How do sublime snippets work? ↩
I've written 5 snippets already and I'm only at the first paragraph of the first section! 2 But, I haven't written any out for you yet! Heck, I haven't even explained how sublime snippets work yet. They're really really intuitive and easy to use though; they integrate instantly the second you save them, and so it was impressively easy for me to add in a few on my way to typing the words you're reading now.
The extension for a sublime text snippet file is .sublime-snippet and the
file is just an XML file with a couple fields defined. Unlike last post, where I was
having a lot of trouble with the sublime documentation site, I found the
community docs site
and it is so much better. Lifting out the snippet XML sample here:
<snippet>
<content><![CDATA[Type your snippet here]]></content>
<!-- Optional: Tab trigger to activate the snippet -->
<tabTrigger>xyzzy</tabTrigger>
<!-- Optional: Scope the tab trigger will be active in -->
<scope>source.python</scope>
<!-- Optional: Description to show in the menu -->
<description>My Fancy Snippet</description>
</snippet>
It's pretty easy to see how this works. Say you've got a couple of tab triggers setup that share the same prefix. If you type it, then hit tab:

An autocomplete appears and shows you the description you wrote, so long as whatever
scope you're in matches the scope of the snippet. Unsurprisingly, content
is where the interesting part of a snippet lies. Becuase we have access to
fields!
In the simplest form (and the the only one I've used so far) we use $N where
N is any positive number. If you use $0, you can set where the cursor will start after the
user has finished typing into the other placeholders you've defined. This is really intuitive
if you've ever done any sort of string formatting in your life, so it's easy to pick up.
Much like string formatting, you're not limited to referencing some variable only once. So if you say
<content><![CDATA[$1 $1 $1 $1 $1 $1 $1 $1 $1 $1! $0]]></content>
and then type out nana <press tab> batman <press tab> then you'd have the start of the batman tune
that everyone always sings and your cursor would be placed right after it. Granted, the
default position of the $0 is the end of the snippet, so it's not neccesary in the above
silly case, but it's useful to know.
The other useful thing to know is that you're not limited to a single line for your snippet. Since it's CDATA, you can put mostly whatever in there. 3 Including newlines! So we can easily put an entire HTML snippet, nicely tabbed and formatted, into any snippet we want and then make it easy to enter the information that needs to change.
There's one other feature these offer that I haven't quite used yet. I tried at
one point, but gave up because it was a bit too obtuse for me to grok on the first pass.
Substitutions
let you use a regex to tweak and modify the value of a given placeholder for the substitution.
So if you wanted to take in $1 and then if it had the value of mad
you could do something like ${1/(\w+)(mad)(\w+)/\1glad\3/g} and it would replace
that word. I haven't tested this example I just thought up, just based it on the examples
snippets from the doc I linked, regex's with captures, references and bunches of other stuff
is something that really glazes my eyes over.
Anywho, my skill issues aside, that's all we really need to know to get started in on a quick rundown of the snippets I've made so far as I write this!
The new blog template ↩
First up, when I've made a new blog 4
before I did the equalvalent of cp template.html date-time-stamp-sentence.html in
my terminal or in the editor depending on my mood. With my fancy new snippet, I can do this
instead:
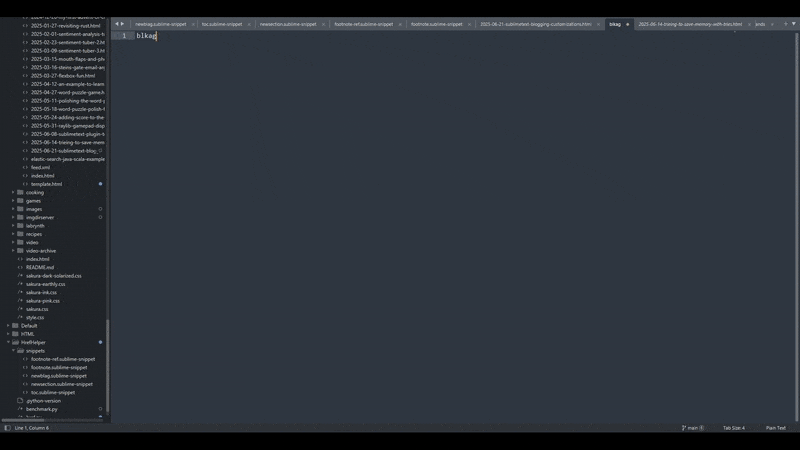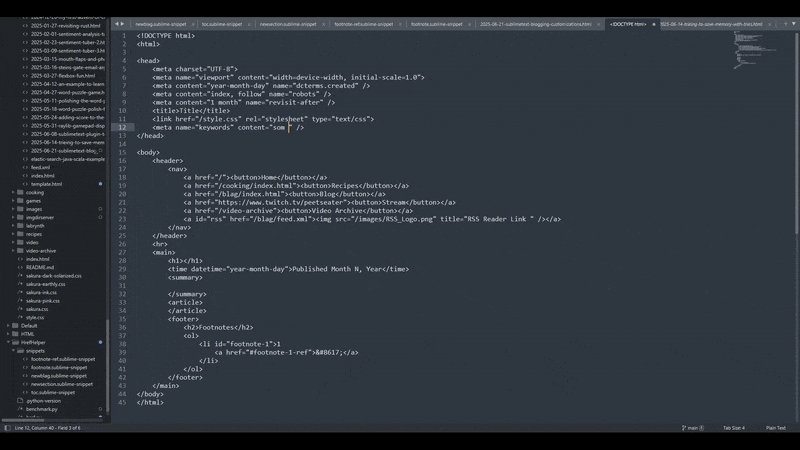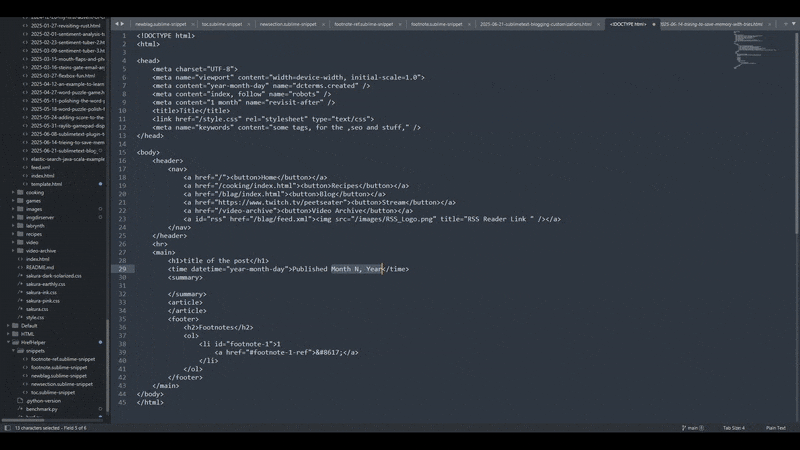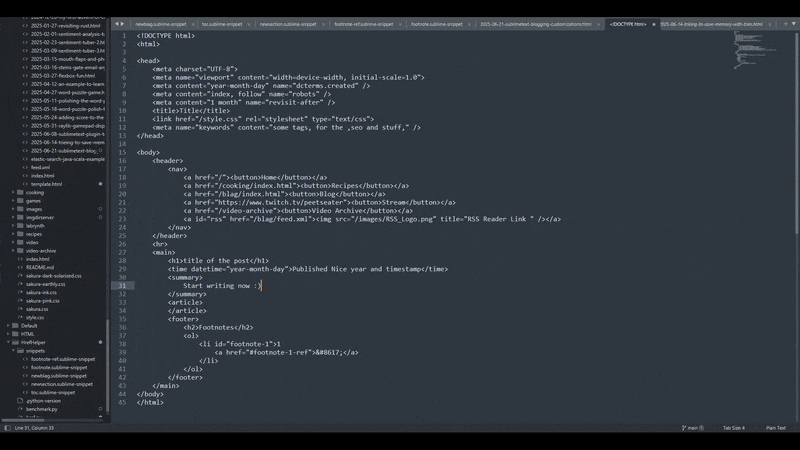
You might notice that the autocomplete options didn't pop up. I just wrote blag and
then pressed tab and it filled in the entire snippet for me. If it's too hard to see I'll just
note what I'm doing here:
- Write blag
- tab
- Fill in title tag
- tab
- Fill out YYYY-MM-DD (This fills in two places! Time saved!!!)
- tab
- Fill out keywords for page for search engines that still actually care
- tab
- Fill out the H1 title, tab (which is often different than my page title)
- tab
- Fill out the nice date (I could maybe use substitutions to do part of this but don't currently)
- tab
- My cursor lands in the summary section and I start writing the post
I should have probably booted up a keylogger to show you all the keys I was pressing, but I hope that my list gives suitable explanation. 5 As you can see, tabbing between the positions of the inputs for the template makes it easy to write without having to use the mouse very much and to go from one thing to then next easily.
So what's the snippet file look like? Ignoring some of the non-variable lines for brevity, it looks like this:
<snippet>
<content>
<![CDATA[
<!DOCTYPE html>
...
<meta content="${2:YEAR-MM-DD}" name="dcterms.created" />
...
<title>$1</title>
...
<meta name="keywords" content="$3" />
</head>
<body>
...
<main>
<h1>$4</h1>
<time datetime="${2:YEAR-MM-DD}">Published ${5:Month N, Year}</time>
<summary>
$0
</summary>
...
</main>
</body>
</html>]]>
</content>
<tabTrigger>blag_newpost</tabTrigger>
<scope>text.plain,text.html</scope>
<description>New blag post from template</description>
</snippet>
Important callouts are for what you saw in the gif already. We've got $2
twice (what a coincidence!) And the place to finish is within the summary field as
indicated by $0. Placeholders aside, the reason why there's no autocomplete
prompt in the gif is becuase of the scope element of the XMl. It's set
to both text.plain and text.html. New files aren't any
particular format unless you explicitly set the extension or format by hand, so
plain text it is.
As you'll see in a second, the other snippets are scoped to html only, so this means that the only autocomplete available for the plain scope is the new template, and so Sublime doesn't bother offering options to you and just fills it all in. Which saves me a bit of time.
As I noted before, the substitutions potentially could be used here. But only for the
year really, so it didn't feel worth maintaining a regex for. Converting YEAR-MM-DD
to Month name day, Year is easy enough with code, but do it with a regex?
Ehh... that seems very questionable, so, not worth the time to figure out I think.
Anywho. Once I've got the blog post ready to go, then I start writing and...
Table of contents snippet ↩
I considered having the table of contents be part of the new blog template snippet. But, if a blog post isn't long enough 6 then I won't have one, so I didn't want to always include it.
It is really simple though:
<snippet>
<content>
<![CDATA[
<nav id="toc">
<ol>
<li><a href="#section-1">$1</a></li>
</ol>
</nav>
]]>
</content>
<tabTrigger>blag_toc</tabTrigger>
<scope>text.html</scope>
<description>the table of contents</description>
</snippet>
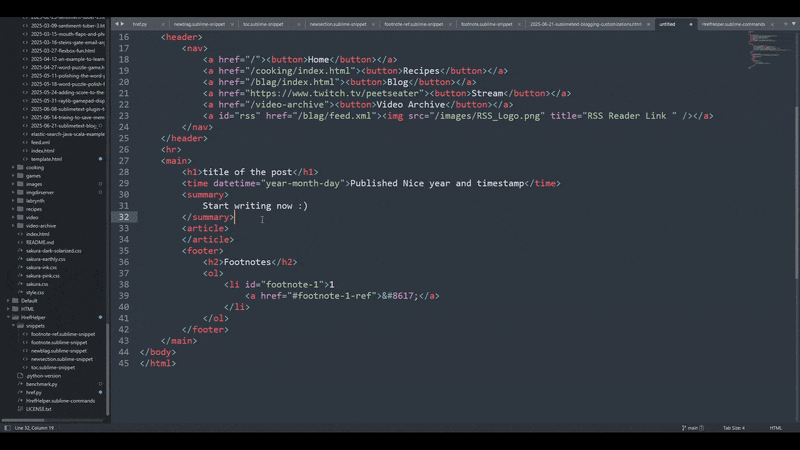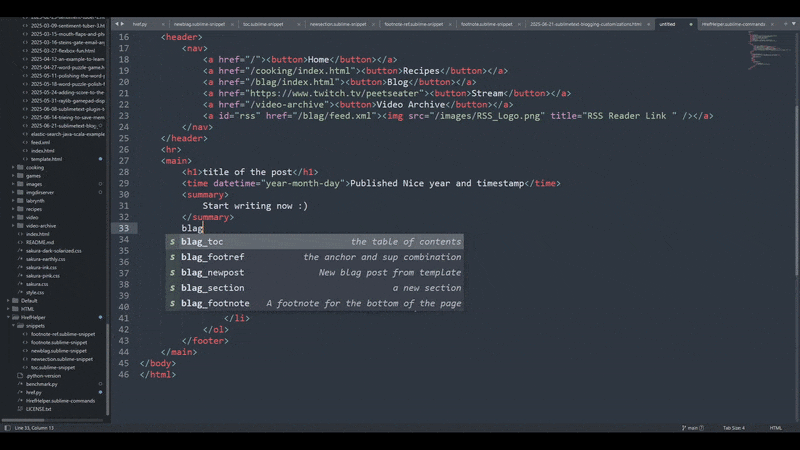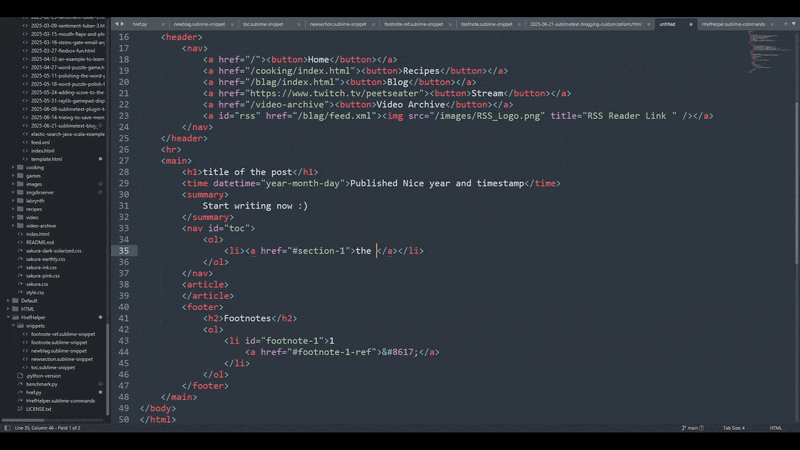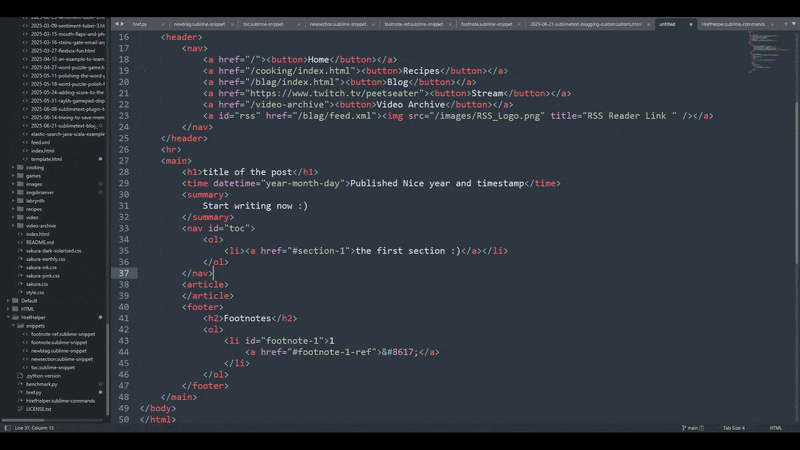
Like I mentioned in the last section, this is scoped just to HTML so that I don't trigger it if I'm typing up code in sublime in a source file for rust or something. I didn't mention this in the previous section though, notice that the indentation is a bit funky looking?
That's on purpose. If you try to keep the indendation aligned with your snippet, you're going to have a bunch of weirdo whitespace in front. If you want to correct your spacing every time, then you can do that. But if you don't want to fight with that sort of thing, then sighing and accepting your fate to have funky looking indentation in XML is what you've got to do.
The result works well though since having no indentation at the start means sublime will align things properly for you:
Sections and footnote snippets ↩
Much like the previous one, indentation matters here. But we've got a couple more placeholders in order to make it easy to say "this is section X" and then give it a name before being dropped in the appropriate place to keep writing the blogpost:
<snippet>
<content>
<![CDATA[
<section id="section-$1">
<h2>$2 <a href="#toc">↩</a></h2>
<p>
$0
</p>
</section>
]]>
</content>
<tabTrigger>blag_section</tabTrigger>
<scope>text.html</scope>
<description>a new section</description>
</snippet>
The one issue I have so far with this snippet is that I wish there was an easy way to populate the section based on existing section ids, or the last section id to be entered...If I look at the custom arguments section, then I catch a brief wind in my sails from false hope. While you can define a custom variable for a snippet through a plugin like:
import sublime_plugin
class MyInsertSnippetCommand(sublime_plugin.TextCommand):
def run(self, edit):
field1 = "Hello"
self.view.run_command(
cmd="insert_snippet",
args={
"name": "Packages/User/My Snippet.sublime-snippet",
"1": field1,
"subject": self.get_subject()
}
)
def get_subject(self):
return "World"
You'll notice that we're inside of a TextCommand and not defining any sort
of XML or an autocomplete. This means if we wanted to insert a snippet with a computed
variable then we'd have to do ctrl shift p + the command name; and that's nowhere near as
useful as the tab completed snippet. I poked around for a while, thinking maybe I could use
the shell variables;
but if you define a custom one of those, it's pulled from a file. So it's static as well,
the API to the metadata where those are set is readonly as well from what I can tell, so no
adding in a date field that way ourselves.
An option that maybe could work is that we can define autocompletions
inside of a plugin, which we did
in our first post in this series. The example snippet in the api reference sets the kind
to snippet, so if we defined the full thing into the completion and set the date into it
statically or similar, then we could potentionally have something working here.
[
sublime.CompletionItem(
"fn",
annotation="def",
completion="def ${1:name}($2) { $0 }",
completion_format=sublime.COMPLETION_FORMAT_SNIPPET,
kind=sublime.KIND_SNIPPET
),
sublime.CompletionItem(
"for",
completion="for ($1; $2; $3) { $0 }",
completion_format=sublime.COMPLETION_FORMAT_SNIPPET,
kind=sublime.KIND_SNIPPET
),
]
I think the hard part is figuring out the scoping and whatnot... but let's give it a shot!
We learned in in
section 4 of my previous adventures about how to use the on_query_completions method
to supply back completion items, so we should be able to do something pretty similar. Because I
think it might be slightly more interesting, let's use the footnote snippets as an example for this
rather than the sections:
class SnipppetAutocompleteCommand(sublime_plugin.ViewEventListener):
def on_query_completions(self, prefix, locations):
if "blag" not in prefix:
return None
footnotes_so_far = 0 # TODO: how do we figure this out?
prefilled_snippets = [
sublime.CompletionItem(
"blag_footnote_test",
annotation = "blag_footnote_pf",
completion = f"""
<li id="footnote-{footnotes_so_far}">
$0
<a href="#footnote-{footnotes_so_far}-ref">↩</a>
</li>
""",
completion_format = sublime.COMPLETION_FORMAT_SNIPPET,
kind=sublime.KIND_SNIPPET
)
]
return sublime.CompletionList(prefilled_snippets)
And then if I type blag and hit tab
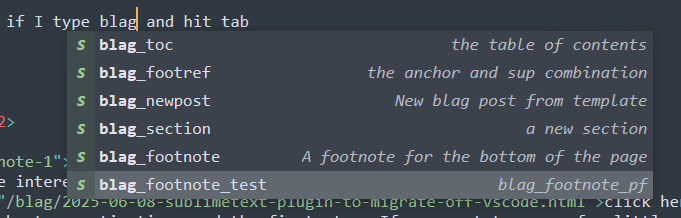
So it appears! Which isn't that surprising I suppose, but much like why we use CDATA and mess with the indentation in the XML file, the triple strings causes extra spacing that we don't want:
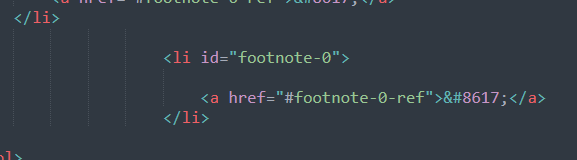
So we need to figure that one out if we want to use this as a way to populate some values in a custom way and still allow the user to select them in the snippet dropdown without having to do an extra command.
I think it's interesting, but my inner warning flag is raising here a bit because I don't like the fact that the snippets are defined both in a snippets folder via XML, and then also in this class. It would be nice if I could figure out a simple way to centralize them. The thought to load the xml file myself and extract the content blob, then do a string replacement on the snippet on my own to populate the dynamic bits comes to mind. But I'm also sort of crossing my arms and debating with myself on if it's really that much of a pain to keep track of how many sections or footnotes I have versus veering off the path that sublimes framework wants to guide me towards.
I'd like to compromise and put the .py file that will contain this sort of custom snippet autocomplete provider into the same folder as the xml files, but I ran into a lot of trouble becuase when I moved my file into a subfolder, sublime stopped recognizing it. It seems like some people get around this type of thing with some fancy loading and importing though; I tried to replicate this, but I couldn't seem to get it to work. Most likely because I'm missing some critical point of knowledge about how python modules and projects work.

So. I'll give up on that idea since organizing my plugin can be figured out later on when I care about that more than I care about getting the dynamic snippets functional. To that end, let's define some snipppets in code:
class DynamicSnippetsViewEventListener(sublime_plugin.ViewEventListener):
def __init__(self, view):
self.view = view
self.footnote_snippet = inspect.cleandoc("""
<li id="footnote-{0}">
$0
<a href="#footnote-{0}-ref">↩</a>
</li>
""")
self.footnote_ref_snippet = inspect.cleandoc("""
<sup id="footnote-{0}-ref"><a href="#footnote-{0}">{0}</a></sup>$0
""")
self.number_of_footnotes_in_file = 0
pretty simple init 7, and really the only thing worth calling out here is that I'm using
inspect.cleandoc to strip out the leading whitespace for the multiline strings
to avoid that issue we saw a moment ago. If you've been coding for a while, you probably know exactly
what we're going to do with {0}. If not then behold:
def footnote_completion(self):
new_snippet = self.footnote_snippet.format(f"{self.number_of_footnotes_in_file + 1}")
return sublime.CompletionItem(
"blag_footnote",
annotation = "A footnote for the bottom of the page",
completion = new_snippet,
completion_format = sublime.COMPLETION_FORMAT_SNIPPET,
kind=sublime.KIND_SNIPPET
)
The {0} is just a reference to the first argument passed to us via the +1 here because if already have 4 footnotes in the file I'm working on, I'm
going to be creating a reference to the next. And this will work for both the footnote and the footnote
reference line because when I'm writing, I always write the ref first. So, how do we know how many
footnotes there are in a file?
def calculate_footnote_count(self):
footnotes_in_view = self.view.find_all("id=\"footnote-[0-9]+\"", sublime.FindFlags.WRAP)
self.number_of_footnotes_in_file = len(footnotes_in_view)
Easy, we use view.find_all to perform a regular expression across the entire document.
What? You thought we'd do something like a fancy walk across the HTML or something? Nope. While
I am pretty much always a fan of using proper parsers to handle HTML, when it comes to looking
at a giant chunk of text for a few simple ids that I only need the count of, I'll keep it simple.
Putting it all together, our query completions method becomes:
def on_query_completions(self, prefix, locations):
for point in locations:
in_html_scope = self.view.match_selector(point, "text.html.basic")
if in_html_scope is False:
return None
if "blag" not in prefix:
return None
self.calculate_footnote_count()
prefilled_snippets = [
self.footnote_completion(),
self.footnote_ref_completion()
]
return sublime.CompletionList(prefilled_snippets)
Initially I played around with doing the calculate_footnote_count() call
in other places, such as the hooks for on_modified_async and on_activated_async
but it seemed kind of ridiculous to constantly compute the footnote number, and I didn't
want to try out using cached_property from functools or anything that
might end up returning stale data. No, it's simple enough to say that if I'm about to give you
the completions, I'll compute it just in time right then.
With that in place, I can now do this:
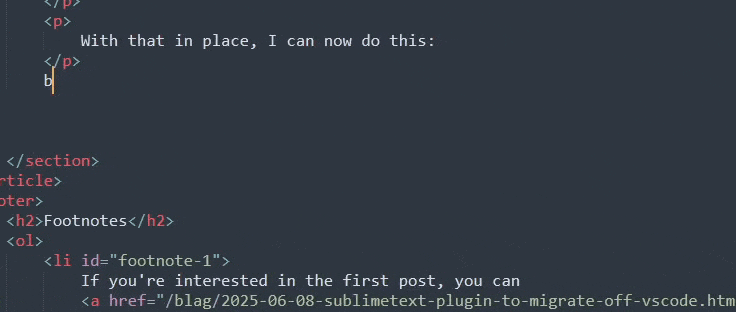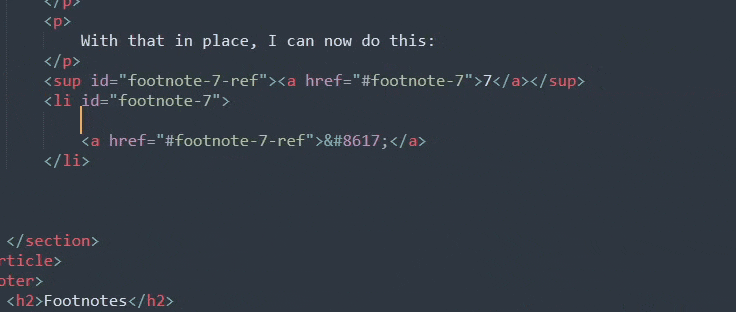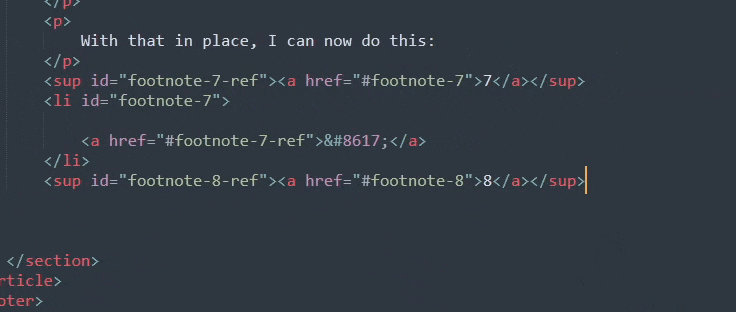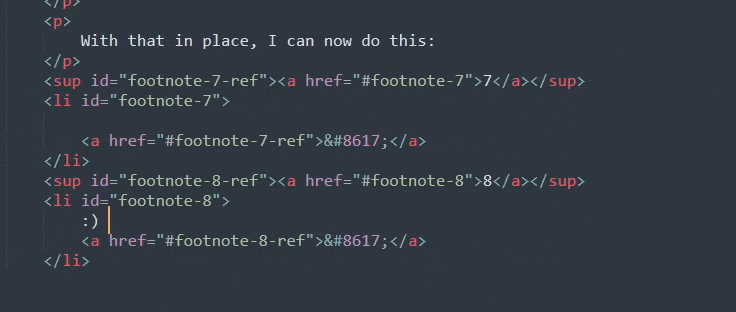
Beautiful. As you can see, I've got one less thing to type now, and I don't have to keep track of how many footnotes I've made. Which will save me a trip down to the bottom of the blogpost I'm writing whenever it's been a while since I've written a footnote.
Ah, but we started this section talking about, uh, sections didn't we. So let's define that one and a calculator for that as well:
# in __init__
self.new_section_snippet= inspect.cleandoc("""
<section id="section-{0}">
<h2>$1 <a href="#toc">↩</a></h2>
<p>
$0
</p>
</section>
""")
self.number_of_sections_in_file = 0
And you can imagine the new_section_completion since it's the same
sort of thing as the footnote one, but just using the count that we get from counting
the sections instead of the footnotes: 8
def calculate_section_count(self):
sections_in_view = self.view.find_all(
"<section id=\"section-[0-9]+\">",
sublime.FindFlags.WRAP
)
self.number_of_sections_in_file = len(sections_in_view)
And just like before, I can now dynamically create sections without having to think about how far along I am in typing up a post or not:
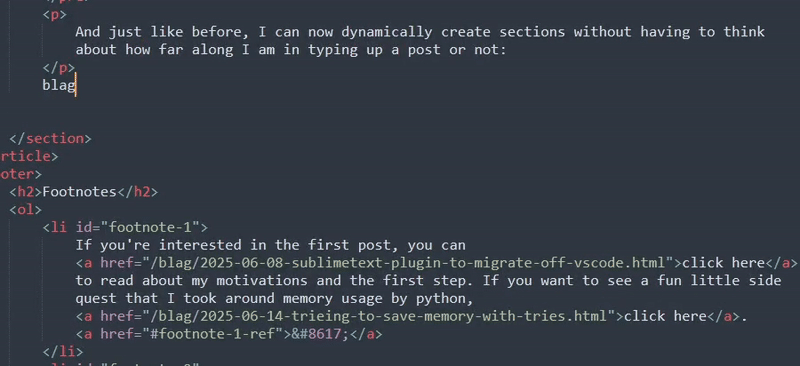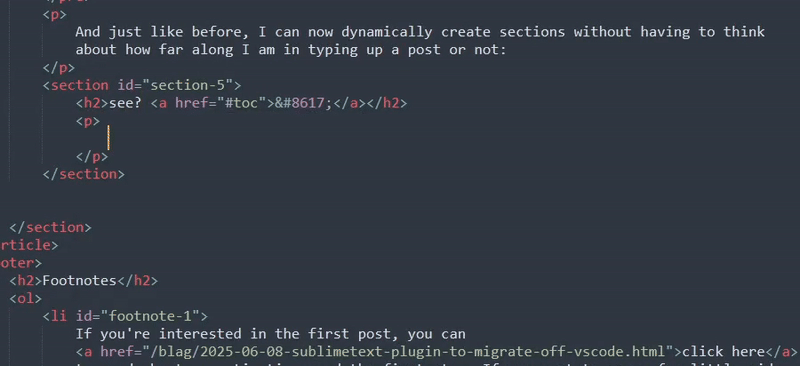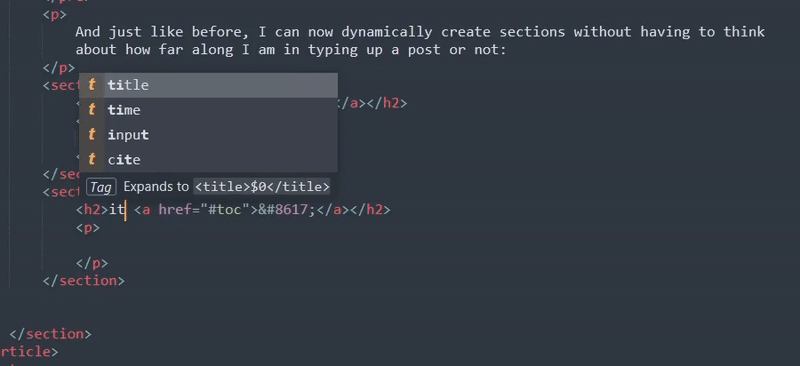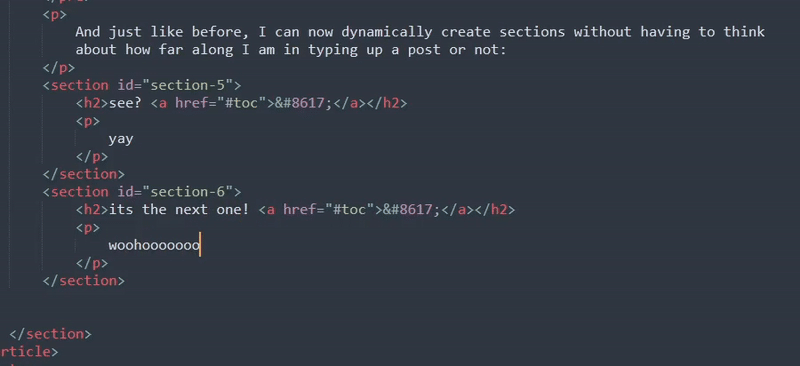
You might be wondering why I did the full element for this regex unlike the footnote
one where I was looking for just the id. Admittedly, I should probably update that
one to do something similar. But it's because while working on this and grepping around
I realized that looking just by the id=section-[0-9]+ bit was giving me
a region from the code snippets on this page! So, to avoid such things, finding the
full tag, or well, the start of the tag, helps get around that since the < and >
will be encoded and not match the search. 9
With all that done, I've got a couple more ideas that I came up with working up until this point on the blog. So let's make some neat features.
Where are you in the dom? ↩
So, our overall goal here isn't to reduce keystrokes, but make it easy and nice feeling to move off of using the bloated corpse that is VSCode and onto the lean mean slender machine that is sublime for writing these posts. I've been using it to write the post you're reading right now and have observed one thing that I miss that I haven't dealt with via our efforts so far.
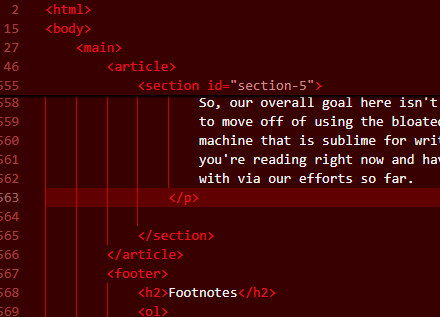
In VS Code, they do this nice thing you see above where if you're writing in some sort of tree structure such as a DOM or even in regular code scope they do what my blog does when I set the h2 to be sticky:
/* Neat little tricky to keep the headers at the top as you scroll */
h2 {
position: sticky;
top: 0;
...
That's a pretty cool feature, even if it feels slightly claustrophobic I think. What I like about it is that it's easy to click on the tag and jump to the top. I use this when I'm verifying that I really did learn how to count back before kindergarten and I've numbered my sections with correct IDs.
Now, given that our new section snippet counts for us, this probably isn't much of an issue, but if I come up with a better name for a section while I'm writing, it'd be cool to be able to quickly jump up in scope I think.
Sublime actually has two commands that could do this for us already, we just need to chain them together! If I type ctrl shift and A while next to the section tag, it will highlight the entire block. If I press left, then it will move me to the start of that block. Effectively jumping me to that point. The problem of course is that if I were to type that from within this paragraph I'm typing:

You can see that I'm in the scope of a paragraph. So... that won't work to well. If we press ctrl shift A again it will expand the scope to the next parent, and so on. So I see two options here:
- we chain ctrl+shift+a commands and somehow know when to stop
- we write something to seek to the </section> and then trigger it
Or, I suppose, maybe simpler, we just write something to seek to the start of the section for us. I could also just remember to spam ctrl shift a, but... that's kind of annoying, isn't it? It's a bit of an awkward keyboard combination, so I'd like to avoid it if I can.
While searching the web for clues about how we could do this in a way that doesn't involve a reg ex, I tried to see if I could do any sort of "move by scope" type thing. And I stumbled onto this move by symbols plugin. And, yes, I had forgotten about symbols. I do use the ctrl+r shortcut to jump to function definitions, but the thought of doing that command within an HTML file never occured to me. So... what does it do?
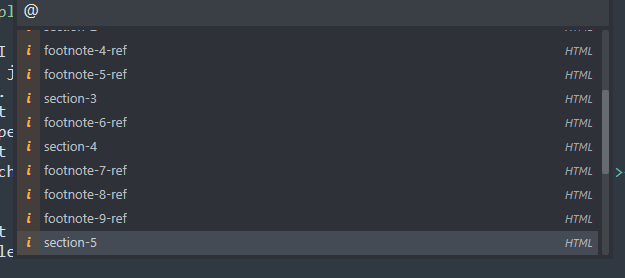
By jove! I can navigate from id to id within this! Well that sort of solves the problem for me doesn't it? Heck, the current section I'm in is even suggested. How does this neat thing work I wonder?
The community docs document this with a lot of info but I also noticed that these particular symbols in the goto menu are coming from the HTML plugin... which we have the source for and looked at in the last post. Inside of the file Symbol List - ID.tmPreferences I find this:
<?xml version="1.0" encoding="UTF-8"?>
<plist version="1.0">
<dict>
<key>scope</key>
<string>text.html meta.toc-list.id.html</string>
<key>settings</key>
<dict>
<key>showInSymbolList</key>
<integer>1</integer>
</dict>
</dict>
</plist>
So. The HTML plugin is defining symbols based on the scope strings for ids, which is handy.
If section has its own scope, then perhaps we could add in our own symbol list with our plugin
to make it possible to give those? Using ctrl shift alt P (which is an awkard
hotkey but not one which one uses often) I can see:
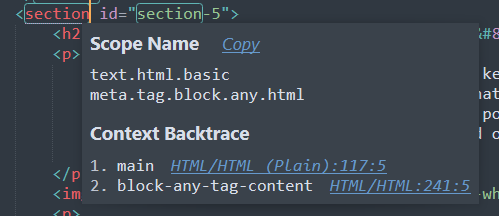
I don't think I'd want to make any block be a symbol. That sounds like a nightmare. … Let's do it for fun though!
And save… then press ctrl r and …
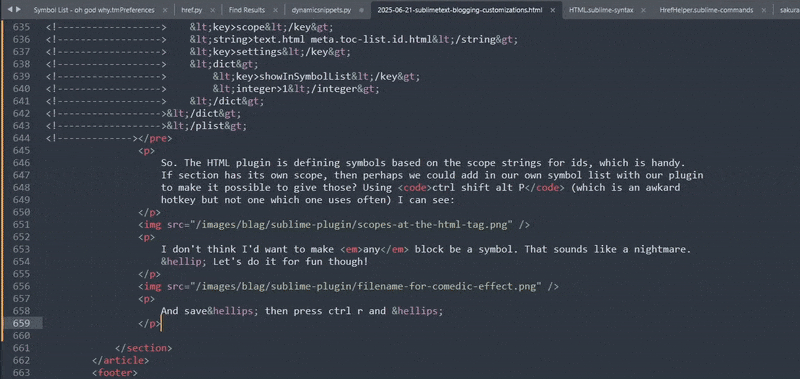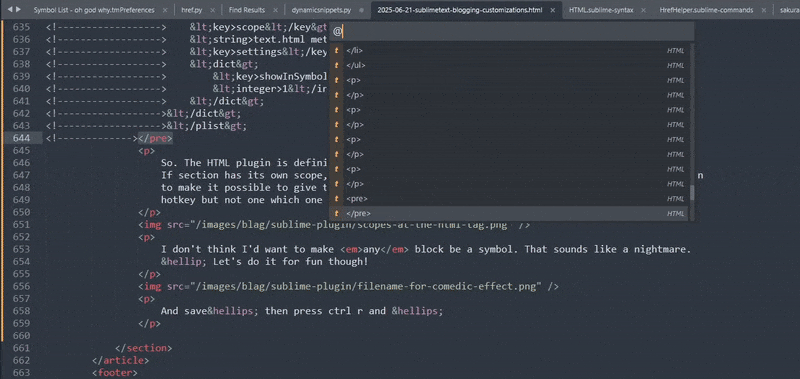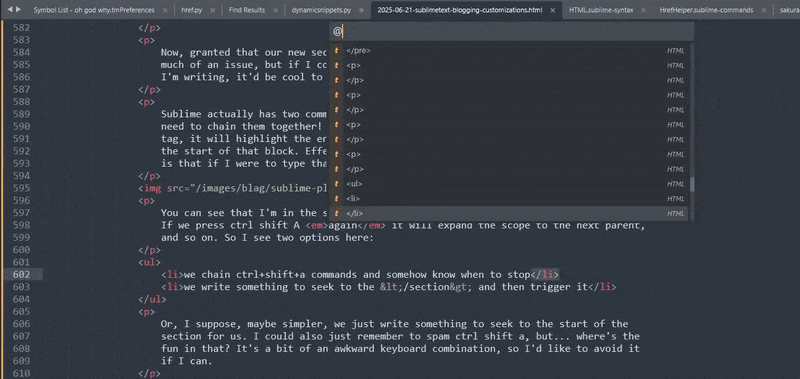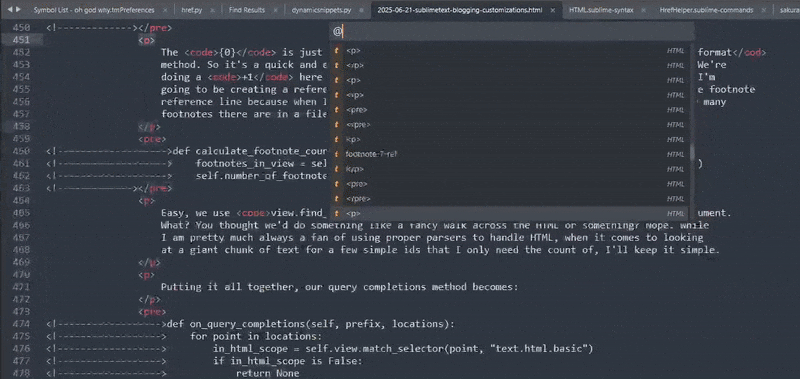

Heh. While this is making me giggle, I don't think it's quite what I want. 10 Still. It's good to know that I can add a symbol to the lookup table pretty easily. Just, I wish I could define it a bit more easily. The goto anything window is really powerful though, if I just type in section then the ids could probably suffice for my purposes:
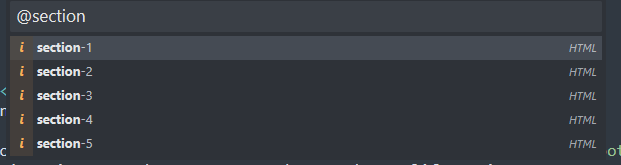
It seems like if I wanted to define my specific way of blogging into the symbol table, I'd need to actually create my own syntax file and define the scopes. Which seems, haha, a bit out of scope I think. The discovery of the fact that the HTML plugin provided by sublimetext gives me a way to pop from id to id is enough for our purposes to replace the dom navigation of vscode.
Fun adventure though! One last thing before we wrap up though:
Reading time ↩
I think it was maybe a few weeks ago that I was talking in clonq's discord/irc server with some folks and we talked about reading time. As you all have probably noticed, I like writing! And my particular style of writing can be a bit verbose and meandering sometimes. I like to share the journey with you all after all, and it's always a long meandering rode to the end goal with most of my projects.
So, wouldn't it be nice if I could slap a "reading time approximately FOO minutes" or something up at the top of the post to make people's lives easier? I think that, much like the snippets that we created before, we can do this dynamically and make life super easy for us. The only trick of course is I suppose it'd be nice to just recalculate it and auto-update the value as I write the blog post. Well, not as I write, that'd be a bit much, but I think recalculating it before I save would be ideal.
This is my game plan here:
- Find an algorithm to compute reading length
- Hook up a dynamic snippet that inserts it into the file somewhere
- implement some hook to keep it up to date
- make sure I only count the words in the main tag
So... to the internet!

According to the first result for average reading speed (that isn't AI slop bullshit) the breakdown of average reading speed is:
| Grade Level | Age Range | Reading Speed (wpm) |
|---|---|---|
| 1st Grade (Spring) | 6–7 years old | 53–111 wpm |
| 2nd Grade (Spring) | 7–8 years old | 89–149 wpm |
| 3rd Grade (Spring) | 8–9 years old | 107–162 wpm |
| 4th Grade (Spring) | 9–10 years old | 123–180 wpm |
| 5th Grade (Spring) | 10–11 years old | 139–194 wpm |
| 6th–8th Grade (Spring) | 11–14 years old | 150–204 wpm |
| High School | 14–18 years old | 200–300 wpm |
| College | 18–23 years old | 300–350 wpm |
| Adults | – | 220–350 wpm |
My blog is targetted towards people who like programming. And people who seek it out and want to read. So assuming that range at the end, 200-350 wpm seems like a safe bet. Since I include code snippets, and it might take some time for people to digest that, I think I'll take the lower bound as the average word speed. And so, all I should have to do is divide how many words are in my blog by 200 then!
Great, so uh... how do I get all the words in my blogpost? A quick browse through the sublime API reference finds me a few useful methods. We can get any substring from the view if we can give it a region. And we can make a region based on the full size of all the characters in the view, so then this:
full_region = sublime.Region(0, self.view.size()) all_content = self.view.substr(full_region)
Should work out. Once we've got that potentially very large glob of HTML, how do we deal with it? Well. Remember what I said not too long ago about how I was fine with using a regex for finding things like ids and section tags? Well. I'm not fine with trying to parse HTML with them though
Luckily for us, python has a super simple HTML parser we can use to the job done! It's a super simple visitor pattern style walker and if we just watch for the start tags of main, and then the textual tags to pull out words, then we'll have this done super quick!
from html.parser import HTMLParser
class MyHTMLParser(HTMLParser):
def __init__(self):
super().__init__()
self.reading_time = 0;
self.words = 0;
def handle_starttag(self, tag, attrs):
# Restart the count!
if tag == "main":
self.reading_time = 0
self.words = 0
def handle_endtag(self, tag):
if tag == "main":
self.reading_time = self.words / 200
def handle_data(self, data):
words = len(data.split())
self.words += words
A notable callout here is that by default, split on a string:
If sep is not specified or is None, a different splitting algorithm is applied: runs of consecutive whitespace are regarded as a single separator, and the result will contain no empty strings at the start or end if the string has leading or trailing whitespace. Consequently, splitting an empty string or a string consisting of just whitespace with a None separator returns [].
Which is perfect, because doing something naive like .split(" ") would
cause us to count WAY too much as a word. Technically speaking, just splitting on
whitespace is going to probably lead me to overcount a little bit. When I went
searching around, there were a lot of people recommending regular expressions,
and my first instinct was to reach for \w, but I compared the results
of some of the paragraph word counts to an online word counter and the default
splitting was a match. So... let's keep it simple.
Mashing these things together with another sublime view listener to handle the hooks we care about:
class ReadingTimeViewEventListener(sublime_plugin.ViewEventListener):
def __init__(self, view):
self.view = view
def on_pre_save(self):
if not self.view.match_selector(0, "text.html"):
return
parser = MyHTMLParser();
full_region = sublime.Region(0, self.view.size())
all_content = self.view.substr(full_region)
parser.feed(all_content)
print(parser.words)
print(parser.reading_time)
Now, notice that I'm doing this on on_pre_save and not
on on_pre_save_async. This is intentional because what I want to
end up doing is modifying the contents of my file before I save it
to include the reading time. I won't be keeping the prints here, those were just
to get an idea if it's working or not, and right now if I open the debug console
in sublime I see
5466 27.33
And if I copy and paste from the browser I'm using to preview my post and dump it into a word counter online? 5422 words. I expected to be a bit off, but this is closer than I anticipated! And about a half hour seems about right to me. I suppose when I proofread once I'm done 11 I'll double check to see that the reading time is mostly accurate. Though I've been reading novels since 1st grade and generally consider myself a pretty speedy reader.
Anyway! We've got a number! Let's make it easy to automatically keep reading time up to date! We know that we can jump to symbols easily, and so I think what would make sense is to define an element on the page with an id that we can tweak automatically and if it exists do so. This is easier than you think!
print(self.view.symbols())

The text might be a bit small and hard to make out. But, believe me when I say that
we've got a bunch of tuples that include a Region and an identifer.
This is going to be so easy!

Since I'll want each blog post to have a reading time going forward, I think it makes sense to just update our new blog post template with it. I'll just include the small amount of XML I changed:
<main>
<h1>$4</h1>
<p>
<time datetime="${2:YEAR-MM-DD}">Published ${5:Month N, Year}</time>
<small>Estimated reading time <span id="reading-time"></span></small>
</p>
And if I filter the list of tuples down to this?
reading_time_symbols = [item for item in self.view.symbols() if item[1] == "reading-time"]
print(reading_time_symbols)
if not reading_time_symbols:
return
[reading_time_region, _] = reading_time_symbols[0]
print(reading_time_region)
full_line_region = self.view.full_line(reading_time_region)
print(self.view.substr(full_line_region))

Perfect. I'll kill off the print statements but they're the easiest way to show you all
that it is indeed working! One trippy thing for me was that the full_line
method doesn't return the text, but rather the Region of the line. Very easy to blink
and miss that subtlety.
Anywho, that "30 minutes" is just dummy text I added in, so now we've got to compute
a nice little string and then use self.view.replace to replace the
line with one that has the right data in it. I think I'll cut things up by 5 minute
chunks because it really doesn't seem accurate to tell someone that it will take
33.424 minutes or some such nonsense.
def make_human_reading_time(self, reading_time):
how_many_five_minute_intervals = int(reading_time / 5)
how_many_hours = int(reading_time / 60)
out = []
if how_many_hours > 0:
out.append(f"{how_many_hours} hours")
leftover_five_minutes = how_many_five_minute_intervals % 12
if leftover_five_minutes > 0:
out.append(f"{leftover_five_minutes * 5} minutes")
if not out:
return "Less than 5 minutes"
return ", ".join(out)
And a quick test:
print(self.make_human_reading_time(180)) # 3 hours print(self.make_human_reading_time(120)) # 2 hours print(self.make_human_reading_time(133)) # 2 hours, 10 minutes print(self.make_human_reading_time(3)) # Less than 5 minutes
I'm rounding down in the case of 133 since its not a full
5 minute increment. I suppose I could do a +1 to the interval count
and round up instead, though that would mean I'd never hit the
"Less than 5 minutes" case, not that I think I write many posts that
small anymore… I'll leave it as is for now, if it feels wrong
once I start using it I'll adjust it later.
Now, once I've got the text, the next question is how do I insert it? According to the reference guide for the API, the replace function has this signature:
replace(edit: Edit, region: Region, text: str)
Replaces the contents of the Region in the buffer with the provided string.
reference
Okay, so it takes an "Edit"… how the heck do I get one of those? Let's look at its documentation...
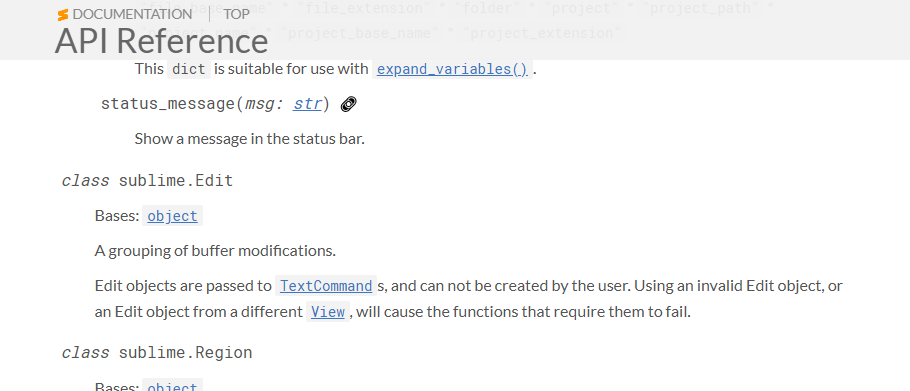
can not be created by the user.
What do you mean I can't create an edit?

Wait wait wait, no, hold on. A plug can totally change the view. There's an API for it! Heck, the hello world plugin inserts text as its example!
import sublime
import sublime_plugin
class ExampleCommand(sublime_plugin.TextCommand):
def run(self, edit):
self.view.insert(edit, 0, "Hello, World!")
Ah, I see, run from the TextCommand …
Wait, but can't I... Aha!
yes! Yes I can indeed! We can use run_command to run an arbitrary command if we've defined it!
Let's get a hello world going real quick:
class UpdateReadingCommand(sublime_plugin.TextCommand):
def run(self, edit):
print("hello!")
And then tweak our on_save hook to run the command...
def on_pre_save(self):
if not self.view.match_selector(0, "text.html"):
return
reading_time_symbols = [item for item in self.view.symbols() if item[1] == "reading-time"]
if not reading_time_symbols:
return
full_region = sublime.Region(0, self.view.size())
all_content = self.view.substr(full_region)
self.parser.feed(all_content)
[reading_time_region, _] = reading_time_symbols[0]
reading_time_line_region = self.view.line(reading_time_region)
new_time_text = self.make_human_reading_time(self.parser.reading_time)
self.view.run_command("update_reading", {
"region_to_replace_start": reading_time_line_region.begin(),
"region_to_replace_end": reading_time_line_region.end(),
"new_time_text": new_time_text
})
And then save my file and...
File "sublime_text_build_4180_x64\Lib\python38\sublime.py", line 2894, in run_command
sublime_api.view_run_command(self.view_id, cmd, args)
TypeError: Value required
Wait huh. Wait how does the run command work for the TextCommand class again?
Called when the command is run. Command arguments are passed as keyword arguments.
Oh right. We've got to name the arguments. Right, right:
class UpdateReadingCommand(sublime_plugin.TextCommand):
def run(self, edit, region_to_replace_start, region_to_replace_end, new_time_text):
print("hello!")
Now I press save and

Perfect! Ok, so now we can use that self.view.replace command!
class UpdateReadingCommand(sublime_plugin.TextCommand):
def run(self, edit, region_to_replace_start, region_to_replace_end, new_time_text):
text = " <small>Estimated reading time <span id=\"reading-time\">{0}</span></small>".format(new_time_text)
self.view.replace(edit, sublime.Region(region_to_replace_start, region_to_replace_end), text)
Yes, the annoying whitespace is neccesary in order to make sure that the text is inserted properly. It matches the update to the new blog snippet and I just realized I hadn't had dinner yet and so I'm not going to spend the extra time to figure out the region for the start of the small tag. But that said, the important question is, does it work?

Well look at that! It's working! It's working! 12

Wrap up ↩
Alright let's call it a day! We've made a ton of progress and automated a ton of simple things to make my editor help me write blog posts better. You might have noticed that there's plenty of footnotes in this post, and I can definitely attribute the ease of creation to that. 13
We made static snippets with the XML syntax sublime likes for the stuff that doesn't change much over time. We made dynamic snippets that smartly set themselves based on the context of our blogpost. And lastly, we figured out how to automatically set the reading time and keep the blog post up to date! That's pretty awesome. I think there's still a few things that I can do to improve my workflow even more in the future though:
- Automate the date setting, similar to the reading time
- Create a command to encode entities and add prefixed HTML comments to pre tag content
- Write up some snippets to generate my RSS feed item template so I don't have to keep looking up GMT timezone formats
- Whatever else floats up in my head as I write about those 3!
Unfortunately for me, I've got a big work trip this upcoming week and travel tends to take it out of me, so I imagine that my next post might take a bit longer to get out. But I hope you all enjoyed this one! And if you think of any helpful things that I might consider doing, I'm all ears! But, I was so into writing this post I forgot to eat dinner… 5 hours ago. Wups.

As noted before, the source code for this sublime plugin is right here