Advent of code
If you're unaware like I was, advent of code is an annual event in which a nice guy named Eric puts together 25 amusing stories about Christmas adjacent events that require a programmers help. Similar to things such as leetcode or hackerrank 1, each problem is relatively small and requires processing some input to produce an output that is then submitted for verication on the site.
While this might not sound fun to a lot of people2, it's a fun way to brush off the dust if you feel rusty. Or, better yet, pick up and challenge yourself to learn an unfamiliar language with more than just programming katas and subjecting yourself to long hours of reading online manuals. For myself this year, I've decided to go ahead and do the entirety of advent of code in rust.
Why? Because I like both scala and C, and Rust sort of feels like a weird crossbreed of the two. More on that later. I've gone through 6 chapters of the rust book so far, and was losing my motivation to read and do the exercises, so this is a welcome change of pace and let's be honest: learning how to write a loop is boring. Helping elves count the number of steps it takes to screwn over a guard via time travel shenanigans is fun.
Let's dive in. Oh, and there will be spoilers obvious. So if you haven't done the problem sets yet and want to think about them youself, bookmark this page and come back later. I'm going to assume you're somewhat familiar with each problem.
Quick nav!
Day 3 and 6 were my favorites, so if you want to see something neat. Read each of those! The last section are my thoughts on rust so far. Enjoy!
Day 1
Both day 1 and 2 weren't particularly interesting from the problem itself perspective and solving both part 1 and 2 of the challenge took less than a half hour for each. Given that I have 0 experience with rust, I'm spending more of time learning syntax and reading compiler erros than actually solving anything meaningful.
Which is why in the first day's challenge, I forewent the file IO to read the problem set in. Opting instead to use my sublime text fu I've shown in other posts to quickly convert the text file into one giant inline list.
fn left_data() -> [i32; 1000]{
[
88159,
66127,
...
]
}
fn right_data() -> [i32; 1000]{
return [
51481,
31794,
84893,
...
]
}
Once I had the list of numbers, computing the distance between the two lists via addition of the absolute value, and the similarity via multiplication was trivial.
fn main() {
// TODO: Read the lists from the file?
let mut left = left_data();
let mut right = right_data();
left.sort();
right.sort();
let mut distance = 0;
for idx in 0..1000 {
distance += (left[idx] - right[idx]).abs();
}
println!("{:?}", distance);
let mut similarity = 0;
for left_idx in 0..1000 {
let left_value = left[left_idx];
let mut scalar = 0;
for right_idx in 0..1000 {
if left_value == right[right_idx] {
scalar += 1;
}
}
similarity += left_value * scalar;
}
println!("{:?}", similarity);
}
As you can see from my initial code. I had a todo about wanting to read the input file from the dist. So, once I had submitted my solution, I spent the rest of my evening before going to bed noodling around and adding in the file IO with a domain driven design approach. I recently finished the book Domain Modeling Made Functional and it's been a fun challenge to represent things in a similar way. Let me show you some (very unneccesary) code for fun. First off, when we read in the data, we have to think about what can go wrong in doing so.
#[derive(Debug)]
enum DataError {
NoInputDataGiven,
CouldNotFindFile(String),
InvalidLeftData(String),
InvalidRightData(String)
}
We have four options for day 1's problems. The first two are if I screw up and don't pass in the file to the program, or if the file itself doesn't exist. The last two are actual errors in our data that could occur if the data we're given doesn't fit my expected reading of the solution space. Let's chat about interesting learnings from the first two.
I'm used to Java, Scala, C, and other C-like languages. So the usual way one gets arguments from the outside world into their program is through the classic ritual phrases such as
public static void main(String[] args)
Or the machine lore of
int main(int argc, char* argv[])
So, given that I've heard rust is also a systems language, I expected it to be similar to C. But surprisingly,
it reminds me of when I did CGI in 2014 since the way you access
variables is through std::env with an iterator. This isn't actually a bad thing, and it actually
feels pretty nice to write a small function like this:
fn get_filename_from_args() -> Result<String, DataError> {
let arguments: Vec<String> = env::args().collect();
if arguments.is_empty() {
return Err(DataError::NoInputDataGiven)
}
let mut arguments = arguments.iter();
arguments.next(); // skip the name of the program being ran
let maybe_filename = arguments.next();
match maybe_filename {
Some(filename) => {
if path::Path::new(filename).exists() {
Ok(filename.to_string())
} else {
Err(DataError::CouldNotFindFile(filename.to_string()))
}
},
None => Err(DataError::NoInputDataGiven)
}
}
For folks who have more than 7 days of experience in Rust, please don't chew me out for my use of String, I'm just following the compiler suggestions whenever it gives me an error. For folks who have less experience in rust than me, the logic should still be easy to read here. We get an iterator across all the arguments passed to the program, make sure that first argument is a filename that exists on the disk, and then we return the filename wrapped in an Result type if so. If anything goes wrong, we return one of the 2 error codes we defined before. This makes coding past midnight a bit easier since these error messages we can produce are easy for the tired brain to process:
$ ./day1.exe No input file given, please pass one as an argument! $ ./day1.exe input-day-1.txt.not.exists We could not find the file "input-day-1.txt.not.exists"
Our other two error codes can happen when we convert the string data into numerical data. To do this,
I wrote a little method called load_data_from_file that returns a Result of
either InputData or one of our DataErrors. The input data class is just a wrapper
that holds the two halves of the input data in itself. Following along with the domain driven design ideas,
I named the input data for the left and right lists with those terms:
#[derive(Debug)]
struct InputData {
left: Vec<LocationID>,
right: Vec<LocationID>,
count_by_right_location: HashMap<LocationID, i32>
}
#[derive(Debug, Clone, PartialOrd, Ord, PartialEq, Eq, Hash, Copy)]
struct LocationID {
id: i32
}
impl LocationID {
fn new(id: i32) -> LocationID {
return LocationID {
id: id
}
}
fn distance(self, other: &LocationID) -> i32 {
return (self.id - other.id).abs();
}
}
The problem statement also refers to the numbers in the lists as LocationIDs, so I made a struct for that as well. Wasteful? Maybe. Useful for having the code reflect how I'm thinking about it? Very much so. That said, this was my first day in this rust challenge, so I don't know all the functional methods to use so I dropped down to just plain procedural code to do the actual creation of these things:
fn load_data_from_file(filename: &String) -> Result<InputData, DataError> {
match fs::read_to_string(filename) {
Err(_) => Err(DataError::CouldNotFindFile(filename.to_string())),
Ok(contents) => {
let mut input_data = InputData::new();
let mut line: String = String::new();
for c in contents.chars() {
if c != ' ' && c != '\r' && c != '\n' {
line.push(c);
} else {
if line.is_empty() {
continue;
}
let is_left = c == ' ';
if is_left {
let value = match line.parse() {
Ok(good) => LocationID::new(good),
Err(_) => {
return Err(DataError::InvalidLeftData(line))
}
};
input_data.add_to_left(&value);
line.clear();
} else if c == '\n' {
let value = match line.parse() {
Ok(good) => LocationID::new(good),
Err(_) => {
return Err(DataError::InvalidRightData(line))
}
};
input_data.add_to_right(&value);
line.clear();
}
}
}
Ok(input_data)
}
}
}
The algorithm here is pretty simple. Since each line looks like 12 43 we know that
if we run into a space the characters we've collected so far should be parseable to become the left
number. If we hit a newline, then it's time to parse the data so far as the right number. if either
of those fail then we'll stop the whole shebang and return the line that's a problem to us.
$ ./day1.exe bad.txt We could not parse a value from the right list "bad" $ echo "wups 12" > bad.txt $ ./day1.exe bad.txt We could not parse a value from the left list "wups"
This is nice for someone programming at 12:30am on some large file they downloaded from the internet with the assumption that they didn't do anything wrong. If there's data that wasn't expected, it's nice to quickly see what the input that didn't parse was. With that method complete, we have all four errors available to us that we expect, as well as the success case, so the main method is simple to read:
fn main() {
let input =
get_filename_from_args()
.and_then(|filename| load_data_from_file(&filename));
let data = match input {
Err(data_error) => {
match data_error {
DataError::CouldNotFindFile(badfile) => {
println!("We could not find the file {:?}", badfile);
},
DataError::NoInputDataGiven => {
println!("No input file given, please pass one as an argument!");
},
DataError::InvalidLeftData(bad) => {
print!("We could not parse a value from the left list {:?}", bad);
},
DataError::InvalidRightData(bad) => {
print!("We could not parse a value from the right list {:?}", bad);
}
};
return;
}
Ok(data) => data
};
println!("{:?}", data.total_distance());
println!("{:?}", data.similarity());
}
The usefulness of the InputData method lets us break each operation up into
small chunks that fit into the domain of the silly elves asking us for help in the problem
statements. Attaching these methods to the struct, you can see we do a small optimization
for the similarity calculation when we build the data up.
fn add_to_left(&mut self, id: &LocationID) {
self.left.push(*id);
}
fn add_to_right(&mut self, id: &LocationID) {
self.right.push(*id);
self.count_by_right_location.entry(*id).and_modify(|count| { *count += 1 }).or_insert(1);
}
Since the similarity calculation needs to know how many times a number appears in the right side of the list, whenever we add to it, we fill up a hashmap with a running count. This lets us save a bit of time that the first solution we had didn't offer. Which is nice! Calculating the distance and similarity now looks like this:
fn total_distance(&self) -> i32 {
assert!(self.left.len() == self.right.len());
let mut left_copy = self.left.clone();
let mut right_copy = self.right.clone();
let mut distance = 0;
left_copy.sort();
right_copy.sort();
for idx in 0..left_copy.len() {
distance += left_copy[idx].distance(&right_copy[idx]);
}
return distance
}
fn similarity(&self) -> i32 {
let mut similarity = 0;
for location_id in &self.left {
similarity += self.count_by_right_location.get(&location_id)
.map(|scalar| location_id.id * scalar)
.unwrap_or(0)
}
return similarity
}
So, when I finished day 1 I felt like I had learned a bit of rust. My first solution was just loops and adding, then my second pass gave me a chance to leverage the standard library for a hashmap as well as fiddle around with enum types for error values.
Day 2 ↩
Day 2 was very much the same as day 1 as far as strategy went. I started with using sublime text to copy and paste the input numbers, and then multi-line cursored my way into converting this
74 76 78 79 76 38 40 43 44 44
Into this:
fn get_reports() -> Vec<Vec<i32>>{
return Vec::from([
Vec::from([74,76,78,79,76]),
Vec::from([38,40,43,44,44]),
...
])
}
The problem for day 2 was a variation on a typical interview problem3 We needed to make sure everything was increasing in value, or decreasing in value, but never doing both. And all without going each number being too far away from each one. Just like before, the force solution that came to mind is simple and small:
fn main() {
let reports = get_reports();
let mut num_safe_reports = 0;
for report in &reports {
if is_report_safe(&report) {
num_safe_reports += 1;
}
}
println!("{:?}", num_safe_reports);
}
fn is_report_safe(report: &Vec<i32>) -> bool {
if report.is_empty() {
return false;
}
if report.len() == 1 {
return true; // I think?
}
let mut differences = Vec::new();
for idx in 1..report.len() {
let difference = report[idx - 1] - report[idx];
differences.push(difference);
}
let is_within_range = differences.clone().into_iter().map(|d| d.abs()).all(|diff| diff > 0 && diff < 4);
let is_increasing_across_all = differences.clone().into_iter().all(|diff| diff < 0);
let is_decreasing_across_all = differences.clone().into_iter().all(|diff| diff > 0);
return is_within_range && (is_decreasing_across_all || is_increasing_across_all);
}
There's always the urge to be efficient and do things in one pass, but honestly, when it's 12:05am and you're learning a new language. It's better to just write out three iterations across an array and be done with it.
For part 2 we can tolerate a single bad item in the report. So, as the website says:
Now, the same rules apply as before, except if removing a single level from an unsafe report would make it safe, the report instead counts as safe.
Brute force is simple and easy. So, 12 minutes later I had a simple solution:
fn permute_report(report: &Vec<i32>) -> Vec<Vec<i32>> {
let mut permutations = Vec::new();
permutations.push(report.clone());
for idx in 0..report.len() {
let mut clone = report.clone();
clone.remove(idx);
permutations.push(clone);
}
return permutations;
}
Rather than checking is one report is valid, I'll just generate all the possible variations of the report without any given level in it, and then we update our main loop to allow any report with a valid permutation through:
let mut num_safe_reports = 0;
for report in &reports {
if is_report_safe(&report) {
num_safe_reports += 1;
} else {
let mut can_tolerate = false;
for foo in &permute_report(&report) {
can_tolerate = can_tolerate || is_report_safe(&foo);
}
if can_tolerate {
num_safe_reports += 1;
}
}
}
Simple. Easy. But, did I learn anything? Not really. I mean, I learned .remove and
.all exists for the iterator trait I guess. But besides that, this didn't give me
much to learn about. But day 2 being small and easy was fine. Because I didn't have the urge
to noodle until the next day.
Day 3 ↩
Now this was a fun problem. There was a trivially easy solution to this using regular expressions, and in fact, I could literally solve this with multi-cursors in my editor and a bit of editing to count things by hand. But the more fun solution is to use parser combinator type things like when I wrote markdown parsers for my site migration. That's a bit more work though, so I didn't want to do that right away since Advent of Code points are timed.
The first solution did teach me how easy it was to add in a library with cargo because I needed to bring in the RegEx library for this:
use regex::Regex;
fn original_answer() {
let data: String = ... read from file...
let r = Regex::new("(mul\\([0-9]{1,3},[0-9]{1,3}\\))|(do\\(\\))|(don't\\(\\))").unwrap();
let mut tokens = vec![];
for (_, [capture]) in r.captures_iter(&data.as_str()).map(|c| c.extract()) {
tokens.push(capture);
}
let mut answer = 0;
let mut enabled = true;
for token in tokens {
match token {
"do()" => enabled = true,
"don't()" => enabled = false,
mul => {
if !enabled {
continue;
}
let tuple = parse_mul(mul);
answer += tuple.0 * tuple.1;
}
}
}
println!("{:?}", answer);
}
fn parse_mul(str: &str) -> (i32, i32) {
let halves: Vec<_> = str.split(',').collect();
let first = halves[0].split('(').collect::<Vec<_>>()[1];
let second = halves[1].split(')').collect::<Vec<_>>()[0];
let f: i32 = first.parse().unwrap();
let s: i32 = second.parse().unwrap();
(f, s)
}
But it was after I had submitted my solution for part 1 and 2 that the fun started. Obviously, using the library to do this is the battle tested way to go. But if you're doing advent of code, you probably like to code. And writing parsers is fun. So, let's dive in.
First off, the input data has a whole bunch of garbage in it, looks similar to this:
<select()%:when()]@what(198,130)do()mul(364,266)*+)what(65,6)'mul(503where()
'{what()?mul(84,10)/;''^;mul(180,571)how()(]mul(804,566)>who()}]where()*%where()
?mul(909,630)%^where()how()'mul(678,912)*)+what():don't()*^[$mul(208,358)mul(99,216,??/-
So we need to filter out any garbage. To do this, I chose to ascribe meaning to a character or not.
This was easy to represent in the type system with enums. The meat of how we decide if something has
meaning or not is in the new method:
#[derive(Debug)]
enum SingleToken {
Meaningless,
HasMeaning(char)
}
impl SingleToken {
fn new(c: char) -> SingleToken {
match c {
'm' | 'u' | 'l' | '(' | ',' | ')' | '0'..='9' => SingleToken::HasMeaning(c),
'd' | 'o' | 'n' | '\''| 't' => SingleToken::HasMeaning(c),
_ => SingleToken::Meaningless
}
}
fn has_meaning(&self) -> bool {
match self {
SingleToken::Meaningless => false,
_ => true
}
}
fn value(&self) -> char {
match self {
SingleToken::HasMeaning(c) => *c,
SingleToken::Meaningless => '\0'
}
}
fn is_value(&self, value: &char) -> bool {
match self {
SingleToken::HasMeaning(c) => c == value,
_ => false
}
}
}
so, the first step in our processing is to convert from the string data input,
into a list of singular tokens. I learned on day 2 that there's a simple method called
chars to turn a string into the characters, so a quick map and we're good
to go:
let all_tokens: &[SingleToken] = &data.chars()
.map(|c| SingleToken::new(c))
.collect::<Vec<SingleToken>>();
The first instinct might be to filter to only leave behind meaning, but we would run the risk of
something like doxx() being accidently turned into a real action of do(). So instead, let's
figure out how to lift our single tokens that had meaning into tokens that contain the full list
of matching characters.
So, let's call a list of characters we've accumulated a compound token for lack of a better phrase. And in order to build one up, we need to match a pattern against the list of tokens we have available. If it's possible to match a string, or to match a given function, we'll return the token, if there's no match, then we'll return a null token:
#[derive(Debug)]
enum CompoundToken {
Null,
Token(Vec<char>)
}
impl CompoundToken {
fn lift(&self) -> Option<Vec<char>> {
match self {
CompoundToken::Null => None,
CompoundToken::Token(chars) => Some(chars.to_vec())
}
}
fn matches(token: &[SingleToken], string: &str) -> CompoundToken {
let num_tokens = token.len();
let num_chars = string.chars().count();
let mut chars = string.chars();
let mut matching = Vec::new();
for idx in 0..num_chars.min(num_tokens) {
match chars.next() {
None => return CompoundToken::Null,
Some(char_to_match) => {
if token[idx].is_value(&char_to_match) {
matching.push(char_to_match)
} else {
return CompoundToken::Null
}
}
}
}
return CompoundToken::Token(matching);
}
fn matches_func_while(tokens: &[SingleToken], f: fn(char) -> bool) -> CompoundToken {
let mut matching = Vec::new();
for token in tokens.iter() {
if token.has_meaning() {
if f(token.value()) {
matching.push(token.value());
} else {
break;
}
} else {
break;
}
}
if matching.is_empty() {
CompoundToken::Null
} else {
CompoundToken::Token(matching)
}
}
}
I suppose I could have written the code with just an Option and ignored the Null token, but
I made a lift() to convert anyway since that's where my head was at at the time.
The two important methods are matches and matches_func_while. Which
gave me an opportunity to find out how to pass a function to another function.
One of the things I like about rust so far is its compiler. And so, to figure out how to pass a function to another function, I didn't turn to the internet. Or even the rust book. I simply wrote this out:
fn foo(i: i32) {
println!("{}", i);
}
fn bar() {}
fn baz() {
foo(bar);
}
Then, I ran the compiler:
error[E0308]: mismatched types
--> C:\Users\Ethan\Documents\Code\Personal\learn-rust\aoc2024\day1.rs:14:6
|
14 | foo(bar);
| --- ^^^ expected `i32`, found fn item
| |
| arguments to this function are incorrect
|
= note: expected type `i32`
found fn item `fn() {bar}`
Which told me that the type of a function is fn so then I got to experiment a bit
and arrive at the correct signature of f: fn(char) -> bool all own my own.
Which felt good! So good, that I moved right along to the next part of my parsing solution.
The compand tokens are handy building blocks of what we're really trying to get to. Which is a
command for us to process.
#[derive(Debug)]
enum Command {
Mul(i32, i32, i32),
Do,
Dont,
}
impl Command {
fn consumed(&self) -> i32 {
match self {
Command::Do => 4,
Command::Dont => 7,
Command::Mul(_,_, tokens_used) => *tokens_used,
}
}
}
Now you can see the day 3 problem starting to emerge again. Like I said, the regex to get tokens was very simple and easy. But this one is more fun because going from first principles all the way up is satisfying to do. Just like in the website migration I linked above, we need to keep track of the amount of tokens used to construct the given command so we know how may tokens to skip past as we advance along out input.
With the Command type defined, we can start to parse the input. So, let's look at the
simplest case:
fn parse_do(tokens: &[SingleToken]) -> Option<Command> {
CompoundToken::matches(tokens, "do()").lift().map(|_| {
Command::Do
})
}
Easy right? Given a list of tokens, we can match for do() and if
the answer isn't None, then we return the Do command.
The don't parsing looks exactly the same but with one word changed. The more
interesting parse method is for the case of inputs like mul(2,45).
Because it's a bit more dynamic since the numbers can be 1 to 3 digits long.
fn is_digit_radix10(c: char) -> bool {
c.is_digit(10)
}
fn parse_m(tokens: &[SingleToken]) -> Option<Command> {
CompoundToken::matches(tokens, "mul(").lift().and_then(|_| {
let tokens = &tokens[4..];
CompoundToken::matches_func_while(tokens, is_digit_radix10).lift().and_then(|digits| {
let characters = digits.len();
if characters <= 0 || characters > 4 {
return None;
}
let first_digits: i32 = digits.iter().collect::<String>().parse().unwrap();
let tokens = &tokens[characters..];
let mut tokens_used: i32 = 4;
CompoundToken::matches(tokens, ",").lift().and_then(|_| {
let tokens = &tokens[1..];
tokens_used += 1;
CompoundToken::matches_func_while(tokens, is_digit_radix10).lift().and_then(|digits| {
let characters = digits.len();
if characters <= 0 || characters > 4 {
return None;
}
for _ in digits.iter() {
tokens_used += 1;
}
let second_digit: i32 = digits.iter().collect::<String>().parse().unwrap();
let skip = characters as usize;
let tokens = &tokens[skip..];
CompoundToken::matches(tokens, ")").lift().and_then(|_| {
tokens_used += 1;
Some(Command::Mul(first_digits, second_digit, tokens_used))
})
})
})
})
})
}
There's probably a better way to do this, but remember, I've been writing rust for 3 days for 2 hours or so at a time at most. So the fact that I'm able to get something that actually works and doesn't feel like spaghetti at the moment is pretty good. But what feels really good is the code where we use these parsers. Because it reads very cleanly.
let mut tokens = vec![];
let mut tokens_cursor = all_tokens.iter();
loop {
if tokens_cursor.len() == 0 {
break;
}
let token = parse_dont(tokens_cursor.as_slice())
.or(parse_do(tokens_cursor.as_slice()))
.or(parse_m(tokens_cursor.as_slice()));
match token {
Some(token) => {
let advance_by = token.consumed();
tokens.push(token);
for _ in 0..advance_by {
tokens_cursor.next();
}
}
None => {
tokens_cursor.next();
},
}
}
I feel like there's probably a way to do the multi-token advancement better. But I couldn't seem to win the battle against the borrow checker when I tried a few other things, so I went for the simple solution above. The above code gives us a list of commands. So, much like in the original solution where we matched against each token, we match against each command to our little machine:
let mut answer = 0;
let mut enabled = true;
for token in tokens {
match token {
Command::Do => enabled = true,
Command::Dont => enabled = false,
Command::Mul(fst, snd, _) => {
if !enabled {
continue;
}
answer += fst * snd;
}
}
}
println!("{:?}", answer);
And we've basically arrived at the same solution we had before, just implemented in a different way, but with no reliance on a regular expression. If the problem had kept going and told us to pull out more data from the input and create new commands, we'd be able to update our types and commands to handle it. It was a lot of fun, and while I used the regex one to submit, the noodling around and fiddling with making a parser was done in the off hours over the course of some of the other games and was really enjoyable.
Day 4 ↩
The next day, for better or worse, didn't spark the same joy as day 3's opportunity for parsing fun.
Day 4 involved a matrix, and it was not the kind of thing that my brain likes to visualize.
Part 1 of the problem was to find the word XMAS in a matrix of characters. It could be
going up, down, left, right, and diagonally forwards or backwards. And 4 of these weren't
hard, I was getting the right answer for part of it an hour in when I realized that I could just
collect a column, then reverse it to do the checks for up and down forwards and backwards. Same for
the rows to get the left and right cases.
The problem of course was the diagonals. My initial solution for the diagonal missed a segment of the matrix by accident. So I had to break it out into seperate collection steps because I couldn't do it in one pass. Like I said, this one wasn't sparking joy, but rather frustration.
// Diagonal directions ARE SO DAMN CONFUSING TO THINK ABOUT
for start_row in 0..rows {
// Down-right diagonal from left column
let mut diag = String::new();
let mut offset = 0;
while start_row + offset < rows && offset < cols {
diag.push(matrix[start_row + offset][offset]);
offset += 1;
}
going_diagonal.push(diag.clone());
going_diagonal.push(diag.chars().rev().collect());
}
for start_col in 1..cols {
// Down-right diagonal from top row
let mut diag = String::new();
let mut offset = 0;
while offset < rows && start_col + offset < cols {
diag.push(matrix[offset][start_col + offset]);
offset += 1;
}
going_diagonal.push(diag.clone());
going_diagonal.push(diag.chars().rev().collect());
}
for start_row in 0..rows {
// Down-left diagonal from right column
let mut diag = String::new();
let mut offset = 0;
// note: we can go negative with these offsets, so we have to convert to isize first for those calcs
while start_row + offset < rows && cols as isize - 1 - offset as isize >= 0 {
diag.push(matrix[start_row + offset][(cols as isize - 1 - offset as isize) as usize]);
offset += 1;
}
going_diagonal.push(diag.clone());
going_diagonal.push(diag.chars().rev().collect());
}
for start_col in (0..cols - 1).rev() {
// Down-left diagonal from top row
let mut diag = String::new();
let mut offset = 0;
while offset < rows && start_col as isize - offset as isize >= 0 {
diag.push(matrix[offset][(start_col as isize - offset as isize) as usize]);
offset += 1;
}
going_diagonal.push(diag.clone());
going_diagonal.push(diag.chars().rev().collect());
}
If there was a whiteboard to look at, there'd be a whole bunch of lines, X's, and blood from where I would have been banging my head against it while I visualized the offsets and steps to take to figure out how to collect each diagonal forwards and backwards without going crazy.
And that was all just part 1. The sad thing of course is that this was very much like real life work when you read the part 2 intro.
The Elf looks quizzically at you. Did you misunderstand the assignment?
Looking for the instructions, you flip over the word search to find that this isn't actually an XMAS puzzle; it's an X-MAS puzzle in which you're supposed to find two MAS in the shape of an X
Which is so much easier than what we had just done. Like. SO much easier. Look at this.
fn main () {
let raw_data = fs::read_to_string("./input-day-4.txt").expect("bad input data");
let matrix: Vec<Vec<char>> = raw_data
.lines()
.filter(|line| !line.is_empty())
.map(|line| line.chars().collect())
.collect();
let rows = matrix.len();
let cols = matrix.get(0).map(|m| m.len()).unwrap_or(0);
let mut count = 0;
for y in 1..rows - 1 {
for x in 1..cols - 1 {
if matrix[y][x] == 'A' {
// Just brute force it with a lookup around us
/* M M M S S M S S
* A A A A
* S S M S S M M M
*/
let top_left_to_bottom_right = matrix[y - 1][x - 1] == 'M' && matrix[y + 1][x + 1] == 'S';
let bottom_left_to_top_right = matrix[y + 1][x - 1] == 'S' && matrix[y - 1][x + 1] == 'M';
let case_1 = top_left_to_bottom_right && bottom_left_to_top_right;
let top_left_to_bottom_right = matrix[y - 1][x - 1] == 'M' && matrix[y + 1][x + 1] == 'S';
let bottom_left_to_top_right = matrix[y + 1][x - 1] == 'M' && matrix[y - 1][x + 1] == 'S';
let case_2 = top_left_to_bottom_right && bottom_left_to_top_right;
let top_left_to_bottom_right = matrix[y - 1][x - 1] == 'S' && matrix[y + 1][x + 1] == 'M';
let bottom_left_to_top_right = matrix[y + 1][x - 1] == 'S' && matrix[y - 1][x + 1] == 'M';
let case_3 = top_left_to_bottom_right && bottom_left_to_top_right;
let top_left_to_bottom_right = matrix[y - 1][x - 1] == 'S' && matrix[y + 1][x + 1] == 'M';
let bottom_left_to_top_right = matrix[y + 1][x - 1] == 'M' && matrix[y - 1][x + 1] == 'S';
let case_4 = top_left_to_bottom_right && bottom_left_to_top_right;
if case_1 || case_2 || case_3 || case_4 {
count += 1;
}
}
}
}
println!("part 2 {:?}", count);
}
Literally took me 5 minutes. When I finished day 4, I was happy to move on and go back to noodling with day 3's parser fun. Still. If there's one thing day 4 gave me, I suppose I'm feeling more confident with the lists in rust. Which seems important considering how all of these problems seem to involve parsing lists.
Day 5 ↩
Day 5 was way more fun that day 4 was. The first part 1 was satisfying to write up, and even more satisfying when I got the answer to part 1 on my first try.
The problem being solved for Day 5 was pretty straightforward. You're given a list of rules as well as a list of reports. Each report is just a CSV of numbers. So the input looks something like this:
47|53 75,47,61,53,29
Each rule simply states which number should be first in the list. Then, we have to check if the report satisfies those rules. So, in this case, since 47 must be before 53, the report would be valid. Then lastly, once you had all the valid reports known, you needed to select the middle number from each and then add them up. You can probably guess what part 2 was. Using the rules to fix incorrect reports, and then finding the middle number of those invalid reports to add up.
For my solution to day 5, I did a bit of a mix of the domain driven stuff I went hard on in the first couple of days and the more practical approaches of day 3 (before the parsing) and day 4. For converting the input data into the rules, I leveraged the handy methods on the iterator traits and the Vec class:
fn build_ordering(raw_data: &str) -> Vec<(i32, i32)> {
let ordering: Vec<(&str, &str)> = raw_data
.lines()
.take_while(|line| !line.is_empty())
.map(|raw| {
let raw: Vec<&str> = raw.splitn(2, "|").collect();
(raw[0], raw[1])
})
.collect();
let ordering: Vec<(i32, i32)> = ordering.iter()
.map(|(fst, snd)| {
let fst: i32 = fst.parse().expect("Failed to parse first number");
let snd: i32 = snd.parse().expect("Failed to parse second number");
(fst, snd)
}).collect();
ordering
}
This was basically leveraging what I had learned in the previous days and was pretty quick to write up. The only thing to note is that between the rules and reports there's a single empty line. So when it came to parsing the reports, we have to advance past that first since I broke up the parsing into two methods:
fn build_reports(raw_data: &str) -> Vec<Report> {
let mut reports: Vec<Report> = Vec::new();
let mut past_rules = false;
for line in raw_data.lines() {
if !line.is_empty() && !past_rules {
continue;
}
if line.is_empty() && !past_rules {
past_rules = true;
continue;
}
let report = line.split(",").map(|no| {
let number: i32 = no.parse().expect("Non-digit in input?");
number
}).collect();
reports.push(Report { data: report });
}
reports
}
The type I'm bulding a vector of in this case is that DDD being applied again. And I'm liking this pattern of writing code. It satisfies the urge to write Java for me pretty well. Which you don't really think you'd see when dealing with a language that's commonly associated with C and other systems programming languages. Anyway, waxing aside. Here's the report struct and its helper methods that make the problem solving easier:
#[derive(Debug)]
struct Report {
data: Vec<i32>
}
impl Report {
fn is_valid_according_to(&self, ordering: &[(i32, i32)]) -> bool {
let mut valid = true;
for idx in 0..self.data.len() {
let report = self.data[idx];
let ordering = ordering.iter().filter(|o| o.0 == report);
let must_appear_after: Vec<i32> = ordering.map(|o| o.1).collect();
for order in must_appear_after.iter() {
match self.data.iter().position(|&r| r == *order) {
None => {}, // If the right side is not in the report then ignore it.
Some(location) => {
valid = valid && idx < location;
}
}
}
}
valid
}
fn middle_number(&self) -> i32 {
let mid = self.data.len() / 2;
self.data[mid]
}
fn re_order_according_to(&self, ordering: &[(i32, i32)]) -> Report {
let mut new_data = self.data.clone();
new_data.sort_by(|a,b| {
for (before, after) in ordering.iter() {
if a == before && b == after {
return Ordering::Less
} else if b == before && a == after {
return Ordering::Greater
}
}
Ordering::Equal
});
Report { data: new_data.clone() }
}
}
The only method that took some extra time to figure out was re_order_according_to
method. Using the sort_by method is the way to go, but my initial implementation
did a disgusting brute force approach like this:
fn re_order_according_to(&self, ordering: &Vec<(i32, i32)>) -> Report {
let mut new_data = self.data.clone();
let mut idx = 0;
let mut new_report = Report { data: new_data.clone() };
loop {
if new_report.is_valid_according_to(ordering) {
break
}
for idx in 0..new_data.len() {
let report = new_data[idx];
let must_appear_after: Vec<i32> = ordering.iter().filter(|o| o.0 == report).map(|o| o.1).collect();
let report_position = new_data.iter().position(|&r| r == report).expect("This exists");
let mut should_be_to_the_right_positions: Vec<usize> = must_appear_after.iter().map(|o| {
new_data.iter().position(|&r| r == *o)
}).filter(|p| p.is_some()).map(|p| {
p.unwrap()
}).collect();
should_be_to_the_right_positions.sort();
if should_be_to_the_right_positions.is_empty() {
// There are no rules for this report, so skip ahead.
continue;
}
let smallest = should_be_to_the_right_positions[0];
new_data.remove(report_position);
new_data.insert(smallest, report);
}
idx += 1;
if idx == new_data.len() {
idx = 0;
}
new_report = Report { data: new_data.clone() };
}
new_report
}
It worked but man did I feel bad about it. But also, it was 1:49am and I had work in the morning. So, I think brute forcing an answer out is fine under such conditions. Refactoring to use the sort by method was done after work the same day. After a good sleep. I do ok at midnight, but the looming requirement to go to bed and not be too tired for work in the morning does start rearing its head at 1:30am. So, we make do.
All that said, day 5 was fun. It was a problem I understood how to do, and then coming up with the solution was feeling pretty good since it applied things I'd learned in rust for the past few days. This really does feel like a great way to learn a language, though I wonder if I'll need to learn more than just how to abuse the list related types. Then again, maybe I shouldn't be asking for that, not sure if I want to be awake at December 25th at 3am trying to figure out some obscure algorithm in rust.
Day 6 ↩
Now, I had had fun with Day 3. The noodling was great. Day 5 was satisfying. But day 6? Day 6 was inspiring. It's been a little while since I thought of a fun idea for something I was working on and actually had the motivation to turn an off hand comment that I said to someone of "hey that'd be neat if..." into an actual thing I could share.
But I'm getting ahead of myself. Let's talk about the silly little problem for day 6!
The problem for day 6 is one that the hardcore computer scientists of the world would probably read and think: "Aha, yes, a graph problem! Let me reach for my knuth book!" Or similar. There's a guard on a grid. The guard walks along a path in the world, and eventually leaves this mortal plane after he's finished walking forward and turning right any time he runs into something.
The goal of the problem for part 1 is to count how many steps it takes for the guard to leave the area so that the elves you're with can then run along to do whatever they need to do. Part 2 was playing a trick on the guard to get him stuck in a loop, then telling the elves how many diferrent ways they could do this. It's all fun and games and you could graph it all up and make a nice efficient solution to this with some applied CS.
But... why use the smart way of solving this problem when instead we can do something a bit more fun? A bit more related to my recent stints into game development Let's simulate the guard's actions instead!

As you can see above, the guard is represented by the characters ^<>v
depending on which direction they're moving. They walk forward until they hit a #
character, at which point they turn right and repeat. Once they walk out of bounds of the array
they're done and so are we.
As far as modeling the input data, this was pretty straightforward with rust's type system. In fact, it reminded me of what I would do in scala for some things. Which is very good, considering that scala is one of my favorite languages. But before our guard can exist, we need a world for him to live in.
fn make_matrix(raw_data: &str) -> (Vec<Vec<char>>, usize, usize) {
let matrix: Vec<Vec<char>> = raw_data
.lines()
.filter(|line| !line.is_empty())
.map(|line| line.chars().collect())
.collect();
let rows = matrix.len();
let cols = matrix.get(0).map(|m| m.len()).unwrap_or(0);
(matrix, rows, cols)
}
The worlds just a simple MxN matrix, so the parsing chops we've learning from the previous day were very applicable for copy and pasting. Next, in order to simulate the guard we need to know where the guard starts. There's no guarantee which way the guard is facing in our input data, or at least, I'm not making any assumptions. So I wrote a quick helper to confirm that a character in the matrix is our guard:
fn is_guard(c: &char) -> bool {
let g = vec!('^', '>', '<', 'v');
g.iter().find(|&symbol| c == symbol).is_some()
}
Then in the main code for part 1, we just iterate to find him and keep track of his position with a tuple:
let mut guard_position = (0, 0);
for row in 0..rows {
for col in 0..cols {
if is_guard(&matrix[row][col]) {
guard_position = (row, col);
}
}
}
Now back to thinking about modeling, the guard is going to move in a specific direction. And we need to encode how they change based on that. So, the first thing that came to mind for me was to declare an enum type for the direction.
#[derive(Debug, Clone)]
#[derive(PartialEq, Eq)]
enum Direction {
Up, Down, Left, Right
}
impl Direction {
fn of(guard: &char) -> Option<Direction> {
match guard {
'>' => return Some(Direction::Right),
'<' => return Some(Direction::Left),
'v' => return Some(Direction::Down),
'^' => return Some(Direction::Up),
_ => return None,
}
}
fn turn_right(&self) -> char {
match self {
Direction::Right => 'v',
Direction::Left => '^',
Direction::Down => '<',
Direction::Up => '>',
}
}
fn is_self(&self, other: &Direction) -> bool {
self == other
}
fn to_char(&self) -> char {
match self {
Direction::Right => '>',
Direction::Left => '<',
Direction::Down => 'v',
Direction::Up => '^',
}
}
}
You know what didn't come to mind to someone who's only been programming in rust for
6 days so far? Those #[derive] bits. The compiler really does a lot of heavy lifting
in teaching me things. Though I do really want to make an implementation of the various traits we're
letting it make for us to I can understand the internals. But a speed race to the solution type thing
like advent of code doesn't quite lend itself to that on your first submission. So, if the compiler
says "So and so type doesn't implement Thing trait, try adding in #[derive(Thing!)]" I go ahead and do it.
Armed with our direction type, the matrix, and our guard's position. We're pretty close to being able to solve the problem. I wrote a couple more helpers, checking if a charactor is an obstacle, if the guard's position is out of bounds or not. None of those are interesting so I'll elide them. But out main simulation loop is a method that returns either None if a cycle is detected, or a count of how many steps it took for the guard to leave.
let visited_marker = 'X';
let floor = '.';
let mut path_marked = matrix.clone();
let mut obstacles_hit_count = init_cycle_detector(rows, cols); // just a [][] matrix of 0s
loop {
if guard_has_left(rows, cols, guard_position) {
break;
}
let direction = Direction::of(&matrix[guard_position.0][guard_position.1]).unwrap();
let (newRow, newCol) = match direction {
Direction::Left => (guard_position.0, (guard_position.1 as isize - 1) as usize),
Direction::Right => (guard_position.0, guard_position.1 + 1),
Direction::Up => ((guard_position.0 as isize - 1) as usize, guard_position.1),
Direction::Down => (guard_position.0 + 1, guard_position.1),
};
if guard_has_left(rows, cols, (newRow, newCol)) {
path_marked[guard_position.0][guard_position.1] = visited_marker;
guard_position.0 = newRow;
guard_position.1 = newCol;
continue;
}
if is_obstacle(&matrix[newRow][newCol]) {
if obstacles_hit_count[newRow][newCol].iter().any(|d| d.is_self(&direction)) {
// cycle! We walked into the same obstacle in the same direction!
// Note it's okay to walk into it from a different direction though.
return None;
}
obstacles_hit_count[newRow][newCol].push(direction.clone());
matrix[guard_position.0][guard_position.1] = direction.turn_right();
continue;
}
matrix[guard_position.0][guard_position.1] = floor;
path_marked[guard_position.0][guard_position.1] = visited_marker;
guard_position.0 = newRow;
guard_position.1 = newCol;
matrix[guard_position.0][guard_position.1] = direction.to_char();
}
let mut distinct_positions_count = 0;
for row in 0..rows {
for col in 0..cols {
if path_marked[row][col] == visited_marker {
distinct_positions_count += 1;
}
}
}
Some(distinct_positions_count)
One thing I learned from the awfulness of Day 3's diagonal counting was the use of isize
to do negative offset calculations. Which was useful knowledge when it came to moving the guard up
and left during the calculations of newRol, newCol. Besides that the solution is clear.
If the guard walks into the same obstacle from the same direction more than once, then they're stuck in a cycle, so we can return immediately. Otherwise, if we mark the path that the guard has walked with an X each time they take a step, then we end up with as many X's as steps the guard took. Easy.
But... this wasn't enough honestly. Simulating the guard was neat. It tickled my brain. And, when sharing my joy with another tech enthusiast he gave me a bonus challenge.
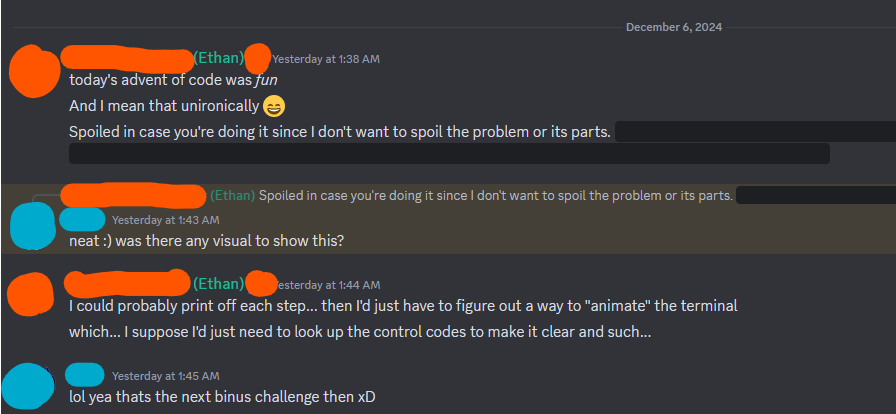
A visual huh? Well. It's not hard to print off the matrix. Though, the size of the REAL input for the day's challenge is 130 characters wide and tall. So that won't fit comfortably onto the screen. So, we need to write a little helper method to print off the grid, then add it into each step of the simulation. Doing this, then piping the output to a file will give us a bunch of "frames" we can then render out to the terminal to act as our animation. Here's my first attempt, which does have a small bug in it. More on that in a second.
fn print_centered_view(grid: &Vec<Vec<char>>, x: usize, y: usize, n: usize) {
let rows = grid.len();
let cols = grid[0].len();
let half_n = n / 2;
// Calculate the start and end indices for rows and columns, clamping to valid ranges.
let row_start = x.saturating_sub(half_n);
let row_end = (x.saturating_add(half_n + 1)).min(rows);
let col_start = y.saturating_sub(half_n);
let col_end = (y.saturating_add(half_n + 1)).min(cols);
for row in row_start..row_end {
for col in col_start..col_end {
print!("{}", grid[row][col]);
}
println!();
}
println!()
}
Not to hard to understand right? And it produces a result like this when we have the guard walk the big board.
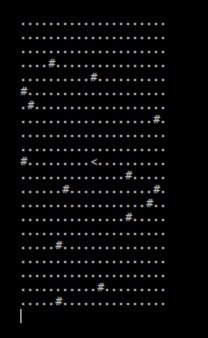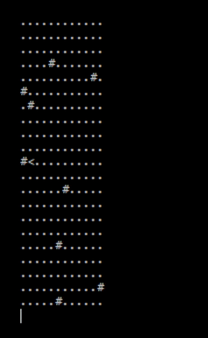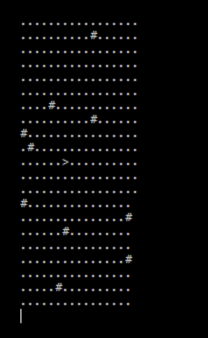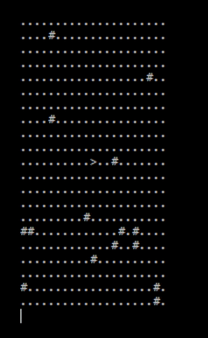
See the bug? This only happens when we're near the edge of the board because my first shot at the printing doesn't add in extra padding if the guard doesn't have at least half of the given n around them to print. It doesn't crash thanks to the saturating add, but we can solve this problem pretty quickly by just adding in the difference as padding.
fn print_centered_view(grid: &Vec<Vec<char>>, x: usize, y: usize, n: usize) {
let rows = grid.len();
let cols = grid[0].len();
let half_n = n / 2;
// Calculate the start and end indices for rows and columns, clamping to valid ranges.
let row_start = x.saturating_sub(half_n);
let mut row_padding = 0;
if x < half_n {
row_padding = half_n - x;
}
let row_end = (x.saturating_add(half_n + 1 + row_padding)).min(rows);
let col_start = y.saturating_sub(half_n);
let mut col_padding = 0;
if y < half_n {
col_padding = half_n - y;
}
let col_end = (y.saturating_add(half_n + 1 + col_padding)).min(cols);
for row in row_start..row_end {
for col in col_start..col_end {
print!("{}", grid[row][col]);
}
println!();
}
println!()
}
And then the generated output no longer truncates the right side:

So how am I actually generating that little animation? Another rust program to parse the animation frames of course!
use std::fs;
use std::{thread, time};
fn main() {
let raw_data = fs::read_to_string("anim.txt").expect("bad input data");
let raw_data = raw_data.as_str();
let lines = raw_data.lines();
let delay_between_frames = time::Duration::from_millis(42);
let mut buffer = String::new();
for line in lines {
if line.is_empty() {
print!("\x1B[2J\x1B[H");
print!("{}", buffer);
std::io::Write::flush(&mut std::io::stdout()).unwrap();
thread::sleep(delay_between_frames);
buffer.clear();
}
buffer.push_str(line);
buffer.push_str("\n");
}
print!("\x1B[2J\x1B[H");
print!("{}", buffer);
std::io::Write::flush(&mut std::io::stdout()).unwrap();
thread::sleep(time::Duration::from_millis(1000));
}
Easier than you might have expected huh? This of course is because I'm not actually doing any "real" video making here. I just obs to record my terminal window while the program runs and that's good enough for me. It'd be interesting to dig in and learn about how one might create an actual video formatted file from some ascii art, but I think that might be a bit beyond me at the moment. For now, I'm pretty content with the fact that I made a way to visualize the day 6 scenario.
So content that I made a little youtube video of the guards full journey on his way to leave the warehouse here and escape from those pesky elves here. It was fun, and definitely my favorite advent challenge so far.
Day 7 ↩
Day 7 was another day to be won by DDD and the type system. Or at least, in that it made converting the part 1 solution into the part 2 solution absolutely trivial. It literally took me 5 minutes according to the time I reported my success in a discord channel until I posted again saying I was done.
Day 7's problem was another fun challenge, with a singular point of difficulty. Optimization. The input to the problem is a simple list again:
190: 10 19 3267: 81 40 27
The number before the : is the expected value of calibration list. The numbers
to the right of the : are the calibrations. However, all the operators between
the numbers were stolen. So, it's up to us to add + and * operators
between the numbers and apply them left to right to see if a combination exists where one can
get the expected value.
So, well, for two inputs, we only have to test two operands. That's easy. What about three
calibrations in the list? Well, there's 81+40+27, 81+40*27,
81*40+27, and 81*40*27. Well, that sure is a pattern that looks
a lot like 2 n operations where n is the number of operands we have to insert. What's the
largest list of numbers in our input? 12? So, that's 11 operands so that's only 2048 potential
configurations of operands to try...
But that said, the permutations of the operands for each number list is fixed. Like, if you have
a list of 10 19 and 20 21 it's not like you need to generate the 2
combinations of plus and multiply more than once. We can just precompute the permutations and then
apply them to the list. Or, to save a little bit of space for a while, we can lazily compute the
permutations and then cache them as we process.
So, let's define our operands!
#[derive(Debug, Clone, Copy)]
enum Operand {
Plus,
Multiply,
}
impl Operand {
fn apply(&self, left: &u64, right: &u64) -> u64 {
match self {
Operand::Plus => left + right,
Operand::Multiply => left * right,
}
}
}
Then we can do this the bad way, or the easy way. I opted for the bad way first because I didn't google for libraries that can permute lists until after I had submitted my solution. It was slow, but it did the job. For reference, I parsed and stored each line of data's model into this
#[derive(Debug, Clone)]
struct Calibration {
result: u64,
numbers: Vec<u64>
}
and then in the struct's impl block the code to figure out the list of potential operands
to try to apply was this.
fn get_operator_combinations(&mut self, permutation_cache: &mut HashMap<usize, Vec<VecDeque<Operand>>>) -> Vec<VecDeque<Operand>> {
let combinations = generate_combinations(&[Operand::Plus, Operand::Multiply], operators_needed);
permutation_cache.insert(operators_needed, combinations.clone());
return combinations
}
fn generate_combinations(symbols: &[Operand], n: usize) -> Vec<VecDeque<Operand>> {
// return nothing to add,
// when n = 1 this will end up with [Operand]
// when n = 2 this will have [Operand, Operand]
// n = 1 will vary between the different operands, so by concatenating
// the bits together, we can build up the different combos.
if n == 0 {
return vec![VecDeque::new()];
}
let mut result = Vec::new();
for symbol in symbols {
let sub_combinations = generate_combinations(symbols, n - 1);
for mut sub in sub_combinations {
sub.push_front(*symbol);
result.push(sub);
}
}
result
}
As the comment says, basicaly at each position of n, we vary the given operands and
construct a vector of that in addition to the permutations from n - 1. It does the job, but
the method itertools::repeat_n(o, operators_needed).multi_cartesian_product().collect();
is much faster. Though this does require a 3rd party library. But the gains are huge. The combination
of caching the operands into the HashMap and using the itertools library dropped my execution time
from 26s to 7s for part 2.
26 seconds you say? Yes, well, part 2 was trivial to implement, but it blew up our problem space a bit. The request was simple: add another operand!
enum Operand {
Plus,
Multiply,
Concat,
}
impl Operand {
fn apply(&self, left: &u64, right: &u64) -> u64 {
match self {
Operand::Plus => left + right,
Operand::Multiply => left * right,
Operand::Concat => (left.to_string() + &right.to_string()).parse().unwrap()
}
}
}
I'm not kidding. That was all I had to do to handle part 2. Why? Because my program was setup really nicely. The main loop that's actually solving the problem is this:
fn main() {
let raw_data = fs::read_to_string("./input.txt").expect("bad input data");
let mut calibrations: Vec<Calibration> = raw_data.lines().map(|line| {
Calibration::from(line)
}).collect();
let mut permutation_cache = HashMap::new();
let total_values_from_valid_calibrations = calibrations.iter_mut().fold(0, |accum, calibration| {
let operator_combinations: Vec<VecDeque<Operand>> = calibration.get_operator_combinations(&mut permutation_cache);
let mut has_valid = false;
for operators in operator_combinations {
has_valid = has_valid || calibration.is_valid_with(operators);
}
if has_valid {
accum + calibration.result
} else {
accum
}
});
println!("{:?}", total_values_from_valid_calibrations);
}
As you can see, we're doing the usual parsing and converting the strings into our problem domain in the first step. Then for each of the calibrations, we're getting a list of operators that are then checked for validity4. Assuming that one of the calibrations and operator combination is valid, then we can add up the result. Otherwise we skip it. Verifying that an operator list works for the calibrations is trivial:
fn is_valid_with(&self, mut operands: VecDeque<Operand>) -> bool {
if self.numbers.is_empty() || operands.is_empty() {
return false
}
let mut nums = self.numbers.clone().into_iter();
let mut left = nums.next().unwrap();
for _ in 0..nums.len() {
let right = nums.next().unwrap();
let operator = operands.pop_front().unwrap();
left = operator.apply(&left, &right);
}
self.result == left
}
This method is why I'm using the VecDeque class by the way. Regular iterators
don't seem to have a good way to get the front of the damn list without shifting everything
inside of it over by one. I'm probably missing something, but remember that this is day 7 of
learning rust through these problems. So it's not like I'm well-versed yet and I definitely
am getting screwed up by a number of things.
But more on that in a minute. For now, the fact that we just added an operand in means that the number of permutations has increased to 311, which is 177147. That's a lot more than 2048. Even though it took a few seconds to get part 2's solution correct, it takes a lot longer to compute it. So, optimization's are the name of the game. When I first ran my code, I had my handrolled permute method and wasn't caching the operands.
Heck, even when
I started caching the operands I mistakenly stored them in the Calibration struct
itself. Doing just this still dropped me from 26s to 14s though. And then
it was the move
to cache the operand permutations globally that dropped me down to 10s. My last speed up
was had from swapping to itertools and I landed at a reasonable 7 and a half seconds or so
to figure out the elves little problem.
It was fun, though I didn't have any sort of opportunity like day 6 to make a neat visualization
or anything. It was still another chance to learn something new. On Day 7 I learned that the
mut keyword can not only apply to the variable or argument, but also the the type
of the value itself. Trying to pass the hashmap for the cache around taught me this. But man, the
borrow checker was getting really mad at me for a while.
What have I learned? Thoughts on rust? ↩
Well, so far so good. I'm liking rust for this advent of code challenge, and it's fun to use
a language that reminds me of Scala with its type system, but also invokes the feeling I used
to get when writing C api's for fun. Low level
stuff is enjoyable to work with, and rust does a good job of making segfaults rare and the
cause of my own unwrap() calls as oppose to something unexpected or hidden away.
That said, there are things that make me feel like Sideshow Bob walking into rakes. To list a few:
-
variable matchversusmatch variablesyntax. I'm used to scala's style. - match arms end in commas, or require {}, unlike scala's inteligent whitespace for oneliners
- parenthesis discouraged around if statement conditionals
- snake_case and not camelCase
- & references, *dereference, wait which is borrowing again, huh?
-
method naming such as
is_nonein Option and nois_emptymethod. In Scala the interface to monadic type things is consistent. It's not in rust and it's annoying. Similar, in Scala the convention for constucting Options is to always useOption(var)because it lifts null toNonewhileSome(null)will give you aSome. It throws me off that I'm required to say Some. -
The function body syntax for things like mapping not having an arrow of some kind.
.map(|x| x + 1)feels awkward compared to.map { x => x + 1 }, the second is how you could do it in Scala. -
I keep forgetting the
if letsyntax and when to use it. Same with what has a?operator and what doesn't and if I should even use it. -
No ternary operator? I think things like
let x = if {} else {}look ugly and is something I actively avoid doing in my scala code, so it's bothersome to see it somewhere else. -
Along the same vein, That the clippy linting complains about
return foo;and tells you to write justfoois something I don't like. Just having a variable loose on its own feels strange and weird. Scala also has the "return the last thing in the method" behavior, but it doesn't use a semicolon to denote that. Scala handles it in the method signature withdef foo = {}returning whatever the last statement's type is versusdef foo {}which returns unit.
Sorry for all the rust fans out there who are sick of me comparing this to Scala, but it's my point of reference and I quite like the language. Martin Oderskyy's done a great job making a consistent and powerful world in the JVM and that strong guiding hand and consistency feels like it's missing in the rust world. I could be wrong, maybe Scala's the odd one out and rust is following along in the foot steps of haskell, ocaml, and others. But these are just my thoughts after spending a week with rust.
I will say that cargo is nice. The fact that it just works on windows without too much hassle 5 makes me pretty happy. Like, install dust or ripgrep on windows the same way you would install it on linux or mac? Awesome. What's not great about cargo is that my build command for sublime text 4 doesn't handle it at the moment. That's a me problem, not cargo's. But I just haven't bothered to set up a custom build in ST4 yet since it has rust built in for regular rustc building.
As far as advent of code goes? It's mostly great. I do see some people in discord channels I'm in already tiring of "read this file of numbers, do thing", but I'm hopeful that maybe more problems will be like day 6's where we have the option to simulate something. We'll see. I'm enjoying the social aspect of finding other people who are doing AoC challenges and sharing code with them. It's fun to learn from other people's code, and interesting to see the academic versus the bruteforce, versus the insane6 things like people writing solutions using glsl to calculate the answer on their GPU. It's a lot of fun, and it's inspiring to me.
We'll see if I write up another one of these thoughts and solutions posts next week. But at the very least, if I keep up with AoC for all 25 days, then I'll probably write up a blog post at the end if there's something I feel is worth sharing with the greater internet. Happy coding!