Context
A while ago I decided to make this neocities site, and while doing so and exploring options, I settled in on just writing all my HTML by hand because it's fun to do so. I could use a static site generator like I have in the past; I could use some sort of desktop tool to focus on writing markdown or something and have it compile and publish it for me; I could do a lot of things. But so far, there's been something pleasant about just writing HTML that has kept me doing it. That said, whenever I add a new section to the site (which is infrequent) I have to update the navigation links.
Doing this by hand becomes a tiresome task as I make more content for the site, and so of course, being a programmer, I look to automate this in some way, since I've been trying to broaden my horizons a bit (people seem to like making fun of me for Java for some reason online?) I've been experimenting with some typescript and reading some rust stuff, so I figured I'd try to accomplish this trivial task using those languages first.
The first failure
Typescript. I recently wrote a little bit to create the search for the video archive section and it was an OK experience, if not a bit cumbersome given my choice to use Deno. But I figured I'd give it another shot given that I want to manipulate some HTML, so typescript, being javascript at the end of the day, seemed like a pretty decent choice to use to... well, manipulate some HTML.
Arguments were easy, so I started writing my script like I would anything else:
const fileWithNavToCopy = Deno.args[0];
const toTraverse = Deno.args[1];
if (!fileWithNavToCopy) {
throw new Error("Pass path to file with correct nav as first arg");
}
if (!toTraverse) {
throw new Error("Pass path to directory to traverse");
}
Then I tried to look up how to read a file, another easy thing to do, if not slightly weird feeling to make a text decoder, but whatever:
const td: TextDecoder = new TextDecoder('utf-8');
const fileData = await Deno.readFile(fileWithNavToCopy);
const fileContents = td.decode(fileData);
And then I ran into a problem of trying to figure out how to parse the dom. After searching around, finding multiple different libraries, and then getting pretty confused with how the imports for the libraries themselves actually work I ended up with:
import { DOMParser } from "jsr:@b-fuze/deno-dom";
const parser = new DOMParser();
const document = parser.parseFromString(fileContents, "text/html");
const header = document.getElementsByTagName('header')[0];
console.log(header.children)
And running it sort of worked to let me see that I was able to open the file and get an element out. The next step to traverse the files was a bit awkward though, and I spent a lot of time staring at the Deno website trying to understand its standard library. After getting a bit frustrated that there wasn't just a simple example, I turned to everyone's new favorite helper, chat GPT for some help and it gave me a whole bunch of code I didn't quite understand. It did point me in a good direction with the imports of
import { join, resolve } from "jsr:@std/path";
But I admit, it was late at this point, I had other things I wanted to do, and simply put I wasn't having fun. I don't like using AI to generate boilerplate because it's normally fun to figure things out. For some reason, with typescript's deno library documentation and other libraries notes, it just wasn't happening. So. I decided to give up and go about the rest of my day for a while.
The second failure
Next up on the failure train, I was eating lunch by myself at a local burger joint and needed something to do. I've been enjoying LCOLONQ's streams recently and he does rust game development and other interesting things. The thought occured to me that perhaps I could write my little navigation updating tool with Rust. After all, that would be a good toy problem to learn the language a little bit, I could maybe find out what the fuss is about it, and it might spark some joy.
Well, I started reading the rust guide and got through 3 chapters before I finished my disappointing lunch which was too expensive for what it was. Still intrigued, I went over to a little coffee shop with my laptop, popped open the rust guide on the big screen (I had been reading on my phone during lunch), and programmed through the guessing game example.
It was easy enough, though I do think the match syntax is wacky. But that's probably because I'm just used to scala's match syntax having done that for a decent number of years professionally. So, after feeling ok about rust, I started searching for an HTML library to use to parse the document. I found myself on a reddit question asking much the same thing and decided to check out soup since it invoked the thought of Jsoup and I've used that quite a bit before.
So I opened the soup docs and tried to read a bit. The first examples gave how to read and check out the name of a tag or get its normal html display. I skipped past that, and the next one because it was all about reading the DOM. I want to change the DOM, where's the example for that?
I read the next example. Read only.
I read the next example. Also just iterating and reading the DOM...
The next... you get the idea.
Having landed at the bottom of the page, I decided to try to look into the actual structs, modules, and trait definitions to see if there was an obviously named method. And, well, No, I don't see anything on NodeExt. And on the query builder? also nothing though I didn't expect to find any state change sin something called a query builder.
The thought occured to me that perhaps you just query the tag, then change it directly and call it a day? But also at that point. I had been reminded about soup, and therefore JSoup, and therefore I decided to stop wasting my time noodling when all I really wanted to do was to just get the headers on my website updated and go do something else. So. To Java!
The first solution failed
Java wasn't my first choice because I sort of wanted a little exe I could just stick in my website folder and run everynow and then to update things. You can make an exe from a jar, it's not that hard, but it's also not something I felt like doing given my above feelings of wasting my own time. So, my first solution became pretty straightforward.
I added in JSoup to my pom file, and then hardcoded some file paths to my index file I was going to use as a template to copy over to all the other files, and then wrote up some quite and dirty code.
Document sourceFile = Jsoup.parse(indexPath);
Elements headertoCopy = sourceFile.getElementsByTag("header");
Document docToChange = Jsoup.parse(toChangePath);
Elements header = docToChange.getElementsByTag("header");
if (header.isEmpty()) {
return;
}
header.clear();
header.addAll(headertoCopy);
Files.writeString(toChangePath, docToChange.html());
Which did the job. However, it also had the unpleasant side affect of changing every single line of code for every single HTML file because Jsoup's toString lowercases all the tag names. It also does really weird things to my HTML comments that I don't like. Specifically, when I write code samples I do this:
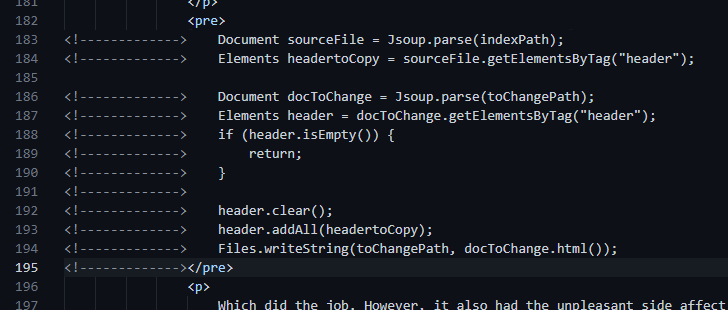
Putting in extra hyphens for the entirety of the indentation I'm fixing up for the pre tags. But, after JSoup got to it, it would produce comments like this

Not really what I like to see. It feels wrong and weird to me. So, I backed out. There were other spacing issues too and I could pretty print the files. But I don't really think it's worth the time to futz around with the output settings if I don't know for sure it's going to do its thing properly.
The actual solution: Don't use a parser.
So. If I don't want to change the entire file then I really only have one option. Read the file, do a substring replace, and hope its not too much of a pain to correct the indentation.
Or better yet, read each file line by line, keep only the lines that aren't being replaced and insert the appropriate header into the correct location while parsing in one fell swoop.
So that's what I did:
package space.peetseater.tag;
import java.io.IOException;
import java.nio.file.*;
import java.nio.file.attribute.BasicFileAttributes;
import java.util.List;
public class FixHtmlForWebsite {
Path sourceNavFile = Paths.get("C:\\Users\\Ethan\\Documents\\Code\\Personal\\peetseater.space\\index.html");
String extensionFile = ".html";
class NavFixerVisitor extends SimpleFileVisitor<Path> {
private final List<String> headerLines;
public NavFixerVisitor(List<String> headerLines) {
this.headerLines = headerLines;
}
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
if (file.getFileName().toString().endsWith(extensionFile)) {
updateFile(file, headerLines);
}
return super.visitFile(file, attrs);
}
}
private void updateFile(Path file, List<String> newHeaderLines) throws IOException {
List<String> lines = Files.readAllLines(file);
StringBuilder newFile = new StringBuilder(lines.size() * 100);
for (int i = 0; i < lines.size(); i++) {
if (lines.get(i).contains("<header>")) {
for (String l : newHeaderLines) {
newFile.append(l);
newFile.append('\n');
}
for (int j = i; j < lines.size(); j++) {
if (lines.get(j).contains("</header>")) {
i = j;
break;
}
}
}
newFile.append(lines.get(i));
newFile.append('\n');
}
Files.writeString(file, newFile.toString());
}
public FixHtmlForWebsite() throws IOException {
List<String> headerLines = Files.readAllLines(sourceNavFile).stream().dropWhile((str) -> {
return !str.contains("<header>");
}).takeWhile((str) -> {
return !str.contains("</header>");
}).toList();
Files.walkFileTree(sourceNavFile.getParent(), new NavFixerVisitor(headerLines));
}
}
I really do love how easy it is to use the simple file visitor class. I don't have to write a loop over directories, it makes it easy to encapsulate the logic I want done for each file in one little place. Nice and simple.
In the FixHtmlForWebsite constructor I pulled out the header lines using
the new stream api that I don't really often use because the concepts of take/drop work
pretty well for snipping out a single list of lines with a well known start and end point
that only appears once in the file.
The updateFile method uses a simple loop to do something similar because it
felt simple, logically speaking, to skip the cursor over the part we don't care about with
our assignment of i to become j after we had inserted the new
lines in place.
My first iteration forgot to add the new lines back into the resulting HTML and so that was fun:
But this is why we use version control. And a quick git checkout . was enough to
reset the website back to a readable state. After adding in the newlines again I had nice clean
diffs:
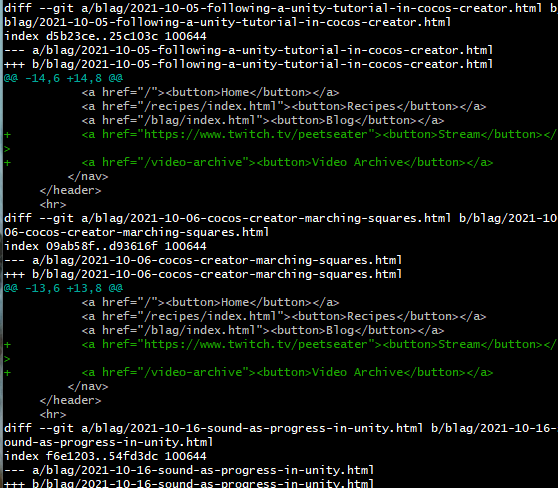
And only the part of my files that actually needed to change, changed. Very nice.
Wrap up
So, what's the take away here and why did I both writing a blog post about this if it's not something more interesting like an actual game tutorial or laughing about how windows can be?? Because sometimes you have to relearn that "the right tool for the job" is sometimes just the tool you can use. And while I will pretty much always leave a big thumbs down on someone doing HTML parsing with a regular expression in a code review and tell them to use a parser (Zalgo demands this and I am happy to make that recommendation most of the time), occasionally, a parser is the wrong tool.
Parsers are really good to use for manipulating the DOM, and make things really easy, I mean, if you look at the Jsoup code I wrote first. A couple lines and I had found the element I knew existed and changed all its elements out for the ones I wanted. JSoup is a great library and I'd recommend it for someone writing something that does this at scale somewhere.
But in this case, it's not the right tool. I want to change the text of the file
in one place, and only one place. I don't want to see every other element change. I don't want my style
of HTML writing to be replaced by one mechanically produced like with the comments or even the fact that
sometimes I'm in the mood to write STRONG instead of strong. When I commit my
updates to the site via git, I like the diffs to be small because I refer back to them and write good commit
messages whenever I can. In cases like this, I don't want massive huge diffs just because a tool processed something.
So instead. You get what I wrote. A simple line reader that splices in some data at the right place, right time,
and then carries on happily. Compared to the hours I spent trying to understand Deno's package manager, the confusion
I felt when trying to find an HTML library in rust, just writing a simple set of functions in Java was so much
easier. Heck, before starting in I thought about just using grep tail and head to write a bash script to
basically do what I did in Java but with more chance of error. Learning new things is fun, but it shouldn't stop
you from enjoying yourself or just getting what you need done if you're just doing something for yourself. Some
people complain or think Java is slow, they're idiots and I'd recommend you point them to the billion row challenge for a modern take on how powerful the JVM is. When you're
just writing scripts for yourself, don't frustrate yourself unneccesarily. Get what you need done and then move on.
There's no reason to not do a read line + splice instead of parsing if the parser is going to make something take
that much longer or run against your own personal preferences on formatting.
Anyway, have fun coding everyone. I'm going to try to figure out something else to code in Rust or TS to learn those a bit more. But it won't be HTML related, that's for sure. Oh, and be thankful if you're disciplined enough to write your indentation the exact same way every single time like me. My script doesn't have to futz with indentation because of that. Pretty nice :D