, I tweaked the line to say
rusqlite = { version = "0.37.0", features = ["bundled"] }
Then re-ran cargo build
$ cargo build Downloaded hashlink v0.10.0 Downloaded pkg-config v0.3.32 Downloaded rusqlite v0.37.0 Downloaded libsqlite3-sys v0.35.0 Downloaded 4 crates (5.4 MB) in 2.35s (largest was `libsqlite3-sys` at 5.2 MB) ... Finished `dev` profile [unoptimized + debuginfo] target(s) in 9.27s
Ok, great! Assuming that worked I now have a sqlite binary ready to run! Let's try to
start poking our fingers in. First off, let's make an error, I like when the compiler
guides us, so, noting that the first thing I'll need is a connection to a database,
and having seen the open function used in one of the examples I had flipped
through, I through a crappy function in to start exploring:
use rusqlite::Connection;
fn do_i_know_how_to_do_this() -> bool {
let conn = Connection::open("helloworld.db");
conn
}
And If I run cargo build then the compiler will guide me into telling me
that the open function for the Connection is going to give me back either a connection
or an error.
28 | fn do_i_know_how_to_do_this() -> bool {
| ---- expected `bool` because of return type
29 | let conn = Connection::open("helloworld.db");
30 | conn
| ^^^^ expected `bool`, found `Result<Connection, Error>`
|
= note: expected type `bool`
found enum `Result<Connection, rusqlite::Error>`
Now, obviously,
the documentation for the open method could have told me that. But, I find that
when I look at the documentation, it telling me that Result<Self>
isn't as useful to my understanding as seeing that last found enum line
that actually tells me that rusqlite has defined their own special Error type.
So then, swapping out my silly bool type I tossed in for the real thing:
use rusqlite::{params, Connection, Result};
fn do_i_know_how_to_do_this() -> Result<Connection, rusqlite::Error> {
let conn = Connection::open("helloworld.db");
conn
}
fn main() {
let _ = do_i_know_how_to_do_this().expect("Welp...");
...
And running up a quick cargo run test meh and looking in the directory afterwards?
Beautiful. Now we just need a schema and we can do our next step. Given how simple our struct was, and how essentially we want to store the same sort of thing. We can just make a simple SQL database schema like this:
CREATE TABLE IF NOT EXISTS dupdb_filehashes (
hash TEXT NOT NULL,
file_path TEXT NOT NULL
);
Now, you might be thinking back to the declaration of hash in the various parts
of the code from before and thinking: "wait, but that was a u64". And that's a very good
point! I first started typing out hash UNSIGNED BIT INT, but then happened to
go reading the data type docs and noticed
INTEGER. The value is a signed integer, stored in 0, 1, 2, 3, 4, 6, or 8 bytes depending on the magnitude of the value.
Notice how it says signed integer? Yeah. This also shows up in the rusqlite documentation where there's a callout in the types index page
ToSql always succeeds except when storing a u64 or usize value that cannot fit in an INTEGER (i64). Also note that SQLite ignores column types, so if you store an i64 in a column with type REAL it will be stored as an INTEGER, not a REAL (unless the column is part of a STRICT table).
So, given this and some questions and answers on StackOverflow,
I decided that I'd dodge the question and simply turn our u64 into a string and then convert it back
again. The other idea I had was to store it as a BLOB, which I think would work because
we're only ever going to need to do equality checks against it. Still, I'd like to be able to read the
hashes if I have to look at the database for some reason when debugging, so I'm going to roll with the
idea of storing the hash as text until it turns into a problem.
const CREATE_TABLE_SQL: &str = "
CREATE TABLE IF NOT EXISTS dupdb_filehashes (
hash TEXT NOT NULL,
file_path TEXT NOT NULL
)";
use rusqlite::{Connection, Result};
fn connect_to_sqlite() -> Result<Connection, rusqlite::Error> {
let conn = Connection::open("helloworld.db");
conn
}
fn main() {
let sqlite_connection = connect_to_sqlite().expect("Welp...");
sqlite_connection.execute(CREATE_TABLE_SQL, ()).expect("Could not create sqlite table");
...
Running cargo run shows no expectation errors, so I guess this worked! Of course, the
true test is if we can add in a file and hash and whatnot. So, let's fake things a bit and hash a
file of our choosing and store that into the database. Since I we're just testing, let's do a select
after and just dump out the rows one by one as well:
const INSERT_HASH_AND_FILEPATH_SQL: &str = "
INSERT INTO dupdb_filehashes (hash, file_path) VALUES (?1, ?2)
";
fn add_hash_to_db_test(conn: Connection, file_path: PathBuf) {
let bytes = fs::read(&file_path).expect("could not read path");
let hash = seahash::hash(&bytes).to_string();
let absolute_path = path::absolute(file_path)
.expect("Unable to get absolute path for file to hash").to_str()
.expect("Unexpected file name containining non utf 8 characters found").to_string();
let mut statement = conn.prepare_cached(INSERT_HASH_AND_FILEPATH_SQL)
.expect("could not prepare insertion statement");
statement.execute((hash, absolute_path))
.expect("could not execute add hash insertion statement");
let mut statement = conn.prepare_cached("SELECT hash, file_path FROM dupdb_filehashes")
.expect("could not prepare select from file");
let row_iter = statement.query_map([], |row| {
Ok((
row.get::<usize, String>(0).expect("could not retrieve column 0 for select row"),
row.get::<usize, String>(1).expect("could not retrieve column 1 for select row")
))
}).expect("failed to query dupdb_filehashes table");
for row in row_iter {
println!("{:?}", row);
}
}
We're not doing things too differently than the example from
the main example, though a chief difference is that I'm not loading anything up into a struct. Which is why
the compiler got a bit feisty with me before I added in the ::<usize, String>> type hints
for it to follow.
--> duplicate-file-monitor\src\main.rs:54:17
|
54 | row.get(1).expect("could not retrieve column 1 for select row")
| ^^^ cannot infer type of the type parameter `T` declared on the method `get`
|
= note: cannot satisfy `_: FromSql`
= help: the following types implement trait `FromSql`:
...
Once we're not just writing helper test code to confirm that the ergonomics of the library are sound, we won't have that issue anymore. I'll make a proper struct and everything! Promise! Anyway, running this code helpfully shows that, yes, it truly does work:
let sqlite_connection = connect_to_sqlite().expect("Welp...");
sqlite_connection.execute(CREATE_TABLE_SQL, ()).expect("Could not create sqlite table");
let test_path = Path::new("duplicate-file-monitor\\src\\main.rs");
add_hash_to_db_test(sqlite_connection, test_path.to_path_buf());
.. and out pops ...
Ok(("8329261273684546072", "duplicate-file-monitor\\src\\main.rs"))
And if I run it again?
Ok(("8329261273684546072", "duplicate-file-monitor\\src\\main.rs"))
Ok(("8329261273684546072", "duplicate-file-monitor\\src\\main.rs"))
Great! So lastly, we have to pause and ask: is there anything else we should consider here? We've made a table, but how will we be using that table?
SELECT COUNT(*) FROM dupdb_filehashes WHERE hash = ?1; DELETE FROM dupdb_filehashes WHERE hash = ?1 AND file_path = ?2 LIMIT 1; INSERT INTO dupdb_filehashes (hash, file_path) VALUES (?1, ?2); SELECT hash, file_path FROM dupdb_filehashes WHERE hash IN (SELECT hash FROM dupdb_filehashes WHERE file_path = ?1); DROP TABLE dupdb_filehashes;
The method contains_duplicate_for_hash can be handled by
checking the count from query 1. Removing a hash if a file is deleted
can be done via query 2. We just used query 3 in the test, and we'll
also use it for whenever a file being watched is moved/added. The 4th
query can be used for the debug_key method that is used
when the program is called with 2 arguments to check what files have
the same hash as the path being considered. And the last one, of course,
is for if we decide to reset the database.
Given that we'll be querying by both hash and file_path
it probably makes sense to put an index onto them. I remember from late nights
and early mornings dealing with performance issues with Wordpress that a TEXT
column normally has limitations on how much it can fit into an index. But given
that our hashes are always just a u64 number, there shouldn't be a problem on
that, and windows has filepath size limits, so again, probably not going to be
a problem.
So, in addition to the CREATE TABLE statement, I'll want to create
a couple indices, er, assuming that SQLITE can do indices, right? Oh good.
It does! Though not without
its own quirks. So! Based on our count and select query I suppose we should
index the hash. Following along with the documentation
we end up with this bit of SQL:
CREATE INDEX IF NOT EXISTS hash_index ON dupdb_filehashes (hash);
And of course, this translates into some simple rust code that we can re-use later as we refactor the existing system a bit:
const CREATE_INDICES_SQL: &str = "
CREATE INDEX IF NOT EXISTS hash_index ON dupdb_filehashes (hash);
";
...
sqlite_connection.execute(CREATE_INDICES_SQL, ())
.expect("Could not setup indices on sqlite db");
I think what we should probably do is get the SQL we know and love into some constants, add a few simple top level functions to perform them and return a reasonable result from each, and then we can start integrating. So, first one up, database initialization:
const SQL_CREATE_TABLE: &str = "
CREATE TABLE IF NOT EXISTS dupdb_filehashes (
hash TEXT NOT NULL,
file_path TEXT NOT NULL
)";
const SQL_CREATE_INDICES: &str = "
CREATE INDEX IF NOT EXISTS hash_index ON dupdb_filehashes (hash);
";
pub fn initialize(sqlite_connection: &Connection) {
sqlite_connection.execute(SQL_CREATE_TABLE, ())
.expect("Could not create sqlite table");
sqlite_connection.execute(SQL_CREATE_INDICES, ())
.expect("Could not setup indices on sqlite db");
}
The only real difference from our testing code so far is that I went ahead and changed
the suffix _SQL to be a prefix instead SQL_ because I like the
way it feels to have something similar. If I were to list off each string individually,
and not across multiple lines, I think it would make it easier to find the bunch of constants
that are sql related this way.
const SQL_INSERT_HASH_AND_FILEPATH: &str = "
INSERT INTO dupdb_filehashes (hash, file_path) VALUES (?1, ?2)
";
pub fn insert_file_hash(conn: &Connection, hash: u64, absolute_path: &str) -> bool {
let mut statement = conn.prepare_cached(SQL_INSERT_HASH_AND_FILEPATH)
.expect("could not prepare insertion statement");
match statement.execute((hash.to_string(), absolute_path)) {
Ok(rows_inserted) => rows_inserted == 1,
Err(err) => {
eprintln!("Unable to insert into table failed: {}", err);
false
}
}
}
The insertion code is no longer exploding if the execute command fails.
I suppose I could argue that if it does fail maybe I should crash, but honestly,
there's the chance that if some really really weird character in a file path shows up
the file path might not transform properly into a C string, and the
documentation says it will explode. But one bad path shouldn't stop the entire duplication
program. It's not like I currently have a watch on the program to let me know if it stops or not.
5
Moving right along, the primary way we check if there are dupes is by counting how many files have the same hash, and so that's simple enough:
const SQL_SELECT_COUNT_FOR_HASH: &str = "
SELECT COUNT(*) FROM dupdb_filehashes WHERE hash = ?1
";
pub fn count_of_same_hash(conn: &Connection, hash: u64) -> u32 {
let mut statement = conn.prepare_cached(SQL_SELECT_COUNT_FOR_HASH)
.expect("Could not fetch prepared count query");
match statement.query_one([hash.to_string()], |row| row.get::<_, u32>(0)) {
Err(err) => {
eprintln!("Unable to count rows in table: {}", err);
0
},
Ok(count) => count
}
}
I think that on error returning a 0 is probably true. After all, if I can't talk to the database, it's kind of like sticking my fingers into my ears and ignorin' a query's actual result. So a zero feels equivalent and we don't make the entire program explode if something funny happens.
For our next trick, let's break this up since while writing up the code I ran into something somewhat interesting. Or at least, a somewhat awkward construction that seems worth mentioning. The SQL is as usual:
const SQL_SELECT_DUPES_FOR_FILE: &str = "
SELECT hash, file_path FROM dupdb_filehashes
WHERE hash IN (SELECT hash FROM dupdb_filehashes WHERE file_path = ?1)
";
But, if one constructs the application code and uses query, rather than
query_map you'd write something like this:
let mut rows = match statement.query([absolute_path]) {
Err(binding_failure) => {
eprintln!("Unable to select rows from table: {}", binding_failure);
return Vec::new()
},
Ok(mapped_rows) => mapped_rows
}
// This taken from the documentation here
while let Some(row) = rows.next()? {
// ...
}
Since I've been nixing the ? usage and explicitly handling the errors,
I was left with trying to understand how to deal with this. And boy, it is awkward!
rows.next() returns a Result, and so you have to pull that
out, then deal with an err, a some, or a none. Sadly, you can't do something
like while match { arms... }, and so you're kind of left with having to
do something awkward like
let sentinel = true;
do {
match rows.next() {
Err(ohno) => {
eprintln!(...);
sentinel = false;
},
Ok(None) => {
// done processing rows...
sentinel = false;
},
Ok(Some(row)) => {
// now do something with the value you wanted all along
}
}
} while (sentinel)
And while that's not too bad, thankfully we can use query_map
to convert the result from the query into a proper iterator instead.
pub fn dups_by_file(conn: &Connection, absolute_path: &str) -> Vec<(String, String)> {
let mut statement = conn.prepare_cached(SQL_SELECT_DUPES_FOR_FILE)
.expect("Could not fetch prepared select_dups query");
let rows = statement.query_map([absolute_path], |row| {
Ok((
row.get::<usize, String>(0)
.expect("could not retrieve hash column 0 for select row"),
row.get::<usize, String>(1)
.expect("could not retrieve file_path column 1 for select row")
))
});
let mut dups = Vec::new();
match rows {
Err(binding_failure) => {
eprintln!("Unable to select rows from table: {}", binding_failure);
},
Ok(mapped_rows) => {
for result in mapped_rows {
match result {
Ok(tuple) => {
dups.push(tuple);
},
Err(error) => {
eprintln!("problem retrieving a row result for dups query {}", error)
}
}
}
}
}
dups
}
That said. It's still a bit awkward I think, but such is life when you've got an API
that's returning what basically boils down to Result(Iterator(Result(things)))
I suppose, since we only ever return an Ok from the closure being used by the query_map
method, that I could do an expect and force it out to remove that last match. But, this sort
of brings to mind that mayube we should be returning an Err from that closure if
I can't get the columns out? …
Nah. This is one of those times where I'm pretty sure that if my database is returning garbage to me that we've reached a very very strange state of the world so we should abort entirely. I suppose with that in mind then I could follow through on that and nix the match inside of the loop too...
This is why it's nice to blog and write code at the same time. You retrospective on your own half baked ideas as you go and iterate before you let the world see it! 6 So we'll just tweak the code to be:
pub fn dups_by_file(conn: &Connection, absolute_path: &str) -> Vec<(String, String)> {
let mut statement = conn.prepare_cached(SQL_SELECT_DUPES_FOR_FILE)
.expect("Could not fetch prepared select_dups query");
let rows = statement.query_map([absolute_path], |row| {
Ok((
row.get::<usize, String>(0).expect("could not retrieve hash for select row"),
row.get::<usize, String>(1).expect("could not retrieve file_path for select row")
))
});
let mut dups = Vec::new();
match rows {
Err(binding_failure) => {
eprintln!("Unable to select rows from table: {}", binding_failure);
},
Ok(mapped_rows) => {
for result in mapped_rows {
let tuple = result
.expect("Impossible. Expect should have failed in query_map");
dups.push(tuple);
}
}
}
dups
}
That's a bit nicer. Granted, whenever a programmer says something is impossible, there's probably
a decent chance that one day it will happen. But I'm decently confident that query_map
should fail before we ever reach that other line. Let's move along and hope that this hubris remains
in our past here in this blogpost and never surfaces again.
Speaking of hubris, this next one should be easy right?
const SQL_DELETE_BY_HASH_AND_FILE: &str ="
DELETE FROM dupdb_filehashes WHERE hash = ?1 AND file_path = ?2 LIMIT 1
";
fn delete_all_matching(conn: &Connection, hash: u64, absolute_path: &str) -> usize {
let mut statement = conn.prepare_cached(SQL_DELETE_BY_HASH_AND_FILE)
.expect("Failed to prepare delete statement");
match statement.execute([hash.to_string(), absolute_path.to_string()]) {
Ok(rows_deleted) => rows_deleted,
Err(err) => {
eprintln!("Unable to delete from dupdb_filehashes: {}", err);
0
}
}
}
Removing a single duplicate should be pretty straightforward. In general, we should
have a unique hash and file_path for each file on the system, since it'd be odd to
attempt to be added twice given the way data comes in. But just to make sure, I was
thinking we should go ahead and LIMIT 1. The rust code is pretty much
the same idea as the insertion code, we get back information about how many rows
were removed by the command, and while I think that should always be 1, I suppose
we'll return the result out just in case we want to do something about that.
As a formality, I'll add the function call to my test function and then move a…lon…g…
thread 'main' panicked at duplicate-file-monitor\src\sql.rs:98:10:
Failed to prepare delete statement:
SqlInputError {
error: Error { code: Unknown, extended_code: 1 },
msg: "near \"LIMIT\": syntax error",
sql: "DELETE FROM dupdb_filehashes WHERE hash = ?1 AND file_path = ?2 LIMIT 1",
offset: 64
}
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
error: process didn't exit successfully (exit code: 101)
Wait what? Syntax error? What? But limits in a delete statements are a normal thing aren't they? The sqlite DELETE syntax says… where is it? Huh? Hm?!

Oh, hey there's a section here called "Optional LIMIT and ORDER BY clauses" I wonder what it says…
If SQLite is compiled with the SQLITE_ENABLE_UPDATE_DELETE_LIMIT compile-time option, then the syntax of the DELETE statement is extended by the addition of optional ORDER BY and LIMIT clauses: ...
Only if SQLite is compiled with that option? But… Why?
If this option is defined, then it must also be defined when using the Lemon parser generator tool to generate a parse.c file. Because of this, this option may only be used when the library is built from source, not from the amalgamation or from the collection of pre-packaged C files provided for non-Unix like platforms on the website.
source
You only get this if you build SQLite yourself? Why?! Ugh. Well that's annoying. Ok, well, I suppose we do have a workaround for this though. Even though I only defined two columns, technically we have a third. The rowid that SQLite automatically generates for us for every row. So, if I really want to write my query so that it only every deletes a single row, then I can do this silly workaround:
const SQL_DELETE_BY_HASH_AND_FILE: &str ="
DELETE FROM dupdb_filehashes WHERE rowid = (
SELECT rowid FROM dupdb_filehashes WHERE hash = ?1 AND file_path = ?2 LIMIT 1
)
";
And re-running my little test script again:
... in my test code ...
let success = insert_file_hash(conn, hash, &absolute_path);
println!("success: {}", success);
let how_many_removed = delete_all_matching(conn, hash, &absolute_path);
println!("removed {:?}", how_many_removed);
... in my terminal ...
success: true
removed 1
Awesome! Ok! One more and then we're ready to roll out!
const SQL_DROP_TABLE: &str = "
DROP TABLE dupdb_filehashes
";
pub fn reset_all_data(sqlite_connection: &Connection) {
sqlite_connection.execute(SQL_DROP_TABLE, ())
.expect("Could not drop database. Go delete it yourself.");
initialize(sqlite_connection);
}
At this point, my current test database is all kinds of silly. With bunches of different hashes attached to the same file path (because I've just been hashing my main.rs file as I work) and so for our finale we can drop it all!
... in test script ...
let count = count_of_same_hash(conn, hash);
println!("Rows inserted so far {:?}", count);
... in my terminal before I ran it ...
Rows inserted so far 18
... in my terminal after adding the reset ...
Rows inserted so far 1
Beautiful.
Integrating SQLite and dupdb ↩
So we've got methods to call that can accomplish similar functionality to what we had before, and so our challenge becomes build this ship of theseus, one little block at a time. Let's start with the initialization step:
// NEW!
fn dupdb_initialize_hidden_folder() -> bool {
let database_exists_already = Path::new(".").join(sql::DATABASE_FILE).exists();
if database_exists_already {
return false;
}
let connection = sql::connect_to_sqlite().expect("Could not open connection to database.");
sql::initialize(&connection);
return true;
}
// OLD!
fn dupdb_initialize_hidden_folder() -> bool {
let mut builder = DirBuilder::new();
let path = dupdb_database_path();
let mut index_file = path.clone();
index_file.push(NAME_OF_HASH_FILE);
builder.recursive(true).create(path.clone()).expect("Could not create .dupdb database.");
match File::create_new(&index_file) {
Ok(mut file) => {
println!("New index file has been created: {:?}", index_file);
let empty = DuplicateDatabase {
hash_to_files: HashMap::new(),
files_to_hash: HashMap::new()
};
let mut buf = Vec::new();
empty.serialize(&mut Serializer::new(&mut buf))
.expect("Could not serialize empty DuplicateDatabase");
file.write_all(&buf).expect("Did not write bytes to file");
true
},
Err(error) => {
if error.kind() == ErrorKind::AlreadyExists {
// Good, it exists. Do nothing.
println!("Index file already exists: {:?}", index_file);
} else {
panic!("There was a problem creating the index file: {:?}", error);
}
false
}
}
}
In the original implementation we had to zero out a new DuplicateDatabase struct and
create the new file with it in it so that we'd have something to load up and use. But,
this gets a lot simpler with the database. We simply check to see if the sqlite file
is where we expect it to be and open and close a connection to it if not. Our
initialize method will deal with creating the tables and indices as we
went over in the last section.
You might be wondering: why don't you just pass in a single connection instead of opening one then closing it just for this? It's a good question, and the simple is that when I'm refactoring, I tend to make small movements as much as possible. Since introducing a shared connection across the app would mean modifying the interface of all my top level functions, I want to avoid that as much as we can. If we need to do this, then sure, let's do it. But until my hands forced, let's see how far we can get like this!
Working my way through the main method, the next helper is one that we can drastically simplify, but only after we do some extra work. It's current, file-based, form uses serde to read the entire struct into memory:
fn dupdb_database_load_to_memory() -> DuplicateDatabase {
let folder = dupdb_database_path();
let mut index_file = folder.clone();
index_file.push(NAME_OF_HASH_FILE);
let handle = File::open(index_file).expect("Could not open index file");
rmp_serde::from_read(handle).expect("Could not deserialize DuplicateDatabase")
}
I'd like to keep the interface to the DuplicateDatabase the same, and so this means that
we need to modify it to no longer use its in-memory mappings, but rather query the database
for its information. Sadly, because Connection isn't serializable, we're going
to have to replace the entirety of the code relating to that right away.
#[derive(Serialize, Deserialize, Debug)]
struct DuplicateDatabase {
hash_to_files: HashMap<u64, Vec<String>>,
files_to_hash: HashMap<String, u64>,
}
Becomes
#[derive(Debug)]
struct DuplicateDatabase {
conn: sql::Connection
}
And then everything breaks!
warning: `duplicate-file-monitor` (bin "duplicate-file-monitor")
generated 6 warnings
error: could not compile `duplicate-file-monitor` (bin "duplicate-file-monitor")
due to 14 previous errors; 6 warnings emitted
It's only 14 errors though, this shouldn't be too hard!
impl DuplicateDatabase {
fn add(&mut self, hash: u64, full_file_path: String) {
let entry = self.hash_to_files.entry(hash);
let existing_files = entry.or_default();
if !existing_files.contains(&full_file_path) {
existing_files.push(full_file_path.clone());
}
self.files_to_hash.entry(full_file_path).insert_entry(hash);
}
...
Is pretty simple to change using our new SQL methods:
fn add(&mut self, hash: u64, full_file_path: String) {
let entered = sql::insert_file_hash(&self.conn, hash, full_file_path);
if !entered {
eprintln!("Did not enter insert into database: {}, {}", hash, full_file_path);
}
}
That actually makes things a lot simpler! Since I'm not managing a two way mapping between the hash and a list of files associated to them, this just becomes about dropping the requested items off at the pool, so to speak. Simple and easy, and my list of compiler errors dropped by 1, nice. Next up, checking for a duplicate hash. The old code for the method:
fn contains_duplicate_for_hash(&self, hash: u64) -> bool {
let contains_hash = self.hash_to_files.contains_key(&hash);
if !contains_hash {
return false;
}
if let Some(files) = self.hash_to_files.get(&hash) {
return files.len() > 1
}
false
}
Likewise becomes
fn contains_duplicate_for_hash(&self, hash: u64) -> bool {
let count = sql::count_of_same_hash(&self.conn, hash);
count > 1
}
The compiler errors drop to 11, and just like before, this is a major simplication of logic for us. If this keeps up who knows, maybe I'll get this blog post done in time to play some video games! 7 The next method is to remove a file path from our tracking:
fn remove(&mut self, full_file_path: String) {
match self.files_to_hash.get(&full_file_path) {
None => {
eprintln!("Requested to remove path that wasn't tracked {:?}", full_file_path);
// Could technically do a full search over all values but that shouldn't
// be neccesary unless we screw up and access the maps directly.
// This is normal if we haven't built the index yet
//and a file is removed from where we're watching.
},
Some(hash) => {
println!("Removing entry with hash {:?} and path {:?}", hash, full_file_path);
let existing_files = self.hash_to_files.entry(*hash).or_default();
existing_files.retain(|f| *f != full_file_path);
self.files_to_hash.remove_entry(&full_file_path);
}
}
}
We have to go from the full file path to the hash, and then remove any references to file paths that have this hash from the database. So, going to the SQL we wrote earlier, we can do this sort of thing
fn remove(&mut self, full_file_path: String) {
let references = sql::dups_by_file(&self.conn, &full_file_path);
let to_remove: Vec<(String, String)> = references
.into_iter()
.filter(|(_, file_path)| *file_path == full_file_path)
.collect();
for (hash, filepath) in to_remove {
let numeric_hash = hash.parse().expect("Hash in database was not parseable to u64");
sql::delete_all_matching(&self.conn, numeric_hash, &filepath);
}
}
Although, thinking about the context in which this runs. I probably could just write a simpler bit of SQL and push this logic down into the database rather than the application level. That'd probably look like just a plain
DELETE FROM dupdb_filehashes WHERE file_path = ?1
With no limits or anything, which would be a lot simpler. I'll that as a TODO for now, and circle back once we've made it past the compiler errors. The last method on the dupdb is the debugging one:
fn debug_key(&self, full_file_path: String) {
match self.files_to_hash.get(&full_file_path) {
None => {
println!("Path {:?} not in files_to_hash list", full_file_path);
},
Some(hash) => {
println!("Path {:?} is in list with hash {:?}", full_file_path, hash);
match self.hash_to_files.get(hash) {
None => {
println!("Hash {:?} does not have a matching list of files", hash);
},
Some(existing_files) => {
for file_mapped_to_hash in existing_files {
println!("Value: {:?}", file_mapped_to_hash);
}
}
}
}
}
}
Given how the debugging method was for helping to inspect both sides of the two way mapping that doesn't exist anymore, we can instead repurpose it into showing up what the database has found to share the same hash value:
fn debug_key(&self, full_file_path: String) {
let references = sql::dups_by_file(&self.conn, &full_file_path);
if references.len() == 0 {
println!("Path {:?} not in files_to_hash list", full_file_path);
return;
}
for (hash, file_path) in references {
println!("Value: Hash: {:?} Path: {:?}", hash, file_path);
}
}
We're down to 6 errors, so we're not out of the woods yet, basically anywhere I was
calling duplicate_database.serialize needs to be examined. This should
be more of an exercise in cutting than keeping though. For example:
fn dupdb_save_to_file(duplicate_database: &DuplicateDatabase) {
let folder = dupdb_database_path();
let mut index_file = folder.clone();
index_file.push(NAME_OF_HASH_FILE);
let mut file = File::options()
.read(true)
.write(true)
.truncate(true)
.open(index_file)
.expect("Could not open index file");
let mut buf = Vec::new();
duplicate_database
.serialize(&mut Serializer::new(&mut buf))
.expect("Could not serialize empty DuplicateDatabase");
file.write_all(&buf).expect("Did not write bytes to file");
}
Doesn't really need to exist anymore. Given that the sqlite database handles all of this, there's no reason to try to manage that, and thus, our errors decrease a bit more and we're one step closer to the compiler blessing our journey. The counterpart to the above function does need a bit of work:
fn dupdb_database_load_to_memory() -> DuplicateDatabase {
let folder = dupdb_database_path();
let mut index_file = folder.clone();
index_file.push(NAME_OF_HASH_FILE);
let handle = File::open(index_file)
.expect("Could not open index file");
rmp_serde::from_read(handle)
.expect("Could not deserialize DuplicateDatabase")
}
Becomes
fn dupdb_database_load_to_memory() -> DuplicateDatabase {
let connection = sql::connect_to_sqlite()
.expect("Unable to connect to sqlite database");
sql::initialize(&connection);
DuplicateDatabase {
conn: connection
}
}
Which doesn't really need any explanation. We get a connection to the database, stuff it in the struct that will give us those handy methods we just refactored, and then hand it back up so that all those functions we went over in the first section of this blog post can now do their job!
Well, that is after one more bit. The compiler has no errors, but it is giving me warnings still:
warning: function `reset_all_data` is never used
--> duplicate-file-monitor\src\sql.rs:114:8
|
114 | pub fn reset_all_data(sqlite_connection: &Connection) {
| ^^^^^^^^^^^^^^
Which reminds me. Yes, we've got dupdb_reset_database_from_existing_files
to tweak! This legacy code looks like this:
fn dupdb_reset_database_from_existing_files(
path: PathBuf, duplicate_database: &mut DuplicateDatabase
) {
println!("Reseting database according to files within {:?}", path);
let entries = RecursiveDirIterator::new(&path)
.expect("Could not load path to reindex database");
let paths = entries
.filter(|dir_entry| dir_entry.path().extension().is_some()) // welcome to my onlyfiles
.map(|file| file.path())
.collect();
dupdb_update_hashes_for(paths, duplicate_database);
}
And really, we actually still want pretty much all of that! It's walking the directory recursively and adding any entry it finds into the database. If we want to have this reset really reset to nothing, and then populate the database file with what we're now watching, then we can update the method to call the reset like:
fn dupdb_reset_database_from_existing_files(
path: PathBuf, duplicate_database: &mut DuplicateDatabase
) {
println!("Reseting database according to files within {:?}", path);
sql::reset_all_data(&duplicate_database.conn);
let entries = RecursiveDirIterator::new(&path)
.expect("Could not load path to reindex database");
...
And that'll do the trick! So, we've got the code compiling now, the serialized struct serving as a databased replaced with an actual database. And so the question becomes. Does everything still work?
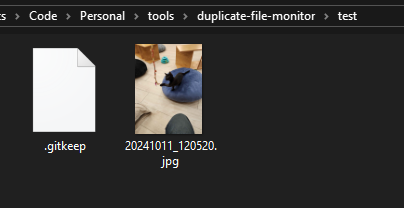
warning: `duplicate-file-monitor` (bin "duplicate-file-monitor") generated 6 warnings
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.20s
Running `\target\debug\duplicate-file-monitor.exe test`
Reseting database according to files within "test"
Initial database saved to "test"
And querying for the key?
cargo run test test/20241011_120520.jpg Value: Hash: "8700085312930649263" Path: "C:\\...\\test\\20241011_120520.jpg"
Then copying in the same file with a different name:
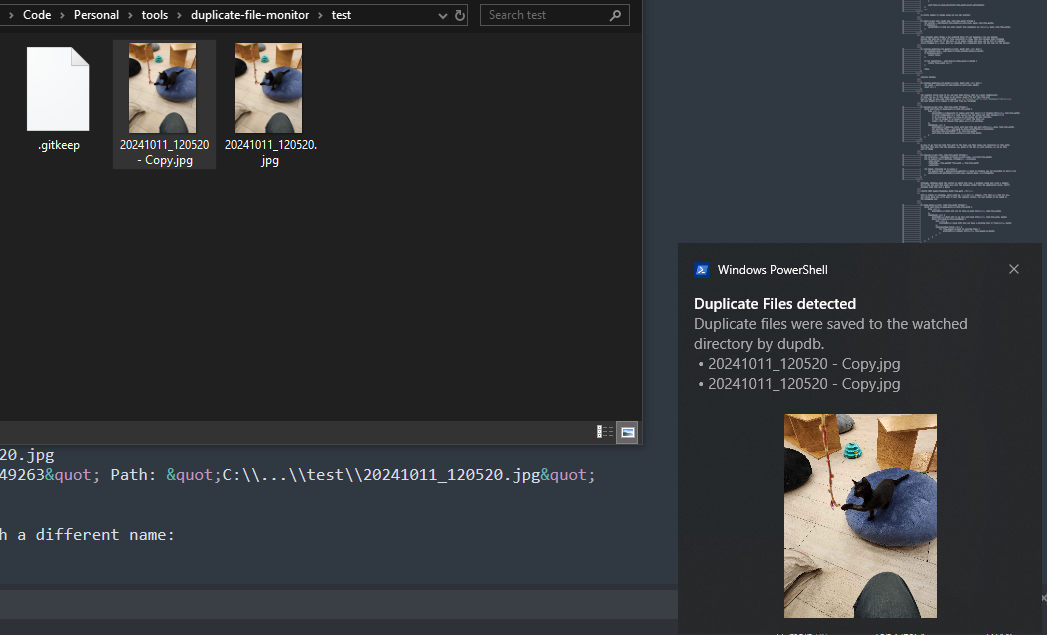
And querying by the key again shows me the original and a couple of copies
Value: Hash: "8700085312930649263" Path: "C:\\...\\test\\20241011_120520.jpg" Value: Hash: "8700085312930649263" Path: "C:\\...\\test\\20241011_120520 - Copy.jpg" Value: Hash: "8700085312930649263" Path: "C:\\...\\test\\20241011_120520 - Copy.jpg"
The extra one here I think is because the watch for the database picks up on a generic event as well as the usual file operations:
fn dupdb_watch_forever(watch_folder_path: &Path, duplicate_database: &mut DuplicateDatabase) {
let (tx, rx) = mpsc::channel();
let mut debouncer = new_debouncer(Duration::from_secs(1), None, tx)
.expect("Failed to configure debouncer");
debouncer.watch(watch_folder_path, RecursiveMode::Recursive)
.expect("Failed to begin file watch");
for result in rx {
match result {
Ok(debounced_events) => {
let paths: Vec<PathBuf> = debounced_events.into_iter().filter_map(|event| {
match event.kind {
EventKind::Remove(_) => Some(event.paths.clone()),
EventKind::Create(_) => Some(event.paths.clone()),
EventKind::Modify(_) => Some(event.paths.clone()),
EventKind::Any => Some(event.paths.clone()),
EventKind::Access(_) => None,
EventKind::Other => None,
}
}).flatten().collect();
dupdb_update_hashes_for(paths, duplicate_database);
},
Err(error) => eprintln!("Watch error: {:?}", error),
}
}
}
And this is something that's been happening for a little while. I'll get around to fixing that one day. But not today! Today, I'm pretty content to say that we've got a "real" database in place for the dup detector system. And that means that if I wanted to, I could build some local frontend code to display things in an easier to manage way than how I do now. But, that'll be something to do in a future blog post! For now, I should go to sleep, and then, it'll be time to play some video games!
