
A familiar beast ↩
The hardest part about this post of course is that since the origin is code from a private source, I have to twist and turn things in order to construct an approximate example and do my best not to lose the essence of the issue. Thankfully, in this case, it's pretty simple to abstract what the problem is:
Let's say you've got a system which is responsible for taking some internal company data, mishing and moshing it around a bit, then sending it off to some external system and keeping track of any sort of problems or successes along the way. Sounds familiar? 1 You probably have something like this in your world if you're anywhere adjacent to the web world in what you do.
The devil's in the details though, so let's describe this in code and I'll trust you to use your imagination to fill in 100s of lines of boilerplate or logging that I'm omitting to get the main point across. We'll do this in javascript 2 and I'm writing this in my HTML file here, so if I get some syntax slightly off, forgive me. The point isn't syntax. It's what you're about to experience here:
class StuffSender3000 {
constructor(service1, service2, service3, ...) {
... assign all those inverted dependents into our will and testament ...
}
async sendStuffTo3rdParty(identifer) {
let importantFlagForLater = false;
...10s more of setup variables and such for logging and sensing...
let otherFlagForLater = false;
let trackingInfo;
const rawData = await this.internalSourceService.getRawData(identifier);
const configurationData = await this.service1.getConfigForType(rawData.typeOfThing);
const enrichedData = await this.subFunctionToWrapItAndAddToIt(
rawData,
configurationData
);
try {
const requestDataFor3rdParty = await this.service2.processTheDataInto3rdPartyForm({
enrichedData, configurationData, ... other variables and flags...
});
trackingInfo = await this.database.getTrackingFor(identifier);
if (!trackingInfo) {
const result = await this.thirdPartyThing.createNew(requestDataFor3rdParty);
if (result.successful) {
trackingInfo.propertyFromResult = result.importantInfo;
trackingInfo.idFor3rdParty = result.id;
otherFlagForLater = result.flagValueForTroubleshooting;
const success = await this.database.updateTrackingFor({
identifier, trackingInfo
});
... handle database success or fail ...
... set some flags and other things for later ...
} else {
trackingInfo.propertyFromResult = undefined;
trackingInfo.otherLoggingInfo = result.infoAboutThing;
const success = await this.database.updateTrackingFor({
identifier, trackingInfo, result.errorMessaging,
});
... handle database success or fail ...
... set some flags and other things for later ...
}
const await this.service3.changeGlobalStateForThing(identifier);
await this.service4.runSomeHooksAndStuff();
} else {
await hackSomeoneAddedInYearsAgoToFixSpecificThing3rdPartyRefusesToFix();
const result = await this.thirdPartyThing.update({
trackingInfo.idFor3rdParty, requestDataFor3rdParty
});
if (result.succesful) {
trackingInfo = await this.database.createTrackingFor({
identifier, flagsAndOtherInfo
});
// similar code to above, but slightly different because fields move
// around because the 3rd party developer system was built by drunk
// monkeys. 3
} else {
// Similar code as above
}
}
} catch (error) {
if (error.name === 'DUPLICATE_DURING_CREATE') {
// The 3rd party has this stuff already!
const preExisting3rdPartyThing = await this.thirdPartyThing.readThing({
error.data.idOfExisting
});
const result = await this.database.update3rdPartyIdForThing({
identifier, trackingInfo, preExisting3rdPartyThing.id
});
// Now do the same sort of logging as before, but no need to call
// the 3rd party since it already has this piece of data.
}
if (error.name === 'SOME_OTHER_RECOVERABLE_ERROR') {
... deal with it and recover to a good state
... yada yada, get all the flags set and 3rd party calls
}
// Better track that error, and hope the originating err wasnt your db
// in the first place!
if (!trackingInfo) {
// not tracked yet, needs to be
trackingInfo = await this.database.getTrackingFor(identifier);
trackingInfo = await this.database.createTrackingFor({
identifier, trackIngInfo, error, flagsAndOtherInfo ...
});
} else {
... we can re-use the trackingInfo that was created before the error happened ...
const result = await this.thirdPartyThing.update({
identifier, trackIngInfo, error, flagsAndOtherInfo ...
});
}
}
return {
importantFlagForLater,
...
otherFlagForLater,
...trackingInfo
}
}
}
Go ahead and digest that for a moment. Good? Got your head wrapped around it? Filled up that context wagon you call a mind and are ready to tweak something or add in just one more tracking flag to answer a question about something that some stakeholders needed to know about going forward? Great, on a scale of Sherlock to Nazuna, where are you right now?


I'm going to guess that you're either somewhere in the middle, or somewhere closer to the expression that Sherlock has. While there are probably plenty of people who would look through this and sigh with some form of
- It is what it is
- We don't have time to fix it
- Tracking all that state is complex, so the code is complex
- We need the feature now, so hold your nose and add it in
I'm rather doubtful that anyone looks at the above code and whistfully sighs and says "Ah yes, what beautiful code that is". Well, unless their definition of beauty includes repeated code, multiple nested conditionals that vary only slightly, and all the other stuff that's crying out hidden away by all those … and hand waving comments. I'd assume instead, that probably, if you were in this codebase, you'd instead be saying:
There must be a better way to do this.
Design Patterns? ↩
Talking about this particularly gnarly nut of code with my coworker during our last IRL get-together, he was wondering about if it'd be possible to refactor the code to use the Chain of responsibility pattern to deal with it. Over the course of a few vanilla bean old-fashions at the hotel bar, we discussed and talked through the idea. Primarily picking holes in where it falls short.
If you're unfamiliar and don't want to read the wikipedia link, gang of four book, or nice examples on the refactoruing guru website. Here's my quick intro to the CoR pattern. In essence, you have a list of higher-order functions which should be applied in order unless one of them decides to pause the whole operation. In a more practical example, the way that express servers in JS handle routing is a pretty explicit example of this:
const callback1 = function (req, res, next) {
console.log('callback1')
next()
}
const callback2 = function (req, res, next) {
console.log('callback2')
next()
}
app.get('/example/d', [callback1, callback2], (req, res, next) => {
console.log('the response will be sent by the next function ...')
next()
}, (req, response) => {
response.send('Hello from D!')
})
So long as each callback calls next, the function is free to do
whatever it likes and then tell the next thing in the chain to do what it wants.
If next() is never called, then the processing stops and the handler
has to response.send or else you'll get a dead hanging request.
The gang of four's design pattern book uses a more interesting example of GUI
handlers. And if you've ever written the code event.preventDefault()
while writing an event handler in Javascript for some HTML site, then you've
essentially interacted with the way that sort of thing works when it comes to
if a button, or any html element really, can handle some event that bubbled up
the chain to them (like a mouse click).
Anyway, the main problem with the chain of responsibility pattern is that it has one path only. And, if we consider the giant code block from earlier, it's clear that there's more than one path. The final destination is the same, we always want to save some tracking information to a database, but we don't even always send data off to the third party! 4 In essence, there's branching. And as you can see in the classical examples of the chain of responsibility, they don't really care to talk about that case much.
Not that you can't do it though. The trick I think here would be that you'd need some way to modify the chain that you're residing in at runtime. Which sounds like spaghetti by a different name to me.

Part of the reason the chain of responsibility is typically attractive is that it allows you to reason about something within relative isolation. You're still dependent on some form of contextual information being passed along the chain, but in its purist form, you should be able to do whatever it is you need without having to assume that any other handler came before you. 5 But the problem is that since a handler is isolated then how do you know which handler to come next?
As we saw in the express example, there has to be some form of setup that dictates the chain. But if you remove that, and instead allow each link in the chain to choose their next friend. How do they do signal that to the overall system? If there is no system, then perhaps you could use dependency injection to deal with it:
let nextHandler;
try {
if (pathAIsAGo()) {
nextHandler = injector.get('Step2aHandler');
} else {
nextHandler = injector.get('Step2bHandler');
}
nextHandler(context);
} catch (error) {
nextHandler = injector.get('Step2ErrorHandler');
// add the error to the context or whatever
nextHandler(context);
}
And I suppose that could certainly work. However, assuming that you have a step that can happen in more than one place, then what sort of flags or sorts of methods are we going to have to expose in order to ensure that something that's executing and taking one path doesn't accidently hop to the wrong place? For example, if we had a set of handlers like this
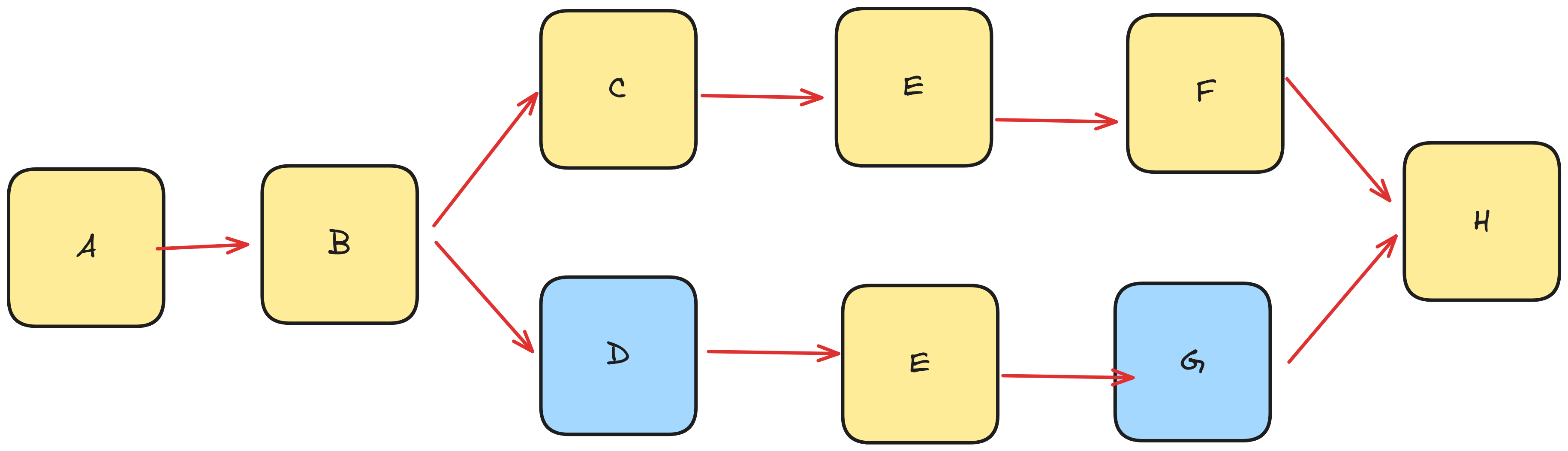
How do you make sure that E calls F in one case, and G in the
other? Assuming that E does the same operation, and really is just some sort
of pure function that doesn't change it's input (say it's writing to the
database some logs and then moving along), then how would it know who to
ask for from this hypothetical injector?
Well, obviously you'd set it up ahead of time of course, right? Some sort of
setNextHandler for just E in which case, then we'd
end up with some form of validation like
... in some setup code ...
e.setNextHandler(f);
e2.setNextHandler(g);
... inside of e's execution handler: ...
if (!nextHandler) {
// no handler registered by setup... who do I call now?
}
and we've officially mixed both dynamic and static handler setup and will
probably be paying the consequences of this in the future during some last
minute debugging session. Or when a new person joins the team and asks the
sane question of "How come B chooses the next handler within its handle
method, but E doesn't?" You might start to sputter out "Because
B needs to choose the next chain of responsibility handlers dynamically E doesn't".
And while that's an answer. To me, it still doesn't feel like we've
really landed where we want to be.
No, I think that we can do better. We know what the flow of execution should be. I think that while the pattern feels like it could mostly fit. That there's a way to do this in a nicer way that keeps each step discrete, but still allows us to see how things work at a high level and easily plug and play the logic statically.
Eithers aren't enough ↩

I recently read through the book Domain driven design made functional which had a lot to say about function chaining and the sorts of things you find in F#, haskell, and other functional languages. I've only ever been exposed to F# through that book, and Haskell through a meetup I went to once after attending a compiler class. So, I'll be using scala 2.11 as my basis for showing some of these concepts. The first of which, is an either.
Let's say that we had defined our generic framework as something like this. Each handler can either return one value, or another, and it requires some context to function. This, could be expressed like so:
trait Handler[L, R, C] {
def handle(c: C): Either[L, R]
}
The nice thing about an Either is that it has a left, and a right
side (hence the L and R generics). And that the container
type, Either, can be maped just like every other
monadic lookin' thing in the language. Prior to 2.13, the type had no bias, and
therefore when you processed them in
for comprehensions
, you'd have to do something like this:
val aHandler = new Handler[Int, Int, Int] {
def handle(start: Int) = Right(start + 3)
}
val bHandler = new Handler[Int, String, Int] {
def handle(context: Int) = Left(context + 3)
}
def bRecoveryFunction(err: String): Int = {
println(err)
2
}
// Scala doesn't like an a = aResult on the first line.
val aResult = aHandler.handle(10)
val result = for {
a <- aResult.right
a <- aResult.left.map(_ => 1)
bResult = bHandler.handle(a)
b <- bResult.left.map(l => l + 1)
b <- bResult.right.map(bRecoveryFunction)
} yield b
println(result) // This prints 17
While the syntax of for comprehensions, and their name, might be a bit unfamiliar. This is a way to express pipelining, or sequencing, as it might be called in other functional languages. Essentially, it lets you say that this thing happens first, and then take its result and use it in the next operation. This could also be expressed with pattern matching or with folding like so:
val a = aHandler.handle(10) match {
case Left(_) => 1;
case Right(as_is) => as_is;
}
val b = bHandler.handle(a).fold(
l => l + 1,
bRecoveryFunction
)
Eithers in 2.11 and back weren't considered "real" monads because they had no bias. But after 2.12 they became right biased, which meant you could write a comprehension like
for {
a <- Right(1)
b <- Left(2)
c <- Right(3)
} yield a + b + c
And it would produce 2 because the Left would short circuit
things and you'd never compute c. This sort of behavior is pretty useful. In fact,
if you want to think about the chain of responsibility again, this is the exact same
thing as saying that handlers that return Right have called next()
in their chain, and if they want to stop execution, then they can return Left.
While eithers are a bit awkward to use, they can still bring a good amount of clarity
to seeing a sequence of operations. After all, instead of having large blocks within
if {} else {} and a long vertical read. They encourage moving things out
to seperate functions, or into small anonymous lambda functions that can make for
better reading. Case in point, walking through the general outline of that monster
method I shared before and converting it into a lose idea of what it could look like
in a for comprehension might look similar to this:
val context = new RequestContext()
for {
rawData <- this.internalSourceService.getRawData(identifier)
configurationData <- this.service1.getConfigForType(rawData.typeOfThing)
enriched <- this.subFunctionToWrapItAndAddToIt(rawData, configurationData)
trackingResults <- for {
thirdPartyDat <- this.service2.processTheDataInto3rdPartyForm(...)
trackingInfo <- this.database.getTrackingFor(identifier).fold(
{ _ =>
thirdPartyThing.createNew(thirdPartyDat)
},
{ trackingInfo =>
hackFromYearsAgo(...)
thirdPartyThing.update(thirdPartyDat)
})
_ <- database.updateTracking(trackingInfo)
} yield trackingInfo
result <- trackingResults
.left.map(recoverDuplicateError(...context...))
.left.map(recoverSomeOtherError(...context...))
.right.map(recoveredInfo => this.database.updateTrackingFor(recoveredInfo))
} yield result
Note that I'm handwaving quite a bit here since in order for this to work, you'd need to ensure that things chained together are compatible with each others return types, as well as ensure the context is passed from one thing to the next, or given as an "evil" mutable object to be modified as desired by each handler.
However. If I asked you where we do the hack from a few years ago in the code that's responsible for sending data to the 3rd party in the send-o-tron 3000, I'd bet you you'd be able to find that needle in this functional haystick a hell of a lot faster than in the code we started with. Granted, we're now working in scala instead of JS, but the ideas and methods to decompose things into more pure functions can apply to Javascript just as much as to another language, it might just take more time and be harder not to introduce bugs due to the lack of static typing.
That said. It's still a bit tricky to follow as there's a good amount of implicit things assumed about this code. What if instead of working with monadic-lite things such as Eithers, we ditched them all-together and went for something a bit more explicit?
Tagged Unions and DDD ↩
Let's swap back to Javascript. Or rather, let's swap back to the much more feasible friend known as Typescript. Though, I won't be able to let slip showing just one more little scala example. The scala example I could also do in rust I suppose, but since I've never pushed rust into production, and have pushed a lot of scala, I'm more comfortable giving you all illustrative examples with scala than not.
Anyway, about a decade or maybe a little less ago, I was reading about "domain driven design" (DDD) on some blog. It was probably linked off of the neophytes guide to scala or some discussion thereof since that was essentially my bible at the time for good practice ideas. Either way, the idea was pretty simple.
Stop using exceptions as control flow dummy.Ok, that's not all of what DDD is, but at the time, that was probably one of my chief take aways. Because when you stop doing that, you end up no longer writing code like this:
def errorsAreControlFlow(foobar: Int) = {
try {
if (foobar == 0) {
throw new Exception("hahahaha")
} else {
println("I'm happy")
}
} catch {
case e: Exception => println("lets do the recovery now")
}
}
errorsAreControlFlow(1);
errorsAreControlFlow(0);
... this prints out:
I'm happy
lets do the recovery now
This contrived example illustrates what you might be doing in some code somewhere, and also illustrates what our sample send-o-tron 3000 code was doing. When you stop and actually think for a moment, it's pretty simple. Why the hell are you treating something that is expected as something that is exceptional? You're not surprised in the morning when you reach for a box of cereal and you find that it's empty because some little munchkin ate it all and left the box. No, you moan a bit about it and groan, but you take the auxiliary action you planned for and open a new box that you planned ahead for.
We don't stop the world, throw the bowl we had in our hand on the ground, tear open the carton of milk and pour it down the drain and then buy a new bowl, milk, and open the 2nd box of cereal. So why do we do it in code? When you throw an exception somewhere deep in the stack, then recover it way way up somewhere else, you end up throwing away all context and you're behaving like some crazy person having an episode and literally crying over spilled milk. We're not buying bags of milk inside of milk inside of milk right now.
 stop that
stop that
Instead, consider the same code but without the exceptions:
sealed trait ShitThatCanHappen
case class WeHadAZero(foobar: Int, someContext: String) extends ShitThatCanHappen
case class WeAreHappy(though : String) extends ShitThatCanHappen
def betterControlFlow(foobar: Int): ShitThatCanHappen = {
if (foobar == 0) {
WeHadAZero(foobar, "hahahaha")
} else {
WeAreHappy("I'm happy")
}
}
println(betterControlFlow(1))
println(betterControlFlow(0))
... prints
WeAreHappy(I'm happy)
WeHadAZero(0,hahahaha)
What have you gained? Obviously, we don't throw an exception anymore, which means
that the runtime environment our code is executing in doesn't need to stop the world
and gather stack trace info, so the code will be faster. But we're not looking to optimize
speed for the CPU here, we're looking to optimize developer experience. And if you're looking
at the function errorsAreControlFlow you have no idea what it might do for you,
does it throw an exception? Why would it? But betterControlFlow returns a type
that tells you everything that's expected for it to do.
And that's valuable. So, in a language such as scala, rust, or any language supporting tagged union types, we could produce something useful like this for all of the various actions and consequences we expect to see show up, and then produce a set of types and containers to match against. Boy, that'd be so nice. Imagine how explicit and easy to follow something like:
ArticleCreated(...); ArticleUpdated(...); DuplicateArticle(...); ErrorRecoveryFor(a: Action, ...);
Could be if those were our types... Sadly though, our original example started in Javascript. And that doesn't support this type of thing, nor does it have static types for a compiler to tell us if we haven't checked every potential subtype of some interface. Javascript is dynamic after all, and that it's strength for dealing with the loose nonsense of the user-input filled web.
But what about something like typescript? Looking through the cheatsheets on the official language site, I do spot some words that give me a bit of hope: Discriminated Union, but looking at the example code:
type Responses =
| {status: 200, data: any}
| {status: 301, to: string}
| {status: 400, error: Error}
const response: Responses = ...
switch(response.status) {
case 200: return response.data
case 301: return redirect(response.to)
case 400: return response.error
}
This... is just a switch statement. Either the example isn't illustrating the point very well,
or I'm missing something. Obviously the compiler here is able to tell us that we can safely
call to within the case body, but that's not quite the same thing as illustrated
above. But, we could probably get somewhat close!
type Stage = 'initial fetch' | 'data formatted' | 'creating 3rd party' | ...
type ContextData =
| { stage: stage, rawData: ..., configData: ..., enrichedData: ..., ... }
| { stage: Stage, enrichedData, configData: ..., thirdPartyData: ..., ...}
| { stage: Stage, enrichedDaata, ..., trackingInfo, ...}
I'm hand waving the types on the contextual information here, but take notice we're
using discriminated unions to create a stage value that we can use to
track where the heck we are, and also, where the heck we were should we throw an exception.
The good thing is that you don't have to define every type in the union all at once, this works just fine:
type Stage = 'A' | 'B';
type ContextA = { stage: Stage, foo: number};
type ContextB = { stage: Stage, bar: number};
type Context = ContextA | ContextB;
const c: Context = { stage: 'A', foo: 0};
switch (c.stage) {
case 'A': console.log('hi a'); break;
case 'B': console.log('hi b'); break;
}
If you were to look at our mega monster method from before and break down each code path into
a "stage" and give it a name, then define the expected context you have during that moment into
the type of the context data. Then you'd be able to write some functions to process those
explicit types, in which case the compiler would be checking for you that you only end up in
that area if you came from that context. Imagine how nice it would be look at the catch
of the try in that situation and do a logger.log(..., stage, ...) and when you're
trying to trace some production code being told instantly that you were in the middle of stage X.
That'd be a nice developer experience.
Similar, if you were breaking this down into helper methods, similar to how the scala code did in order to produce the for comprehension sequence, you'd be able to have the typescript compiler check your work. Ensuring that each part of your code was doing something like
// assume we defined ContextData and this is one of them
type TheType = {stage: 'specific stage', ...};
async helper(contextData: TheType): OurActionType {
...
}
And then at the call site where you're weaving the methods together like:
const tracking: TrackingActionResult = await this.database.getTrackingInfo(identifier);
switch(tracking.stage) {
case TrackingActionResultType.REQUIRES_CREATE:
...
case TrackingActionResultType.REQUIRES_UPDATE:
...
}
You'd be pretty explicit about what's going on and which actions you're taking. Granted, you'd have to be alright with putting these switch statements in places like this, and it really depends on your helper methods as far as trying to not just replace one mess of nested if statements for a mess of bunches of switches and function calls. There's considerations about making sure people remember to break or return out of the cases and other gotchas we'd need to keep in mind.
With a strong compiler, this could work just fine. Typescript's compiler is pretty impressive, especially given that you can literally run DOOM within its type system. So no doubt you could definitely create a bunch of wrappers and helpers and end up with something that beautiful chains functions end to end in a functional programmers dream.
But that code still has the same problem as where we started. Chaining the functions means that they are all interdependent on each other to some extent. It's just that those relationships are now formally declared in the type system, and so the programmer in charge of trying to maintain this can proceed to offload some of the contextual awareness they keep to the static types being checked by the proofer in the compiler.
As you may guess. I'm not satisfied with this. So. Let's use the rubble of our exploratory crusade behind us to circle back to the original language, which does not have any of the goodness of a static type system to support us, and think about how we can successfully aim the footgun away from ourselves.

Back to the Pattern ↩
As I hinted at in the second section, the Chain of Responsibility is really close to what we need. The critical lacking part is that it's far too messy to try to dynamically set the path. That way leads to bugs, confusion, and the dark side of the force. Maybe. So. The simplest way to solve this is to take a step back and be more declarative.
When thinking about this sort of thing, I like to put aside silly notions of reality and just think about what I'd like the code to feel like. And so, with that in mind. I'd really like to be able to do something like this:
const plan = planner
.fetchData(identifier)
.setContext()
.enrichData()
.formatForThirdParty()
.getTracking()
.branchWithPlan()
.isTrackedCheck()
.doHackFromYearsAgo()
.update3rdPartyData()
.recoverDuplicateError()
.updateTracking();
.endBranch()
.branchWithPlan()
.isNotTrackedCheck()
.create3rdPartyData()
.recoverDuplicateError()
.createTracking()
.endBranch()
.collectFlags()
.end()
This probably feels similar to the for comprehension in the sense that you can very easily see what's happening at a high level. For those of you familiar with "fluent" builders, this probably looks and feels familiar. Underneath the hood, this isn't actually runing any code. This is going to build a list of Commands that need to be executed.
I've talked at length about how useful the command pattern can be, it is very powerful when combined with a builder like this. It lets us build up an easy to read sequence of operations, and then all we need is an executor to process the plan. If we build up small chains that behave like chains of responsibility in isolation, but that can be combined and processed together, passing context along from one part to the next, then we've got the best of both worlds, and have essentially created a builder for something similar to the pipeline pattern
In order for this to work properly we're going to need an executor for the plan that's been built up, and that's going to need to handle the details about how to handle the commands themselves. We can use dependency injection like I mentioned before to isolate handlers for each command so that they stay easy to test and easily tweakable. But the devil is in the details on this idea, so let's write some actual implementation code for this.
class Planner {
constructor() {
this.commands = [];
}
fetchData(id) {
this.commands.push({
action: 'Fetch Data',
context: {
id
},
handler: 'DATA_FETCHER'
});
return this;
}
...
branchWithPlan() {
const subPlanner = new Planner(this);
subPlanner.commands.push({
action: 'Begin sub plan',
context: {},
handler: 'SUB_PLAN_RUNNER'
});
return subPlanner;
}
endBranch() {
if (this.parentPlan) {
return this.parentPlan;
}
throw new Error("There is no parent plan to return control flow to");
}
end() {
return this.commands;
}
}
I've omitted most of the methods here 6 and kept two to illustrate what a
typical method looks like fetchData and then the slightly
less typical, but still very useful branchWithPlan. Initially,
I named this if and then had an else and end
method that did the same thing as endBranch7
but found that it make it read a bit less nicely than being explicit about these
flows of code into and out of branches. We also need a way to finalize the plan,
and so end() does that and just returns the commands for later.
With the full builder in place, and with terribly named handler and actions, the spread of the code looks like this:
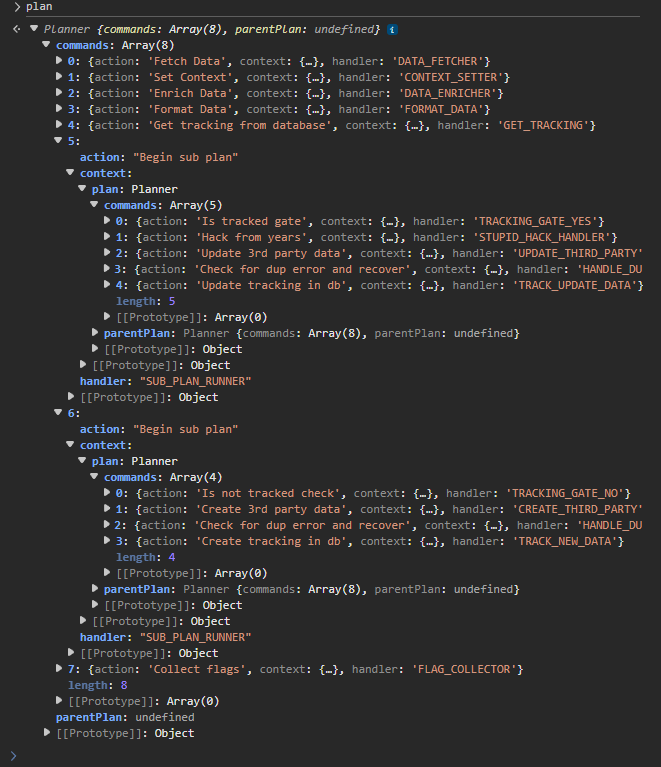
"We've basically built an AST", is my first thought looking at that image. And, when I think about ASTs I think about visitors and so we can begin to think about how our plan executor will actually work. If we have something iteratively walk across the plan, and ensure that it's able to understand if it should stop or not, then we can easily walk this little workflow and collect our results at the end of it all!
So this song and dance is going to require us to define what the handlers expose, and then show how the AST walker, err, I mean, plan executor, is going to interact with those methods to ensure we do the right thing. For the sake of my time here, I'm only going to define two handlers and leave it up to you, the reader, to do the human thing here and pattern match against what sort of stuff you'd slot into place instead, but my handlers will help illustrate the point:
const PlanSignal = {
CONTINUE_PLAN: 0,
ABORT_PLAN: 1
};
class EchoHandler {
handle(context) {
console.log('I will be running [', context.action, '] now');
context.signal = PlanSignal.CONTINUE_PLAN;
return context;
}
}
class GateHandler {
constructor(isOpen) {
this.isOpen = isOpen;
}
handle(context) {
console.log('Gate check! Gate ', this.isOpen ? 'is open' : 'is closed');
context.signal = this.isOpen ? PlanSignal.CONTINUE_PLAN : PlanSignal.ABORT_PLAN;
return context;
}
}
As you can see I've defined a simple constant (in Typescript you could declare this
as an enum if you hate yourself, or as const if you don't
8). And I've created
two handlers, one just lets you know that it's being ran, and the other
does some actual "logic" to stuff a signal into the bag of mutable state
known as context passed in and return from the method.
This is very reductive. But you can easily understand that you could do anything
that the previous code snippets hinted at here, calling out to
a 3rd party, fetching data or enhancing it, catching an error and changing the
signal, you name it. In "real" code that isn't hand waving samples like this, you'd
likely want to have this be async handle and whatnot, but since
this is just to illustrate the pattern, then you can fill in that keyword yourself
if your use case would require it. For now, I'll avoid this situation:
Moving along, in order for these handles to actually be called, we have to wire them up. If I was writing this in some code for work, I'd use some form of dependency injection, such as boxed-injector which would make it easy to add in any sort of service a handler might need with a couple of lines of code. But, since this is a self-contained example, we'll just make a map:
const injector = {
'DATA_FETCHER': new EchoHandler(),
'CONTEXT_SETTER': new EchoHandler(),
'DATA_ENRICHER': new EchoHandler(),
'FORMAT_DATA': new EchoHandler(),
'SUB_PLAN_RUNNER': new EchoHandler(),
'GET_TRACKING': new EchoHandler(),
'TRACKING_GATE_YES': new GateHandler(false),
'TRACKING_GATE_NO': new GateHandler(true),
'CREATE_THIRD_PARTY': new EchoHandler(),
'UPDATE_THIRD_PARTY': new EchoHandler(),
'HANDLE_DUPE_ERROR': new EchoHandler(),
'TRACK_NEW_DATA': new EchoHandler(),
'TRACK_UPDATE_DATA': new EchoHandler(),
'FLAG_COLLECTOR': new EchoHandler(),
'STUPID_HACK_HANDLER': new EchoHandler(),
};
If you don't actually need something to resolve dependencies and instantiate and inject things in the proper order for you, then a map is a good substitute! Or so I'll tell myself for the time being. I just really want this code example to be something that you can run in the browser with 0 dependency so that you all can fiddle with it as you'd like.
Anyway, with a mapping in place that matches the handler values in our
Command objects that the builder created. We now only need one more piece of the
puzzle. The executor!
class PlanExecutor {
execute(plan) {
return this.execute(plan, {});
}
executePlan(plan, currentContext) {
for (var i = 0; i < plan.length; i++) {
const { action, context, handler: handlerName } = plan[i];
const handler = injector[handlerName];
// Merge context from the previous result with anything the command
// included when it was created (such as the id: 123) from "Fetch data"
currentContext = Object.assign({}, currentContext, context, {action});
const nextContext = handler.handle(currentContext);
// The context going to the next handler will be the merged result!
currentContext = Object.assign({}, currentContext, nextContext);
// If the context up next has a subplan to execute, then start that now
if (currentContext.plan) {
// Contexts should remove a plan that executes in order to avoid
// accidental looping forever.
const subPlan = currentContext.plan;
delete currentContext.plan;
const subPlanResult = this.execute(subPlan.commands, currentContext);
currentContext = Object.assign({}, currentContext, subPlanResult);
}
if (currentContext.signal === PlanSignal.ABORT_PLAN) {
// Clear out the stop signal from the child plan,
// because we are returning control the parent plan
// which should continue as is.
currentContext.signal = PlanSignal.CONTINUE_PLAN;
return currentContext
}
}
return currentContext
}
}
And that's it. Now, putting aside that every functional programming in the room right now is screaming at their monitor "why did you make global mutatable state", this let's us actually do precisely what we wanted. If you run this code like
const plan = ... what we defined above ... const executor = new PlanExecutor(); executor.execute(plan);
Then the result of the console.log statements in the
handlers that we defined will all run in the order the plan asked
them to and you can see in your console:
I will be running [ Fetch Data ] now I will be running [ Set Context ] now I will be running [ Enrich Data ] now I will be running [ Format Data ] now I will be running [ Get tracking from database ] now I will be running [ Begin sub plan ] now Gate check! Gate is closed I will be running [ Begin sub plan ] now Gate check! Gate is open I will be running [ Create 3rd party data ] now I will be running [ Check for dup error and recover ] now I will be running [ Create tracking in db ] now I will be running [ Collect flags ] now
The first Gate check! was closed, because in the injector
setup we defined TRACKING_GATE_YES's handler as
new GateHandler(false) which meant that the signal
returned to the planner said to stop the sub plan. So you don't
see any output from the branch we created like
.branchWithPlan()
.isTrackedCheck()
.doHackFromYearsAgo()
.update3rdPartyData()
.recoverDuplicateError()
.updateTracking()
.endBranch()
If it had run, then you'd see messages and doing updates, instead you only see the output from the branch:
.branchWithPlan()
.isNotTrackedCheck() // Gate check! Gate is open
.create3rdPartyData() // I will be running [ Create 3rd party data ] now
.recoverDuplicateError() // I will be running [ Check for dup error and recover ] now
.createTracking() // I will be running [ Create tracking in db ] now
.endBranch()
And once the branch ends, we return to the original plan being executed and run the collect flags handler which came last.
Drawing comparisons to the middleware of express I mentioned before, and of the
chain of responsibility in general, our signaling system is a bit different from
calling next() from within the handler itself. Rather, we
let the decisions around where to let the code flow up to the plan executor instead.
Granted, there's nothing to stop a handler from doing this if it was an optional
sort of step:
handle(context) {
if (!this.somePreconditionToRunning(context)) {
return context;
}
...
}
I don't think this really violates any "pureness" of the CoR pattern. After all,
if you go and look at something like
Java's FileVisitor
then you'll see some suspiciously similar FileVisitResult
enums… While the plan executor is like the visitor in this case, we've
pulled out the methods that one would override in such a pattern and used the
command + handlers to detach them, so I think it's perfectly natural to use these
signals as control flow.
There's probably some of you who are also thinking "boy, that's a lot of boilerplate". We went from writing imperative code in order, to some sort of Enterprise level of indirection and abstraction. Is it really worth all that just to avoid having to scroll and keep context in your head?

An enterprise defense ↩
Let's talk more about these different strategies and their trade offs I've gone over. Because honestly, yes, I agree, there is quite a bit of boilerplate and indirection, and there are probably a chunk of systems programmers out there who aren't reading this article (because they hate anything that isn't C), but if they did they'd just be screaming about performance and getting more worked up than that one guy who thinks we should all be writing code as if it's 1993 and everyone operates at the same level as John Carmack. 9
This just isn't feasible in large companies, and the type of code that I've used to illustrate the problem is common when you've got a deadline, a large backlog, and an overcommitted team sprint after sprint after sprint. Even when one gets around to "scheduling" tech debt 10 whether or not you can justify changing the entirety of your business critical code in the send-o-tron 3000 to your boss, stakeholders, and any user reporting a bug in your "cleaner" code a couple weeks down the line is probably going to have its own challenges. There are definitely strategies on how to do this slowly but I digress. Let's get back to the point.
The question we're asking here is: are the layers of indirection worth it. And I would say that the answer is highly dependent on how often you change the code in the first place. If this is a part of something critical to the system its in, and you're getting bugs every week about something being wrong, then the code is shit and in flux anyway: change it now and be happier. If the code doesn't change often and is just an eyesore? Leave it alone for now and apply the incremental strategies mentioned in the last hyperlink to change it over time.
Another factor in this is how difficult the code is to change and how well-tested it is. Assuming you have tests against this monster method, how easy are they to add? How often do you have to change them when you change the internals of the code? If your answer is yes you have tests, but they break every time you change something, then that sounds like a leaky abstraction suite, and you should reassess how you do testing. 11
If the answer is that you don't have any tests because it's just "too hard" to write a test against something calling 5 external services and taking multiple branches that may or may not also call a database, then it sounds a lot like breaking things up into handlers would lower the barrier to test, and therefore make it more likely that you'd have this sort of critical code tested and covered. Covered code is harder to break most of the time, and if you're only testing one handler at a time, then you'll be more likely to easily hunt down bugs faster in most cases, especially since you can easily re-create some form of context object from a bug you saw and write a regression test for that particular use case.
All these pros I'm mentioning about breaking things out like this are things that relate not just to the individual programmer, but to the team. If a ticket comes in and says "hey, after we send that data to that service, we need to also track this and that from it, can you put that into the database?"; at the same time, if a ticket comes in and says "hey there's a bug in the send-o-tron, we're getting this weird value coming through, can you look into it?"; both of these tasks can likely be worked on at the same time by two different people if the problem is in two different handlers. In the case of the unmodified code? That's a merge conflict waiting to happen. In the case of the functional pipeline code? If the types change between pipes as a result of that, then you might have merge conflicts or churn as the two devs work against each other in the worst case, or no problems at all in the best case, this applies to the mutable context object too though, as it effectively takes a stand in for the immutable state passed through a functional pipeline and so has the same sort of problems if someone changes it. Given that each handler is a smaller amount of code to track though, the two conflicts will likely be a bit easier to resolve though.
My point is that clean and "DRY" code was never about making the computer happy. It's about making it easier for teams of programmers to not step on each others toes while working on separate tasks. The pattern has a lot of boilerplate, but the indirection puts layers not just between the code, but also between how much the hungover programmers working after a happy hour evening with each other might cause conflicts when merging their branches together. In which case, I think the answer becomes Yes, the boilerplate and extra layers are worth it.
In general, the term "Enterprise" is thrown around programming circles as a pejorative, and as something to be made fun of. But the reality is that code written in a large company, an enterprise, is written that way for a reason. And the reason is very often not because someone read Uncle Bob's clean code book and took all the wrong lessons from it, but because the patterns, boilerplate, and extra layers enable people to communicate about the code in better ways at scale.
For this specific use case, where you're using a dynamically typed language with no compiler to fact check your types and that you didn't just screw everything up? Object oriented styles like this go a long way. If we were using scala or typescript where the compiler could guide us a bit more, then the functional style pipeline would likely be my preference. If we were using C or rust? I'm not so sure because I don't have enough experience shipping things in those languages to weigh the trade offs, considering if you're writing something in those lower level languages you're probably concerned about not doing unneccesary virtual method hops and such, maybe you'd just write the original code and tell anyone who can't keep the context in their head that they have skill issues. 12
Anyway, I think I've made my point. The short of it is that whether or not you add patterns like this into your code base is very situationally dependent and sometimes worth it. I've had very good experiences with using the builder pattern in conjunction with commands like this. It makes it easy to answer questions like "hey does this thing include that thing?" and you can just look at those 10 or so lines in the fluent interface and nod your head most of the time. It's really easy to read, understand, and explain to new people on the team how a plug and play handler approach works like this.
I hope you all enjoyed these thoughts on patterns, and my implementation of a branching chain of responsibility through the combination of pipelines, commands, and builders maybe inspired you to think a bit more deeply about your control flow methods that might be growing monstrous. I doubt that this is a solution for every case, but it might be the solution for yours. Or who knows, maybe it will prompt some ideas in your head that are even better than this one. I'd love to know if so, it's fun to talk about the craft of programming and how to do it in ways that just feel good. I'll be at the usual places on the internet if you need me, best of luck with your monster methods!
