The plan ↩
Turns out that this is actually a hard problem in CS and requires a lot of linguistics knowledge, research, and crazy domain knowledge to really truly "solve". But... my needs are small, and so we're going to start small with my own simple ideas. So, here's the plan:
- parse a dictionary of words to phonemes
- ignore the actual phonems and get a basic "flap" of the mouth going per word. So, 1 syllable = 1 flap
- emit or display this information in some trivial way
- create basic mappings without going too crazy to convert the simple flap to some mouth shapes and flaps
I think this should be a small enough vision and a good enough breakdown of the steps that I can walk through this. So, let's start!
Parsing the dictionary ↩
While talking in that discord I mentioned, I ended up finding a good stack overflow post about finding rhymes which linked to a handy cargenie mellon page. Carnegie Mellon pronouncing dictionary which helpfully is a "open source machine readable pronounciation dictionary" that contains a bunch of entries indicating lexical stress and 39 potential phonemes. For example:
SECTOR S EH1 K T ER0
As you can see, the word "sector" has both a primary stress on the first e, and no stress on the last R according to this definition. And, my own observation, the number of vowels in this match to how many syllables there are.
CHEESE CH IY1 Z
Cheese is one syllable even if it is a bit elongated when you say it, and has one vowel in the phoneme match. While I'm not 100% sure this observation is going to hold, my intuition thinks it's at least an approximation that will be accurate most of the time, so I think we'll start there when we try to figure out the flaps. But of course, first we need a parser for this data.
As per usual, let's do this in rust since it relates, potentially, to the sentimentuber project. Thankfully during my advent of code experience we wrote a lot of string manipulation and parses, so this should be straightforward!
$ cargo new phoneflap $ cd phoneflap $ cargo run Hello, world!
A beautiful start. Anyway: let's download cmudict-07b since that's the one linked from the site and make a couple observations:
- The start of the file uses triples semicolons to denote comments
- words and their phonemes are separated by two spaces
- Phoneme and their stress are paired but can not contain the stress too
- stress comes at the end of the phoneme
So, I started writing code to just load the file and some scaffolding around how I wanted to handle it.
use std::fs;
use std::collections::HashMap;
fn main() {
let dictionary = fs::read_to_string("./data/cmudict-0.7b.txt").expect("Couldn't load dictionary");
let definitions: HashMap<String, PhonemeSet> = dictionary
.lines()
.filter(|line| !line.starts_with(";;;"))
.filter_map(|definition| {
let maybe_phoneme_set = PhonemeSet::new(&definition);
maybe_phoneme_set.map(|phoneme_set| {
(phoneme_set.word.clone(), phoneme_set)
})
})
.collect();
println!("{:?}", definitions.values().next());
}
I'm a bit of a fan of domain driven approaches to representation, so that PhonemeSet code
has a structural definition of:
#[derive(Debug, Clone, PartialEq, Eq, Hash)]
struct PhonemeSet {
set: Vec<Phoneme>,
word: String,
}
impl PhonemeSet {
fn new(raw_line: &str) -> Option<Self> {
None
}
}
#[derive(Debug, Clone, PartialEq, Eq, Hash)]
struct Phoneme {
phone: Phone,
stress: LexicalStress
}
#[derive(Clone, Debug, PartialEq, Eq, Hash, Copy)]
enum Phone {
AA,
AE,
...
ZH,
}
#[derive(Debug, Clone, PartialOrd, PartialEq, Eq, Hash, Copy)]
enum LexicalStress {
NoStress, // kind of want to use None but don't want to get confused!
Primary,
Secondary
}
I then tried to run the code to load the txt file I had downloaded and was greeted with a bit of a surprise:
thread 'main' panicked at phoneflap\src/main.rs:5:68:
Couldn't load dictionary: Error { kind: InvalidData, message: "stream did not contain valid UTF-8" }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
error: process didn't exit successfully: `C:\Users\Ethan\Documents\Code\Personal\tools\target\debug\phoneflap.exe` (exit code: 101)
So that's weird. I looked at the properties and windows didn't really tell me much
And file didn't really tell me much more either:
$ file data/cmudict-0.7b.txt data/cmudict-0.7b.txt: ASCII text
Since I knew someone in the discord was using this for something, I popped over and asked about it and they noted:
it's possible the file is encoded in ascii or one of the ascii equivalent encodings that isn't unicode.
what does file magic say about the file?
if it's trying to read the file as utf-16 which is the default windows string encoding, then it will fail.
And so I ran file -m data/cmudict-0.7b.txt and saw a bunch of lines like this:
data/cmudict-0.7b.txt, 133910: Warning: offset `}RIGHT-BRACE R AY1 T B R EY1 S' invalid file: could not find any valid magic files!
Well, that invalid offset warning certainly sounds like a problem that perhaps the difference between UTF-8 and UTF-16
could cause. So... do I update my rust code to handle the weirdly encoded data via an
OsStr or do we just re-encode the file
with sublime text's save with encoding feature and move along?
Well, I sort of roped folks in the discord into the side quest and while I was content to just re-encode and move on. Their enthusiam was infectious, and much like the plague, spread to me quickly and knocked me off the road I was on. But, unlike the plague, I'll probably come away healthier for this. So let's take the side quest to get this file to load as expected.
I initially started reading about OsStr since it seemed like it had OS-specific stuff, and since this seemed like a windows issue, that that would make sense. However, I was steered away from this:
you really should only use osstr for libc style apis and such
it's for "system call" type stuff
interacting with the os
And instead told that it might be better to iterate the file, character by character, and look for an invalid range. The person helping me did this faster than I could and posted a snapshot of how far they got:
Utf8Error { valid_up_to: 1001116, error_len: Some(1) }
Then looked at the bytes and found that it was some accented characters that were the problem. Specifically "déjà" The funny thing of course was that I was able to load the file into a string via this code:
fn read_the_dang_thing(str: &str) {
let file = fs::read(str).expect("couldnt load");
let line: Vec<char> = file.into_iter().map(|bytes| bytes as char).take(10).collect();
println!("{:?}", line);
}
The user suggested that the file might be saved in the ISO-8859-1 format rather than a regular ASCII file like windows was trying to suggest. As well as included some code to quickly prove things out that it worked:
fn main() {
let latin1: Vec<u8> = std::fs::read("./cmudict.txt").unwrap();
let utf8: String = latin1.iter().copied().map(char::from).collect();
let manual_utf8: Vec<u8> = from_latin1(&latin1);
assert_eq!(utf8.as_bytes(), manual_utf8);
}
fn from_latin1(bytes: &[u8]) -> Vec<u8> {
let mut v = vec![];
for &byte in bytes {
if byte <= 0x7F {
v.push(byte)
} else {
v.push(byte >> 6 | 0b1100_0000);
v.push(byte & 0b0011_1111 | 0b1000_0000);
}
}
v
}
I had to ask about the else clause since the first bit I correctly assumed it was filtering down bytes within the ascii range. The second part, quote:
the 0b110 prefix says "I am the first byte of a value that was encoded as two bytes"
the 0b10 prefix says "I am a subsequent byte in a multi-byte value"
(a 0b0 prefix says "I am a value encoded as a single byte; i.e. ASCII")
And the helpful user mused "Windows-1252" was the actual encoding. A few other users joined in while we fiddled around and made sure that the lines in the file printed as expected, and a super simple method like this did work for a majority of the lines:
fn read_the_dang_thing(str: &str) -> String {
let file = fs::read(str).expect("couldnt load");
file.into_iter().map(|bytes| bytes as char).collect()
}
But it felt kind of wrong. And most likely like there was some symbol characters I'd be parsing that were going to get mangled, so the use of the bstr crate was suggested to handle this properly, and a bit of example code was sent over the IRC to me:
use bstr::ByteSlice;
use std::{borrow::Cow, collections::HashMap};
fn main() {
let not_utf8: Vec<u8> = std::fs::read("./cmudict.txt").unwrap();
let definitions: HashMap<String, PhonemeSet> = not_utf8
.lines()
.map(decode)
.filter_map(|line| PhonemeSet::new(&line))
.map(|ps| (ps.word.clone(), ps))
.collect();
}
fn decode(line: &[u8]) -> Cow<'_, str> {
if let Ok(s) = std::str::from_utf8(line) {
Cow::Borrowed(s)
} else {
// naive ISO-8859-1 implementation that does not handle Windows-1252
Cow::Owned(line.iter().map(|b| *b as char).collect())
}
}
So. With the bit of code thrown my way, I gave it a try
fn main() {
let definitions = parse_dictionary("./data/cmudict-0.7b.txt");
println!("{:?}", definitions.iter().next());
}
fn parse_dictionary(dictionary_file_path: &str) -> HashMap<String, PhonemeSet> {
let not_utf8: Vec<u8> = std::fs::read(dictionary_file_path).expect("Could not load dictionary file");
let definitions: HashMap<String, PhonemeSet> = not_utf8
.lines()
.map(decode)
.filter(|line| !line.starts_with(";;;"))
.filter_map(|line| PhonemeSet::new(&line))
.map(|p| (p.word.clone(), p))
.collect();
definitions
}
fn decode(line: &[u8]) -> Cow<'_, str> {
if let Ok(s) = std::str::from_utf8(line) {
Cow::Borrowed(s)
} else {
// naive ISO-8859-1 implementation that does not handle Windows-1252
Cow::Owned(line.iter().map(|b| *b as char).collect())
}
}
And running the program? The output was
Some(("BLODGETT B L AA1 JH IH0 T", PhonemeSet { set: [] }))
Side quest complete. So, let's get back to parsing! We've already ignored the comment lines, so now the next 3 observations of mine come into play:
- words and their phonemes are separated by two spaces
- Phoneme and their stress are paired but can not contain the stress too
- stress comes at the end of the phoneme
- stress is optional field
Working from the bottom up, the individual phone characters can be handled via simple match
impl Phone {
fn from(str: &str) -> Option<Phone> {
match str {
"AA" => Some(Phone::AA),
"AE" => Some(Phone::AE),
...
"" => None,
_ => {
println!("no match on {:?}", str);
None
}
}
}
}
Next, a Phoneme is the combination of that character and the optional digit at the end:
impl Phoneme {
/// expects AA or AA0, AA1, AA2 where AA is any phoneme of the 39.
fn from(phone_and_stress: &str) -> Option<Self> {
let stress = match phone_and_stress.chars().find(|&c| c.is_ascii_digit()) {
None => LexicalStress::NoStress,
Some(stress_char) => match stress_char {
'1' => LexicalStress::Primary,
'2' => LexicalStress::Secondary,
_ => LexicalStress::NoStress,
}
};
let raw_phone: String = phone_and_stress
.chars()
.take_while(|c| !c.is_ascii_digit())
.collect();
Phone::from(&raw_phone).map(|phone| {
Self {
phone,
stress,
}
})
}
}
This will technically probably also handle the invalid phoneme of "1AA" but I'm not too worried since we have a fixed dataset. The checks are pretty straightforward here though, we just get the first digit we find to check for 1 or 2 and let 0 or none become no lexical stress, then the rest of the characters are shipped off to the other match we did first.
To get each potential pair of characters and digit, we go up one level higher to the actual line itself:
impl PhonemeSet {
fn from(raw_line: &str) -> Option<Self> {
if !raw_line.contains(" ") {
return None;
}
let split_point = raw_line.find(" ").unwrap();
let (word, phones_and_stresses) = raw_line.split_at(split_point);
let set = PhonemeSet::parse_phoneme(phones_and_stresses);
Some(PhonemeSet {
word: word.to_string(),
set,
})
}
fn parse_phoneme(raw_line_data: &str) -> Vec<Phoneme> {
raw_line_data
.split(" ")
.filter_map(Phoneme::from)
.collect()
}
}
Where we split the line at the double space, then pass off the non-word portion to
the helper method that splits on each individual empty space again. Note that we
rely on how Phoneme::from is going to return None for an
empty string to handle the fact that the split_at is going to leave the two spaces
at the start of the string being parsed.
With that done and ready, I ran my script and lo and behold (reformated from a single line for clarity):
Some(
(
"MIDPRICED",
PhonemeSet {
set: [
Phoneme { phone: M, stress: NoStress },
Phoneme { phone: IH, stress: Primary },
Phoneme { phone: D, stress: NoStress },
Phoneme { phone: P, stress: NoStress },
Phoneme { phone: R, stress: NoStress },
Phoneme { phone: AY, stress: Primary },
Phoneme { phone: S, stress: NoStress },
Phoneme { phone: T, stress: NoStress }
],
word: "MIDPRICED"
}
)
)
Now, as I observed before, the number of syllables in a given word seem to roughly align with how many vowels there are. So, taking the midpriced example above, we've got an IH and a AY for vowel phones and if you envision a simple mouth flap, it would move twice. So to make this simple, let's update the enum with a helper method and then the struct with a quick aggregate of that information:
impl Phone {
fn contains_vowel(&self) -> bool {
match self {
Self::AA => true,
Self::AE => true,
Self::AH => true,
Self::AO => true,
Self::AW => true,
Self::AY => true,
Self::EH => true,
Self::ER => true,
Self::EY => true,
Self::IH => true,
Self::IY => true,
Self::OW => true,
Self::OY => true,
Self::UH => true,
Self::UW => true,
_ => false
}
}
...
}
impl PhonemeSet {
...
fn vowel_count(&self) -> usize {
self.set.iter().filter(|phoneme| phoneme.phone.contains_vowel()).count()
}
}
And quickly printing out to confirm things work:
fn main() {
let definitions = parse_dictionary("./data/cmudict-0.7b.txt");
let definition = definitions.iter().next().unwrap();
println!("{:?}", definition);
println!("{:?}", definition.1.vowel_count());
}
cargo run
("DISGUISING", PhonemeSet { set: [Phoneme { phone: D, stress: NoStress }, Phoneme { phone: IH, stress: NoStress }, Phoneme { phone: S, stress: NoStress }, Phoneme { phone: G, stress: NoStress }, Phoneme { phone: AY, stress: Primary }, Phoneme { phone: Z, stress: NoStress }, Phoneme { phone: IH, stress: NoStress }, Phoneme { phone: NG, stress: NoStress }], word: "DISGUISING" })
3
So far so good. I'll move these methods over into a lib.rs file and then we'll be ready to go to move onto the next step!
A simple mouth machine ↩
Now the next tricky part is how to animate this information. For now, let's avoid the more complicated case of an actual GUI and instead use ASCII art. For example:
0 . 0 0 - 0 0 o 0
Is a simple face with a mouth opening and closing. If we use some terminal flushing commands like we used when we animated advent of code then we can easily produce something that will get the proof of concept out:
use std::{thread, time};
let lines = vec!["0 . 0", "0 - 0", "0 o 0", "0 - 0"];
let delay_between_frames = time::Duration::from_millis(150);
let mut buffer = String::new();
loop {
for line in lines.iter() {
print!("\x1B[2J\x1B[H");
print!("{}", buffer);
std::io::Write::flush(&mut std::io::stdout()).unwrap();
thread::sleep(delay_between_frames);
buffer.clear();
buffer.push_str(line);
buffer.push_str("\n");
}
}
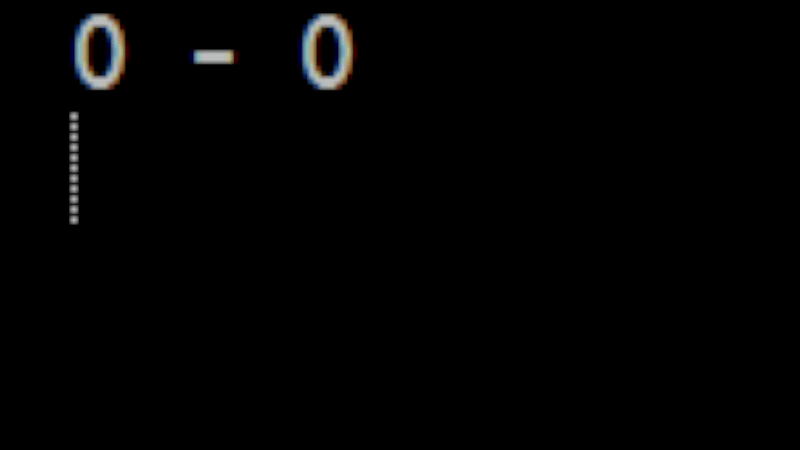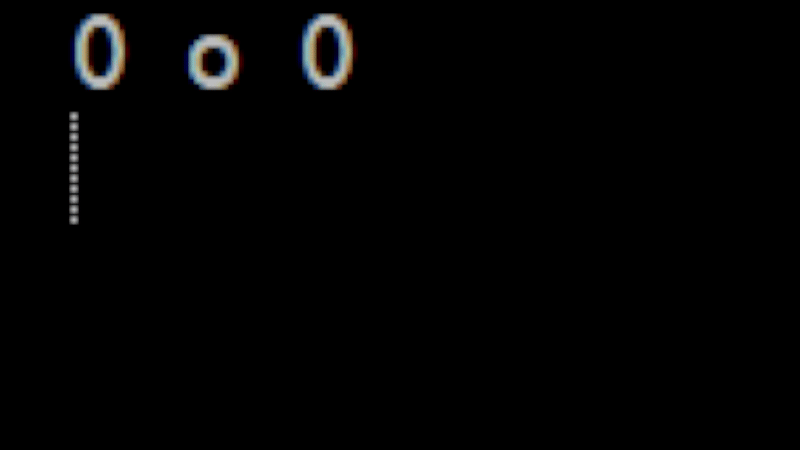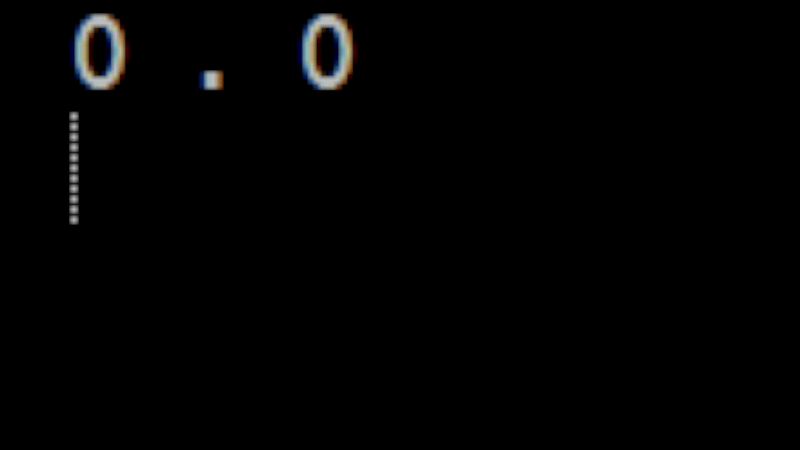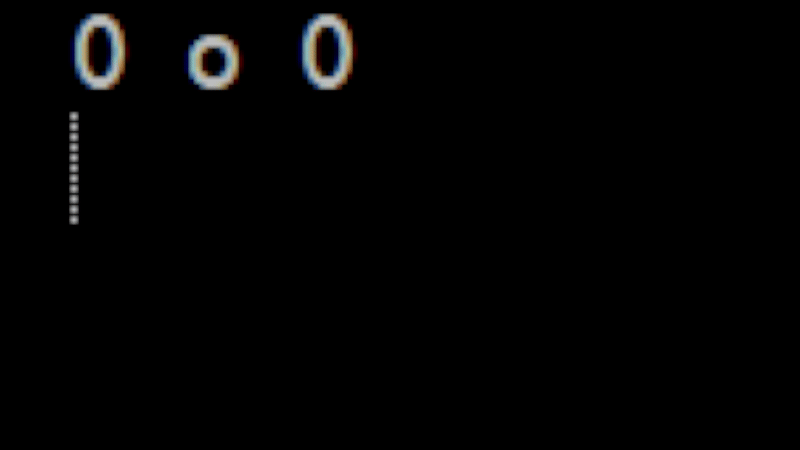
This should work just fine for our purposes, but now we need a way to tie this sort of animation to the phoneme set we've made. Specifically, I'm thinking that for starters, we'll use 50ms for each phone and make sure to return the flap to a closed position between each vowel. Now, that's not obviously true once we start making more shapes, but with our limited expression that's the most we can do.
As far as implementing this goes, to me this feels like a great moment for a finite state machine to shine. Or at least something like that. We could have some form of "tick" and on each tick we can drain a bit more of a queue and transition between the state of flapping open and flapping closed. So, let's draw a picture to give ourselves a guide:
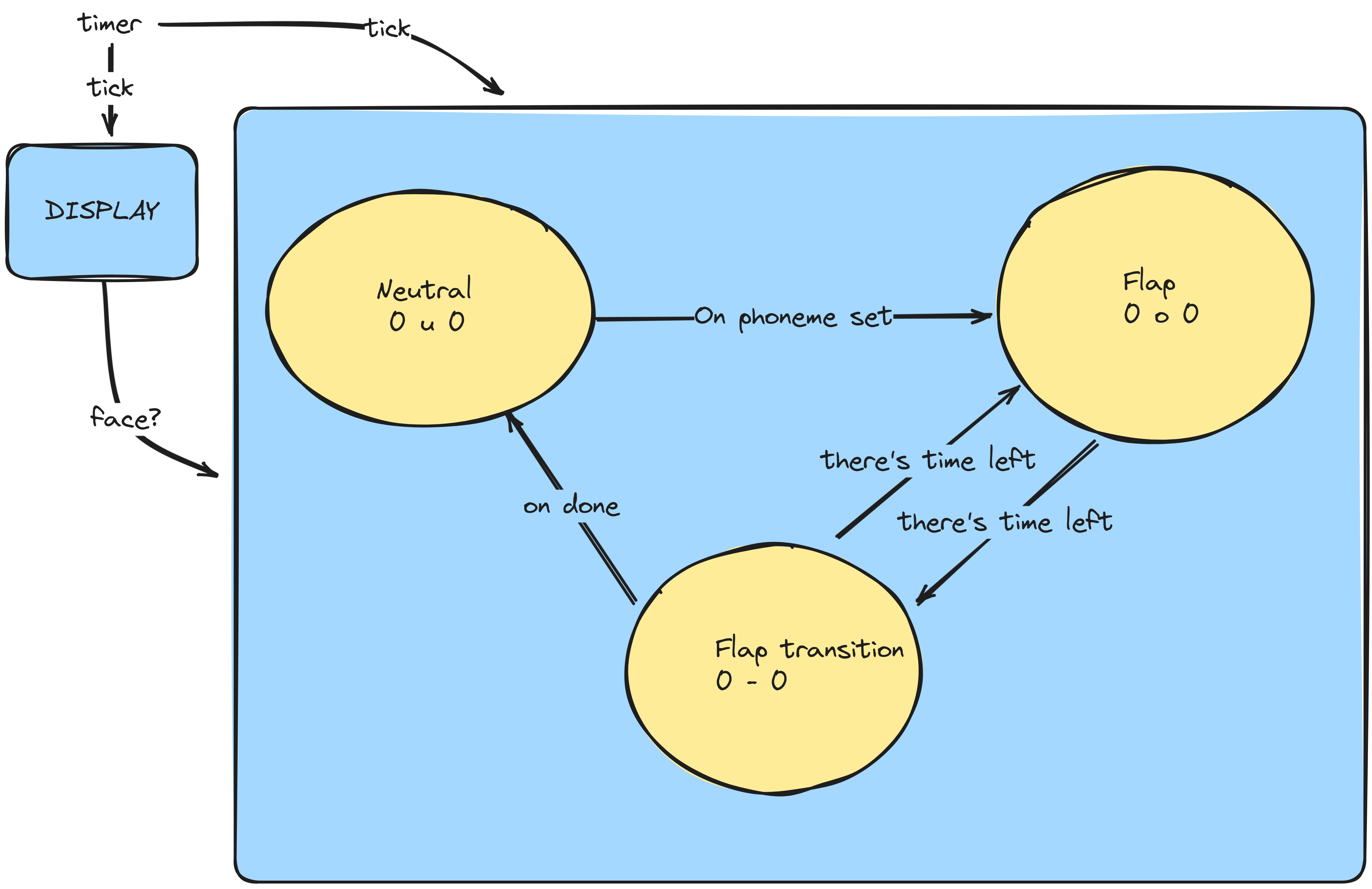
So, going with the "something like that" approach, we can think of our very basic lip flapping as an enum combined with a duration to be in that state:
enum SimpleFaceState {
Neutral,
FlapOpen(Duration),
FlapClosed(Duration)
}
In order to queue things up we'll need our machine to keep track of its current state as well as an inbox of messages:
struct SimpleFlaps {
state: SimpleFaceState,
messages: VecDeque<SimpleFaceState>
}
To focus in on the swapping back and forth of states and how we transition from one to the next, we can implement
a tick method on the machine:
fn tick(&mut self, since_last_tick: Duration) {
match self.state {
SimpleFaceState::Neutral => self.next_state(),
SimpleFaceState::FlapOpen(time_left) => {
let new_time_left = time_left.checked_sub(since_last_tick);
match new_time_left {
None => self.next_state(),
Some(time_left) => {
self.state = SimpleFaceState::FlapOpen(time_left);
}
}
},
SimpleFaceState::FlapClosed(time_left) => {
let new_time_left = time_left.checked_sub(since_last_tick);
match new_time_left {
None => self.next_state(),
Some(time_left) => {
self.state = SimpleFaceState::FlapClosed(time_left);
}
}
}
}
}
fn next_state(&mut self) {
if let Some(new_state) = self.messages.pop_front() {
self.state = new_state;
} else {
self.state = SimpleFaceState::Neutral;
}
}
When the machine is in neutral, it just checks its inbox on each tick to find out if there's a new state for it to transition to. If there isn't, it stays Neutral and waits until the next tick to check again.
But if we're flapping open or closed, we'll subtract the delta time since the last tick and based on whether or not the current state's timer has reached 0 or not, we'll move to the next state in our inbox.
So, how do we get new stuff in our inbox? Whenever we tell the face to speak of course!
fn speak(&mut self, phoneme_set: &PhonemeSet) {
let states = SimpleFaceState::from(phoneme_set);
for state in states {
self.messages.push_back(state);
}
}
And this begs the question about how we do the conversion, which I've hinted at already but here's the code!
// in SimpleFaceState impl
fn from(phoneme_set: &PhonemeSet) -> VecDeque<SimpleFaceState> {
let states = VecDeque::new();
let mut flip_flop = true;
let mut next_state = |tuple: (&Phoneme, Duration)| {
let (_, duration) = tuple; // potentialy we use the phoneme in the future
let face = if flip_flop {
SimpleFaceState::FlapOpen(duration)
} else {
SimpleFaceState::FlapClosed(duration)
};
flip_flop = !flip_flop;
face
};
phoneme_set.set.iter().map(|phoneme| {
(phoneme, Duration::from_millis(50))
}).fold(states, |mut acc, phoneme_tuple| {
match acc.pop_back() {
None => acc.push_back(next_state(phoneme_tuple)),
Some(previous_state) => {
if phoneme_tuple.0.phone.contains_vowel() {
acc.push_back(previous_state);
acc.push_back(next_state(phoneme_tuple));
} else {
let new_state = previous_state.add_time(phoneme_tuple.1);
acc.push_back(new_state);
}
}
};
acc
})
}
The conversion iteration might look a little bit funky, but it's not really doing anything fancy at all. We pair each phoneme with a duration, then collapse each consonant after a vowel into the duration for that vowel. Here's a good example:
"THIS'LL" becomes DH IS1 S AH0 L (DH, 50) (IS1, 50) (S, 50) (AH0, 50) (L, 50) <-- initially (DH, 50) (IS1, 100) (AH0, 100) <-- and once its reduced via fold.
The closure next_state is keeping track of whether or not the mouth is open or
closed when we want to add a new state into the queue we're building. You can see that we're
not doing anything with the actual phoneme itself during that stage (_, duration),
but potentially in the future we could use the actual letters to figure out what shape the mouth
should take. For a quick proof of concept though, this is ok!
Speaking of displaying the mouth though, this is the code to quickly convert our current state to an ascii layout to show:
fn display(&self) -> String {
match self.state {
SimpleFaceState::Neutral => "0 u 0",
SimpleFaceState::FlapClosed(_) => "0 - 0",
SimpleFaceState::FlapOpen(_) => "0 o 0",
}.to_string()
}
and last but not least, the modifications to that animation code I showed before that was just looping through the same face letters over and over again. The structure stays mostly the same, but now we're grabbing words out of the dictionary we've loaded and saying them outloud:
fn main() {
let definitions = parse_dictionary("./data/cmudict-0.7b.txt");
let mut definitions = definitions.iter();
let delay_between_frames = Duration::from_millis(25);
let mut face = SimpleFlaps::new();
let mut time_until_next_word = Duration::from_millis(200);
let mut now_saying = String::new();
let mut buffer = String::new();
loop {
print!("\x1B[2J\x1B[H");
print!("{}", buffer);
std::io::Write::flush(&mut std::io::stdout()).unwrap();
thread::sleep(delay_between_frames);
buffer.clear();
// Note: should _actually_ compute this delta.
face.tick(delay_between_frames);
buffer.push_str(&face.display());
buffer.push('\n');
buffer.push_str("Now saying: ");
buffer.push_str(&now_saying);
buffer.push('\n');
match time_until_next_word.checked_sub(delay_between_frames) {
None => {
time_until_next_word = Duration::from_millis(1000) + face.time_left_before_finished_speaking();
if let Some(phoneme_set) = definitions.next() {
now_saying = phoneme_set.1.word.clone();
face.speak(phoneme_set.1);
}
},
Some(time_left) => {
time_until_next_word = time_left;
}
}
}
}
I'm taking a shortcut around the delta and for now assuming that windows will sleep as long as I asked it to and then wake up relatively quickly after. We're still flushing the buffer, but I also added some debugging output for us to be able to tell which word is being said so that we can see the shapes go. Here's what that looks like:
The somewhat halted pace is because of our time_until_next_word calculation is adding the time until
we next queue up a word to be the amount of time it'll take to animate the mouth flaps as well as an entire second
of wait time. I did this so that I could more easily watch the words go by in a steady way, but obviously we could
tweak this to be smaller to get a smoother looking flow of things.
Mouth mappings ↩
So we've accomplished 3 out of the 4 times we listed in the plan section. The last of which is what I alluded to in the previous section. We're not doing anything with the actual phoneme's besides using their vowel status or not. But, if you say A outloud and E outloud, you'll notice your mouth makes different shapes!
Ok, maybe it's not a huge epiphany by any stretch of the imagination, but it is one last thing we can try to make the ascii machine do for us. I'm not going to try to make 39 unique mouth movements here, but I think we can at least put together a rough idea of what the mouth should "flap to" when its processing a phoneme. Though this does mean that we'll need to stop aggregating the information together into two vowel syllables with durations.
Instead, let's tweak our SimpleFaceState
enum SimpleFaceState {
Neutral,
Flap(String, Duration), // Shape, Duration of shape
}
This will of course, break everything. But we can use the compiler as our guide to fix things up, but before we do let's define the method for the shapes:
pub fn to_mouth_shape(&self) -> String {
match self {
Self::AA => "o",
Self::AE => "=",
Self::AH => "o",
Self::AO => ".",
Self::AW => "o",
Self::AY => "=",
Self::B => ".",
Self::CH => "=",
Self::D => "=",
Self::DH => "-",
Self::EH => "o",
Self::ER => ".",
Self::EY => "=",
Self::F => "n",
Self::G => "=",
Self::HH => "o",
Self::IH => "-",
Self::IY => "=",
Self::JH => "o",
Self::K => "o",
Self::L => "-",
Self::M => "-",
Self::N => "-",
Self::NG => "=",
Self::OW => "o",
Self::OY => ".",
Self::P => "o",
Self::R => "=",
Self::S => "o",
Self::SH => "=",
Self::T => "=",
Self::TH => ".",
Self::UH => "p",
Self::UW => "o",
Self::V => "v",
Self::W => "w",
Self::Y => "=",
Self::Z => "o",
Self::ZH => "=",
}.to_string()
}
There's no science here. This is me sitting at my computer, making those sounds, and then trying to think what my mouth kind of
looks like. Like when you say "teeth" and you pull your cheeks back and your teeth show a bit, that's = so IY
becomes =. Simple.
Moving along to the broken code, the next_state method becomes quite a bit simpler, we no longer manually track the "flip flop"
boolean. In fact, the change simplifies things so much, that we can just ditch the closure and collapse everything together:
fn from(phoneme_set: &PhonemeSet) -> VecDeque<SimpleFaceState> {
let states = VecDeque::new();
phoneme_set.set.iter().map(|phoneme| {
(phoneme, Duration::from_millis(50))
}).fold(states, |mut acc, phoneme_tuple| {
acc.push_back({
let mouth = phoneme_tuple.0.phone.to_mouth_shape();
SimpleFaceState::Flap(mouth, phoneme_tuple.1)
});
acc
})
}
Heck, we could probably even make the duration be dependent on the phoneme, but I'm going to skip that for now in favor of fixing more compiler errors:
fn display(&self) -> String {
match &self.state {
SimpleFaceState::Neutral => "0 u 0".to_string(),
SimpleFaceState::Flap(mouth, _) => format!("0 {} 0", &mouth),
}
}
fn tick(&mut self, since_last_tick: Duration) {
match &self.state {
SimpleFaceState::Neutral => self.next_state(),
SimpleFaceState::Flap(mouth, time_left) => {
let new_time_left = time_left.checked_sub(since_last_tick);
match new_time_left {
None => self.next_state(),
Some(time_left) => {
self.state = SimpleFaceState::Flap(mouth.to_string(), time_left);
}
}
}
}
}
fn time_left_before_finished_speaking(&self) -> Duration {
let mut time_left = match self.state {
SimpleFaceState::Neutral => Duration::from_millis(0),
SimpleFaceState::Flap(_, duration) => {
duration
}
};
for message in &self.messages {
match message {
SimpleFaceState::Neutral => {},
SimpleFaceState::Flap(_, duration) => {
time_left += *duration;
},
}
}
time_left
}
Since flap open and closed both were pretty similar, this actually makes our code easier and simpler. So that's pretty nice. And, the result is pretty good too:
Wrap up ↩
So, we started off with a pretty awesome resource with that pronounciation guide from CMU, and despite the weird encoding issue, we were able to lift the raw text data up into our own types for us to work with and play around in.
Once we got the ball rolling on that, we created a finite state machine to transition back and forth between states so that we could have a sense of animation and timing to the different states we're in, and wiring that up to a basic terminal flushing loop gets us the illusion of a talking mouth.
It's not bad for a single days worth of work. I was listening to a 7 hour playlist of good music while I programmed, and we finished everything up basically within that span which makes for a good Saturday to me! I think in the future, I can probably leverage this state machine code as a reference or lift and shift some of the bits out over into my sentituber work if I want to make the PNGTuber have a "real" mouth that can move in some sort of interesting way when I speak.
Of course, one slight issue is that the dictionary isn't exhaustive to all the words one can say, heck, just saying video game titles is likely to result in no results, so the conversion of text will need either some extensions to the file we're parsing for rules, or we'll have to figure out some suitable defaults. That'll be a subject for another blogpost though!