What are we building? ↩
I'm going to skip the overview of what dupdb is since I covered that a while ago. If you want to know the why of this program's meaning in life, than you can go ahead and read that first post, if you already know what dupdb is, then you know that I mainly use this to detect duplicate images. Whenever that little notification pops up:
I know that I need to open the browser's download menu and press delete on the file I just downloaded. This isn't that much of a pain in the butt. But sometimes, it is a bit annoying. Since, my OS doesn't have support to ask the user to do something, I'm left to manually deal with it myself. This is less ideal than I'd like, but I figure that this also gives us an opportunity to do something new today.
Well. New to my rust coding adventures at least. I've written a web server in C before, and it held up quite well in production the first year, and the last year we used it. But rather than writing a C server or doing some form of CGI again 1, we'll be using the fact that the Rust Book's final project is a web server to kickstart a simple to use management application for all this data we're storying into the dupdb. I thought about using the learnings from that one time we used raylib to make a gamepad display, but I think that my idea today will be simpler to implement. And, much like how dupdb started out without a database, I think I'd like to start simple before doing anything too complicated. Lest we lose our luster and motivation to hack away at this.
So, here's the high level diagram of what we're building, like I just said. We're starting simple:
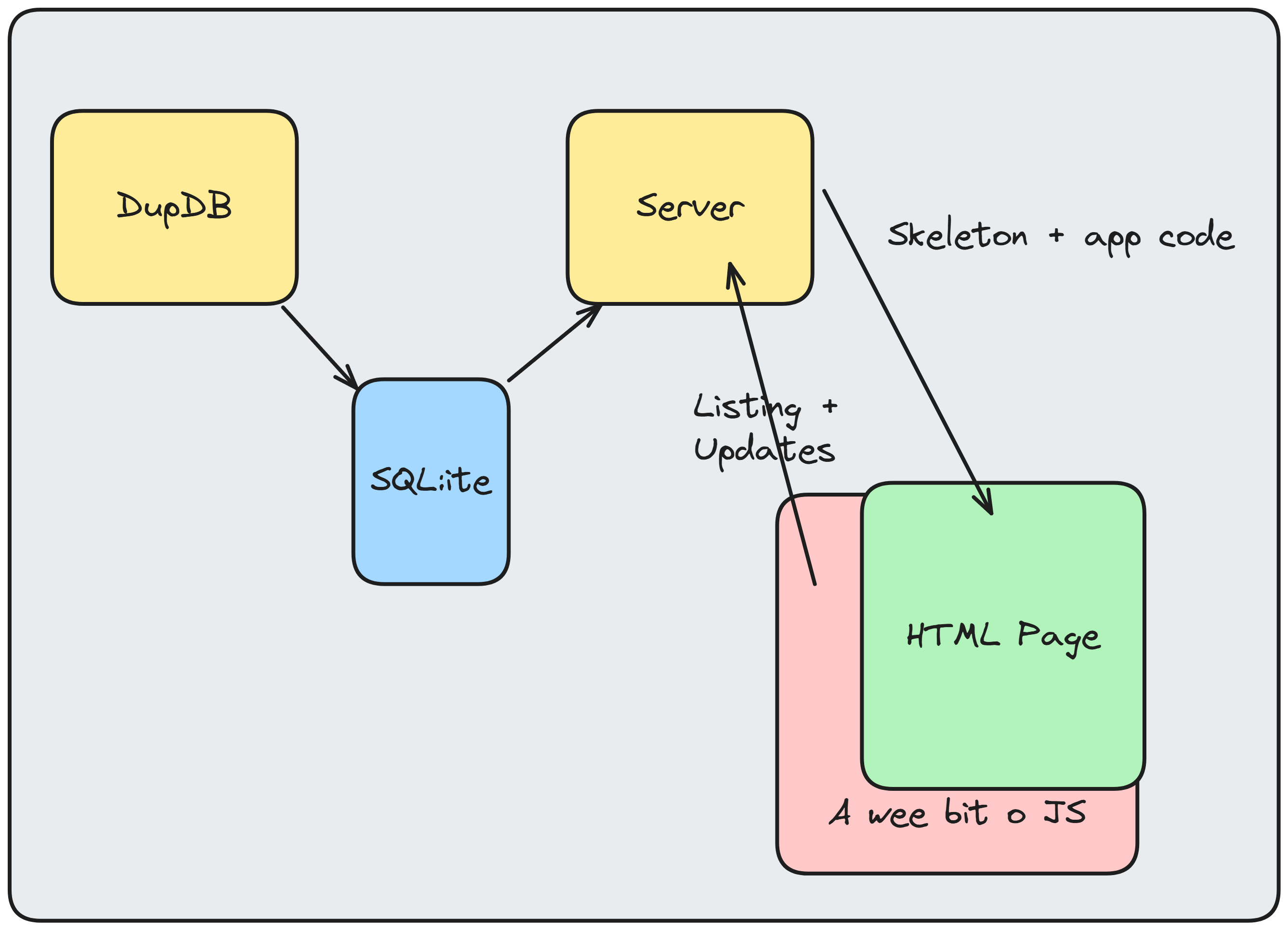
The only thing writing to the SQLite database is going to be the DupDB. The server will simply read from it. What about that "updates" you might ask? That's going to be file operations. Specifically, the rust server can be told to remove a file from the disk. This, in turn, will of course trigger DupDB to nix it, and then kapow, no more duplicate being reported. 2 I'm currently going back and forth on if the rust server should do server side rendering or if I should just load it all in via Javascript, but we'll get to that when we get there. For now. Let's take the first step to building what we don't already have working.
An incredibly small web server ↩
Luckily for us, making a web server for a simple application like what we're talking about is pretty damn easy. Especially because the final chapter of the rust book goes into detail on doing just that. We'll be using the code as a base, and I just finished reading it this past weekend! As per usual when reading through and doing a coding project, I didn't stay inside the lines, and instead tweaked things to match my desires as I went, let's chat about that.
There's two parts to the web server code that the book has you write, one's a fixed size thread pool, and the other is the actual http related code. The thread pool code is useful because it means that you can handle more than one request at a time! While I will very likely not be doing more than one at a time in my general use cases, browsers like to do things like
- Request favicons
- Send HEAD requests
- Send the actual request
- Retry a request because a server didn't response
And so it just makes sense to avoid writing something that's going to block on every single request. We also get to have some fun with mutexs this way. And what better way to feel like you're actually programming something than to be able to slay the dragon known as "concurrency" every now and then?
cargo new dupdb-frontend
I'm going to expand the repo with the dupdb code in it to have a new project. This will make it easier later to share things, but for now, we can focus on the porting of data. In my lib.rs file 3 as can start preparing for our thread pool implementation by importing what we need from the standard library:
use std::thread::{self, JoinHandle};
use std::sync::mpsc::{self, Sender, Receiver};
use std::sync::{Arc, Mutex};
To do threading, we use thread (surprise), and for the way we'll
push work out into separate threads we'll use the multiple-producer, single consumer
style channels since it makes things very easy to work with. As to what we'll be pushing
across said channels? Closures:
type Job = Box<dyn FnOnce() + Send + 'static>;
Basically, we'll have a function that we can send out from one channel over to another,
and then that channel can actually execute the closure in its little corner of the world.
Put another way, we'll be able to delay the execution of some code until there is a worker
thread ready to actually handle it. Each "job" only ever runs once, so FnOnce
makes sense, and we'll be sending it over a channel, so we need Send, and
lastly, as we'll see in a second, we need the Job to be static because it will last
forever (not really):
struct Worker {
id: usize,
thread: JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<Receiver<Job>>>) -> Self {
Worker {
id,
thread: thread::spawn(move || {
loop {
let message = receiver
.lock()
.expect("Failed to acquire lock, did another thread poison the state?")
.recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
},
Err(_) => {
println!("Worker {id} disconnected; shutting down");
break;
}
}
}
})
}
}
}
Putting aside my lack of desire to use a temporary variable for the thread, this
lovely tree-like swath of code is going to run a loop on Job requests popping out of
a channel Receiver until it runs into an error, at which point the thread will be
allowed to rest and get dropped. Spawning a thread returns a join handle, and we'll
use that later on in life during graceful shutdown of the system. Until that happens though,
the system doesn't know when the loop will end. This is why we needed a static lifetime
associated with our Job type. We know that it will get dropped after the thread
eats it up and loops, but the compiler doesn't.
Course, if we've got a worker, we need to have someone actually telling them what to work on! The management code that handles putting together a team of workers to do stuff is pretty simple, as far as fields go, it's got two!
pub struct FixedThreadPool {
workers: Vec<Worker>,
sender: Option<Sender<Job>>,
}
Unsurprisingly a list of workers, and then maybe slightly surprisingly, an option
of a the other side of the pipe that the workers are all hooked up to. The option is
purely here because of the rust compiler being a butthead. The drop implementation for
when the thread pool goes out of scope 4
requires an option so that we can use .take like so:
impl Drop for FixedThreadPool {
fn drop(&mut self) {
// Sender must be explicitly dropped in order to
// ensure that the worker threads actually stop looping.
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Shutting down worker {:?}", worker.id);
match worker.thread.join() {
Ok(_) => println!("Successfully shut down worker {:?}", worker.id),
Err(error) => {
eprint!("Could not shut down worker properly {:?} {:?}", worker.id, error);
}
}
}
}
}
What happens if it wasn't an option? Bad things. No, really, if you don't drop
the sender before you wait for the join handles you can't gracefully shut down.
Why? Because the workers are all looping for eternity until they receive an error
from calling recv. That error happens when the sender closes. When
does that happen? When the sender is dropped! What would trigger the sender
to get "naturally" dropped? If The FixedThreadPool was dropped! But hey,
we're writing that drop method right now! And we need the workers to get dropped before
the instance of the thread pool is dropped, but they won't stop running until their
sender is disconnected! And the sender isn't disconnected until it's dropped, and, and,
and…
You get the point? We have to take ownership away from the FixedThreadPool
and literally take the sender so that we can drop it. Then each worker will
recieve an Err when they next ask to receive a message, leading to their shut
down and for the loop inside of each to break. When that loop breaks, the threads can
finish joining, and then finally the thread pool can be shut down.
That's the struct and how to drop it, how to actually use the workers is done through a simple execute method that takes in a closure and passes it over to the channel to be picked up by a worker:
impl FixedThreadPool {
/// Size is the number of threads in the pool
/// The new function will panic if the size is 0
pub fn new(size: usize) -> Self {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
FixedThreadPool { workers, sender: Some(sender) }
}
pub fn execute<F>(&self, thunk: F)
where F: FnOnce() + Send + 'static,
{
let job = Box::new(thunk);
self.sender.as_ref()
.expect("Attempted to execute job after sender has been dropped")
.send(job).unwrap();
}
}
The only thing of real note here is the Arc::new(Mutex::new(...))
which is an atomically reference counted mutex. Funny enough, this was one of
the things I heard/saw in streams and from youtube folks 5
long before I ever tried rust myself. It's not that scary though, basically it's
just a big shared bulletin board and all the workers collectively use it to
to check if there's a job available, then they grab the first one they see and
erase it from the board so no one else can have it.
We're sort of building from the inside out here, but you can probably see how having a little pool of workers can be handy for something like a server that needs to take in a request, then be ready to handle another one whilst that first request might still be up in the air and processing. You'd think making a simple web server would be hard, but no, not really. Binding to a port and listening for messages is fairly trivial:
let listener = match TcpListener::bind("127.0.0.1:7878") {
Ok(listener) => listener,
Err(error) => panic!("Could not bind TcpListener {:?}", error),
};
let fixed_thread_pool = FixedThreadPool::new(CORES);
for event in listener.incoming() {
match event {
Ok(tcp_stream) => {
fixed_thread_pool.execute(|| {
handle_connection(tcp_stream)
});
},
Err(error) => eprint!("Could not handle event: {:?}", error),
};
}
Putting aside the lack of definition for the handle_connection,
this is seriously all you need to listen to a port and handle more than one
incoming request at once. This is also nearly verbatum what's built up in
the final project of the rust book. Let's improve it a little bit by making
the port and cores configurable from the command line and then go over the
connection handling.
I've used clap before for handling cli inputs, and I admit, it would be a smart choice. But I'm not feeling smart today, I'm feeling like I want to have fun and roll my own and have as few dependencies as possible for our little tool. So, let's just define a super simple pairwise parse with some reasonable defaults:
fn parse_args() -> (String, String, u16, usize) {
let mut sqlite_path = None;
let mut host = Some(String::from("127.0.0.1"));
let mut port = Some(6969);
let mut pool_size = Some(4);
let mut args = env::args();
args.next(); // Skip program name.
while let Some(argument) = args.next() {
match &argument[..] {
"-db" => sqlite_path = args.next(),
"-p" => port = args.next().map(
|string| string.parse().expect("Could not parse port as integer")
),
"-h" => host = args.next(),
"-s" => pool_size = args.next().map(
|string| string.parse().expect("Could not parse pool size as number")
),
unknown => eprintln!("Unknown flag {unknown}"),
};
}
(
sqlite_path.expect("Provide the database path for dupdb via '-db path'").to_string(),
host.expect("No host was set, provide -h 127.0.0.1 if unsure").to_string(),
port.expect("No port was set, please provide a number above 1000 to the -p flag"),
pool_size.expect("Provide how many worker threads will handle requests with -s 4")
)
}
Calling this from a main method and then printing out the tuple lets us do a super simple check on what happens if we're not providing the neccesary database path?
$ cargo run -- thread 'main' panicked at dupdb-frontend\src\main.rs:32:21: Please provide the sqlite database path for dupdb via '-db path'
And if we do?
$ cargo run -- -db foo.db -s 1 "foo.db" "127.0.0.1" 6969 1
Lovely. And passing everything with proper arguments?
$ cargo run -- -db foo.db -s 1 -h hostname -p 1356 "foo.db" "hostname" 1356 1
And if I pass a string for something that should be a number?
$ cargo run -- -db foo.db -s 1 -h hostname -p port
thread 'main' panicked at dupdb-frontend\src\main.rs:22:41:
Could not parse port as integer: ParseIntError { kind: InvalidDigit }
Beautiful. Couldn't ask for a better interface and fast failure. 6 With the ability to get configuration values, we can setup the server like I described before now:
fn main() {
let (sqlite_path, host, port, pool_size) = parse_args();
println!(
"starting dupe db with parameters {:?} {:?} {:?} {:?}",
sqlite_path, host, port, pool_size
);
let _pool = FixedThreadPool::new(pool_size);
let listener = match TcpListener::bind(format!("{host}:{port}")) {
Ok(listener) => listener,
Err(error) => panic!("Could not bind TcpListener {:?}", error),
};
let fixed_thread_pool = FixedThreadPool::new(pool_size);
for event in listener.incoming() {
match event {
Ok(tcp_stream) => {
fixed_thread_pool.execute(|| {
handle_connection(tcp_stream)
});
},
Err(error) => eprint!("Could not handle event: {:?}", error),
};
}
}
fn handle_connection(tcp_stream: TcpStream) {
println!("todo ~!{:?}", tcp_stream);
}
And running this via cargo run -- -db foo.db -s 1 -h localhost -p 7878
allows us to now navigate over to localhost:7878 and see a lovely error:
And some "logging" showing that yes, I'm not lying, it's really that simple:
Of course, a server isn't an HTTP server unless we handle HTTP, so let's setup the basics by looking at the path requested and returning something back for the time being. If you've never done this sort of thing before, you're about to learn why HTTP is used everywhere.
fn handle_connection(mut tcp_stream: TcpStream) {
let buf_reader = BufReader::new(&tcp_stream);
let http_request: Vec<_> = buf_reader
.lines() // (1)
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty()) // (2)
.collect();
let first_line = http_request.iter().next().map_or("GET / HTTP/1.1!", |s| s); // (3)
let status = 200;
let status_line = format!("HTTP/1.1 {status}");
let contents = first_line;
let length = contents.len();
let headers = format!("Content-Length: {length}");
let response = format!("{status_line}\r\n{headers}\r\n\r\n{contents}"); // (4)
match tcp_stream.write_all(response.as_bytes()) {
Ok(_) => return,
Err(error) => eprintln!("Failed to write response to output {:?}", error)
}
}
This is super simple and I've added little code callouts for us to walk through:
- HTTP is just text! formally described here the first line is always the "Request line" which states the method, protocol version, and uri. That's all we'll need to start
- We're cheating a bit here since we're basically reading up until there would be an HTTP body and then not reading it
- If there is no first line (which would be VERY strange) I'm just going to default to / for now.
-
The response is pretty similar
to the request except that we've got a "status line" and response body rather than a request line
and request body. They both share the fact that they use
\r\nto delineate the data though!
Now that the stream that the browser opens actually returns something and doesn't get the cold shoulder from our server, we can see that it's returning the request line to us as requested:
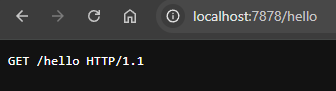
Would you look at that it's working! Let's all take a moment to thank the people who made HTTP request lines and headers simple ascii text… Ok, and now let's talk about the fact that we need to actually do something with that info. Let's setup some basic parsing! There are probably libraries for parsing HTTP requests 7, but just like we ignored the idea of using clap, I'm going to eschew these as well. Let's just parse the data ourselves:
fn parse_http_request_line(line: &str) -> (&str, &str) {
let method_and_uri: Vec<&str> =line
.split(" ") // https://datatracker.ietf.org/doc/html/rfc2616#autoid-38
.take(2)
.collect();
if method_and_uri.len() != 2 {
return ("???", "???");
}
let method = method_and_uri[0];
let uri = method_and_uri[1];
return (method, uri);
}
Yup. That's it. With that we can get back the method and uri, which are really all we currently care about. We're not worry about query parameters or url encoding or anything like that. Our needs are simple and so our parser is simple. Armed with our new method we can make a simple match to route requests:
fn handle_connection(tcp_stream: TcpStream) {
let buf_reader = BufReader::new(&tcp_stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
let first_line = http_request.iter().next().map_or("Nonsense!", |s| s);
match parse_http_request_line(first_line) {
("GET", "/shutdown") => panic!("TODO!"),
("GET", whatever) => send_200(whatever, tcp_stream),
("DELETE", whatever) => todo!("Not implemeted yet"),
(method, uri) => send_400(&format!("Invalid request {method} {uri}"), tcp_stream),
}
}
I've moved the code we had before out into send_200 and added in send_400
which is basically the same thing, but just sending out a 400 status code instead of a 200. 8 More importantly, I can now shut down the server!
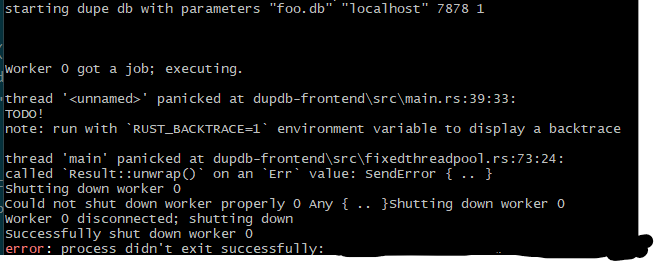
Kind of. I admit, the uh, "graceful", parse of graceful shutdown here isn't really happening. So, let's tweak the handle_connection method to return something to the caller to give it a signal on what to do:
#[derive(Debug, PartialEq)]
enum ProgramSignal {
STOP_PROGRAM,
CONTINUE_ON_MY_WAYWARD_SON,
}
fn handle_connection(tcp_stream: TcpStream) -> ProgramSignal {
...
match parse_http_request_line(first_line) {
("GET", "/shutdown") => return ProgramSignal::STOP_PROGRAM,
("GET", whatever) => send_200(whatever, tcp_stream),
("DELETE", whatever) => todo!("Not implemeted yet"),
(method, uri) => send_400(&format!("Invalid request {method} {uri}"), tcp_stream),
}
ProgramSignal::CONTINUE_ON_MY_WAYWARD_SON
}
... in the main method ....
for event in listener.incoming() {
match event {
Ok(tcp_stream) => {
fixed_thread_pool.execute(|| {
if handle_connection(tcp_stream) == ProgramSignal::STOP_PROGRAM {
// TODO: stop everything...
}
});
},
Err(error) => eprint!("Could not handle event: {:?}", error),
};
}
Ok, but how do we actually stop it? The only way to stop the TCP listener loop would be to close the socket, and the only way to close the socket is to drop the listener. So. We need to somehow tell the loop to stop... Sounds like the job for our trust friend...

The rust chapter on fearless concurrency covers this stuff pretty well, if we want to share some piece of state across multiple threads, we need an Atomic Reference Count to do that. If we want to make sure we don't clobber things when we're modifying stuff, we want a mutex. And so, our code gets a little boolean tossed in:
use std::sync::{Arc, Mutex};
... in the main method ...
let shutdown_flag = Arc::new(Mutex::new(false));
for event in listener.incoming() {
match event {
Ok(tcp_stream) => {
let flag = Arc::clone(&shutdown_flag);
fixed_thread_pool.execute(move || {
if handle_connection(tcp_stream) == ProgramSignal::StopProgram {
let mut flag = flag.lock().unwrap();
*flag = true;
}
});
},
Err(error) => eprint!("Could not handle event: {:?}", error),
};
if *shutdown_flag.lock().expect("poisoned mutex, yolo panic time") {
break;
}
}
Adding move to the closure gives the worker thread ownership over
the tcp_stream and most importantly the reference to the flag.
Then, if it happens to get a stop program signal, it can go ahead and let the main
event loop know by modifying the interior value of the mutex while it holds the lock.
I suppose using an expect here isn't the greatest of ideas. The bothersome
thing about having something like TcpListener around is that you really
should make sure it gets dropped properly. If we don't, then the port and host that
it's bound to can be held by the OS for a while, which is definitely annoying since then
we have to wait for whatever OS specific timeout exists to nix it.
Luckily for me, the rust documentation is pretty damn good. If we read the mutex examples in the standard library documentation, it shows us how you can recover from a poisoned lock:
use std::sync::{Arc, Mutex};
use std::thread;
let lock = Arc::new(Mutex::new(0_u32));
let lock2 = Arc::clone(&lock);
let _ = thread::spawn(move || -> () {
// This thread will acquire the mutex first, unwrapping the result of
// `lock` because the lock has not been poisoned.
let _guard = lock2.lock().unwrap();
// This panic while holding the lock (`_guard` is in scope) will poison
// the mutex.
panic!();
}).join();
// The lock is poisoned by this point, but the returned result can be
// pattern matched on to return the underlying guard on both branches.
let mut guard = match lock.lock() {
Ok(guard) => guard,
Err(poisoned) => poisoned.into_inner(),
};
*guard += 1;
That seems pretty straightforward... let's set that up in our code:
let shutdown_flag = match shutdown_flag.lock() {
Ok(guard) => guard,
Err(poisoned) => poisoned.into_inner(),
};
if *shutdown_flag {
break;
}
Then let's test it by making the workers who aren't trying to do the shutdown panic and explode:
let flag = Arc::clone(&shutdown_flag);
fixed_thread_pool.execute(move || {
if handle_connection(tcp_stream) == ProgramSignal::StopProgram {
let mut flag = flag.lock().unwrap();
*flag = true;
} else {
let mut flag = flag.lock().unwrap();
panic!("POISON THE LOCK MUA HA HA HA HA");
}
});
And then let's try it out by hitting some random / and then /shutdown after:
Worker 0 got a job; executing.
thread '<unnamed>' panicked at dupdb-frontend\src\main.rs:29:25:
POISON THE LOCK MUA HA HA HA HA
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
thread 'main' panicked at dupdb-frontend\src\fixedthreadpool.rs:73:24:
called `Result::unwrap()` on an `Err` value: SendError { .. }
Shutting down worker 0
Could not shut down worker properly 0 Any { .. }Shutting down worker 0
Worker 0 disconnected; shutting down
Successfully shut down worker 0
error: process didn't exit successfully:
`target\debug\dupdb-frontend.exe -db foo.db -s 1 -h localhost -p 7878` (exit code: 101)
Wups. I need to not call unwrap() from within the thread or else
the whole thing falls apart. Let's try that again after fixing those to behave
the same way, and also I need to fix... what's at line 73 of the threadpool code?
let job = Box::new(thunk);
self.sender.as_ref()
.expect("Attempted to execute job after sender has been dropped")
.send(job).unwrap();
Ah. Hm. Interesting that that's what's happening but sure I suppose that makes
sense. Moving these things around into match statements and eprintln
ing them and whatnot, then leads me over to… drumroll please…
starting dupe db with parameters "foo.db" "localhost" 7878 1 Worker 0 got a job; executing. thread '<unnamed>' panicked at dupdb-frontend\src\main.rs:41:25: POISON THE LOCK MUA HA HA HA HA note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace Could not send job sending on a closed channel clearin the poisin in the main event loop Could not send job sending on a closed channel Could not send job sending on a closed channel Could not send job sending on a closed channel Could not send job sending on a closed channel Could not send job sending on a closed channel Could not send job sending on a closed channel Could not send job sending on a closed channel Could not send job sending on a closed channel Could not send job sending on a closed channel ... it just says this whenever I send a new request in ...
It appears that panicking inside of the closure causes the channel to no longer be able to send data to that channel. I suppose this makes some degree of sense, since all workers share the same recieving end of the sender channel, even if they were being good about sharing it via the arc mutex. So, even if I can recover from a poisoned lock for the flag, can I recover from a poisoned channel? Looking through the docs doesn't really spark much hope. And so, I guess we'd have to re-construct the thread pool if just one of the workers is bad? That seems... not ideal? Or at the very least it seems to be a nuclear option to do this:
pub fn execute<F>(&mut self, thunk: F)
where F: FnOnce() + Send + 'static,
{
let job = Box::new(thunk);
let send_result = self.sender.as_ref()
.expect("Attempted to execute job after sender has been dropped")
.send(job);
if let Err(error) = send_result {
eprintln!("Could not send job {error}");
let mut soon_to_be_poisoned = FixedThreadPool::new(self.workers.capacity());
self.workers = std::mem::take(&mut soon_to_be_poisoned.workers);
self.sender = soon_to_be_poisoned.sender.take();
}
}
Locusta would be proud of us as we pass the poison from one person to the next. It does seems to work:
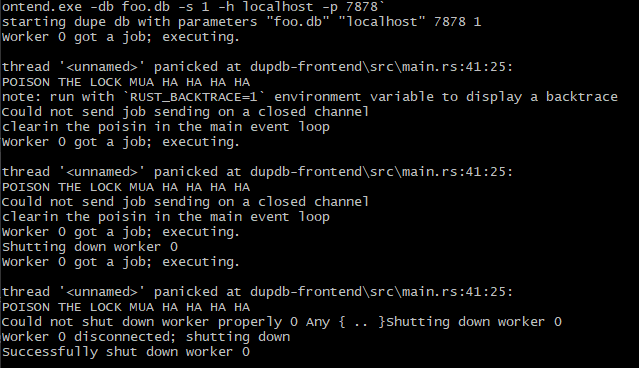
But I can't help but ask: Is this actually the right way to handle this sort of situation? It feels as if I should be able to re-use some of the non-poisoned workers for this? Actually, the only problem with the workers is that their channels are messed up, perhaps I simply need to replace those and wire things up?
Unfortunately, I don't think we can. Simply put, the two ideas that come to mind to me simply don't work. One won't compile, while one will, but then still fail. Since it's somewhat interesting let's chat about it a bit about each. 9 First, the one that simply doesn't work. Consider this idea:
struct Worker {
id: usize,
thread: JoinHandle<()>,
receiver: Option<Arc<Mutex<Receiver<Job>>>>
}
If the worker tracked the reciever, then it would be possible to .take()
and replace it! However, this breaks down very quickly when you consider how the
thread is setup.
thread: thread::spawn(move || {
loop {
let message = receiver
.lock().expect("Failed to acquire lock, did another thread poison the state?")
.recv();
...
}
})
The receiver in the thread is closure over the one passed into the new
method. If we included it on the worker, then there's another reference to it... but that's it.
There's no way to do worker.receiver = from within the loop for the thread.
Because to do that, the worker instance would have to move into the thread. "So what, move it" you
say? Remember the context we're in:
fn new(id: usize, receiver: Arc<Mutex<Receiver<Job>>>) -> Self{
We're supposed to return Self, which would be the worker we've just moved. Hm.
That certainly seems like a problem, doesn't it.
Ok, how about the second idea? Well, my second idea was: "Well, could a layer of indirection help? if I use a channel to send a new channel to ask for updates, would that work?" And so, I went ahead and double checked that Receiver implements Send and it does! So, forging blindly ahead without thinking it through, I tossed in some code:
... in worker ...
fn new(id: usize, receiver: Arc<Mutex<Receiver<Job>>>) -> Self {
let (reset_sender, reset_reciever) = mpsc::channel::<Arc<Mutex<Receiver<Job>>>>();
Worker {
id,
reset_channel_sender: reset_sender,
thread: thread::spawn(move || {
let mut current_receiver = receiver;
loop {
// check if we need to update the receiver.
if let Ok(new_receiver) = reset_reciever.try_recv() {
println!("New channel in town! {:?}", new_receiver);
current_receiver = new_receiver;
}
let message = current_receiver
.lock().expect("Failed to acquire lock, another thread poisoned the state?")
.recv();
...
}
})
}
}
... in fixed thread pool ...
pub fn execute<F>(&mut self, thunk: F)
where F: FnOnce() + Send + 'static,
{
let job = Box::new(thunk);
let send_result = self.sender.as_ref()
.expect("Attempted to execute job after sender has been dropped")
.send(job);
if let Err(error) = send_result {
eprintln!("Could not send job {error}");
self.reset_worker_channels();
}
}
fn reset_worker_channels(&mut self) {
// I _believe_ this should be thread safe since the the receiver is already closed
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let new_workers = self.workers.drain(0..).map(|worker: Worker| {
worker.reset_channel_sender.send(Arc::clone(&receiver))
.map_err(|e| eprintln!("cant send new channel {e}"));
worker
}).collect();
self.workers = new_workers;
self.sender = Some(sender);
}
This actually compiles. I was excited, so I went and tried it out, running up the server and sending in a request to trigger a normal route and the panic:
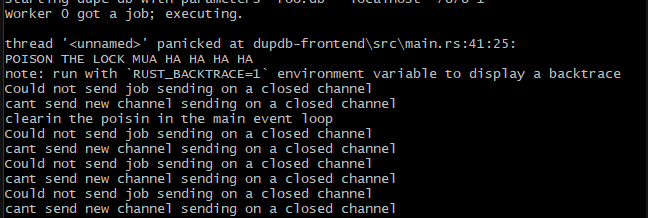
You may have already realized what my mistake was when I first proposed the idea. Unfortunately, I didn't think hard enough about it at first. But, upon seeing
cant send new channel sending on a closed channel

Right. Of course. If panicking in a thread causes the channel that already exists in it to get dropped and disconnected, then of course it's going to make the other channel I make get hit by the same behavior. That makes sense. So, I suppose we'll be sticking with the "fire and re-hire" strategy our worker manager is doing. I guess on the bright side, when the replacement happens, the existing workers and their threads should be dropped, right?

No… it doesn't because the only time the threads have their JoinHandles
used to call .join is within the Drop implementation for the
thread pool itself. And, since that doesn't get dropped by this, then
it's never called. Which means that as those handles go out of scope, the threads
are detached, running, and sad until they finally check their receiver, get an error
and cry a bit to break.
println!("Thread with id {id} has finished looping. Will be dropped.");
Adding the good ol println to the outside of the loop inside the thread. I can then watch as those lines never show up until after I trigger the shutdown:
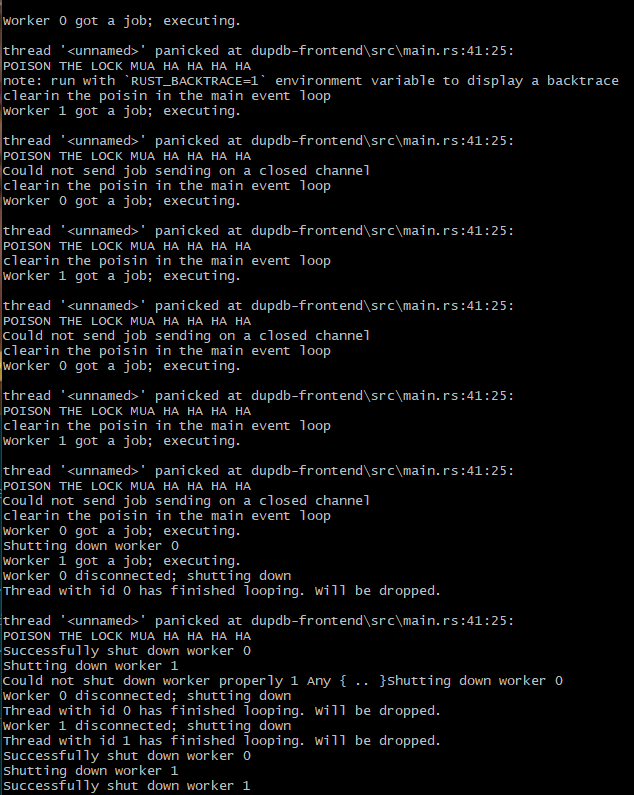
as you can see, I refreshed my browser a few times on the panic page and then finally shut it down at the end. Count how many times the println we just added shows up. Three. Even though I started this with 2 threads for the server and the recovery code setup 2 new threads, multiple times. That sounds a whole lot like a leak to me.
So what can we do about that? Well... We've sort of sleuthed our way to a 3rd solution already. Remember how I said the thread pool has to be dropped in order for join to be called? Why don't we just, do that:
pub struct FixedThreadPool {
workers: Vec<Worker>,
sender: Option<Sender<Job>>,
needs_reset: bool
}
pub fn execute<F>(&mut self, thunk: F)
where F: FnOnce() + Send + 'static,
{
let job = Box::new(thunk);
let send_result = self.sender.as_ref()
.expect("Attempted to execute job after sender has been dropped")
.send(job);
if let Err(error) = send_result {
eprintln!("Could not send job {error}");
self.needs_reset = true;
}
}
pub fn needs_reset(&self) -> bool {
self.needs_reset
}
... in main ...
for event in listener.incoming() {
if fixed_thread_pool.needs_reset() {
fixed_thread_pool = FixedThreadPool::new(pool_size);
}
match event {
Ok(tcp_stream) => {
...
We don't even need a mutex since this is all actually happening on the main thread and not shared with anyone. The change to the needs_reset field is done after we handle the send error returned by the channel. And, the proof is in the pudding 10 as well all know. So, what does the terminal look like when I log things out now?
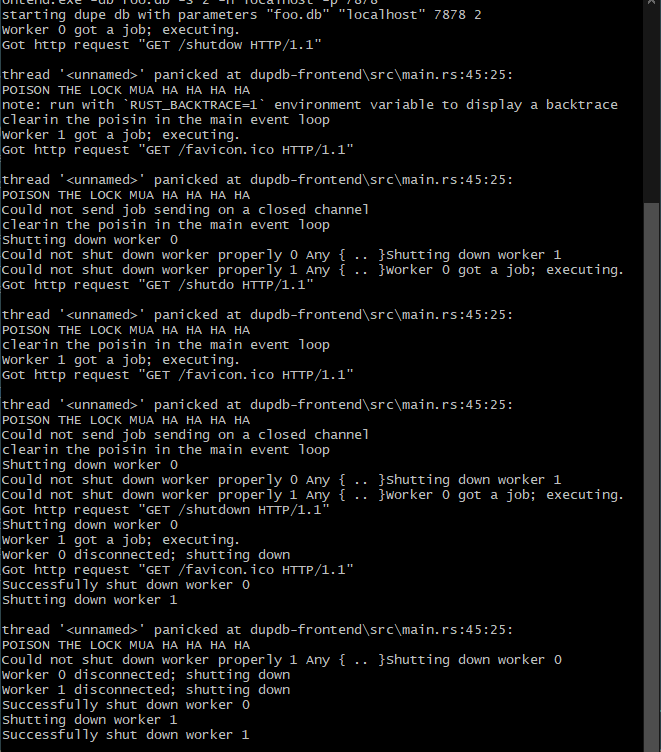
Putting aside the browsers inexplicably annoying requests for the favicon constantly, it appears that we do in fact have the Drop method being called now! There are errors it looks like, as this code is now being exercised:
impl Drop for FixedThreadPool {
fn drop(&mut self) {
// Sender must be explicitly dropped in order to
// ensure that the worker threads actually stop looping.
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Shutting down worker {:?}", worker.id);
match worker.thread.join() {
Ok(_) => println!("Successfully shut down worker {:?}", worker.id),
Err(error) => {
eprint!("Could not shut down worker properly {:?} {:?}", worker.id, error)
},
}
}
}
}
But we can see that this means that .join is being called! Which means
no more dangling resources! Awesome! We've taken a bit of a detour here with this,
so let's get back on track.
Sharing a project & database ↩
Since we have the ability to send out data to the browser, the next obvious step to me is not to spend time making a fancy looking layout or ui, but rather, getting the stuff in the database out in front of me. We could use JSON for this, but I'm somewhat inclined to just dump some text out with newlines as delimiters and deal with that on the frontend later. Besides, formatting data isn't the hard part here, it's figuring out how we're going to get data from a database out through the workers!
Regardless of how we structure this, I'll need a library to talk to SQLite. when I migrated the dupdb app to use that I used rusqlite. If I wanted to write up some more sql queries like I did before, I could go ahead and add in this to my Cargo.toml file:
rusqlite = { version = "0.37.0", features = ["bundled"] }
But… since the frontend and tool is in the same repository, I should be able to re-use the same SQL functions I made last time! So rather than rely on the rusqlite dependency directly, I can instead rely on the other code and I think we should always stay in sync with the version of sqlite used by the dupdb application!
[dependencies]
duplicate-file-monitor = { path = "../duplicate-file-monitor/" }
And then, let's just do a quick little build to make sure it's good and
warning: dupdb-frontend v0.1.0 (tools\dupdb-frontend) ignoring invalid dependency `duplicate-file-monitor` which is missing a lib target
Oh. Right. I don't have a lib.rs file in there. Well that's easy to fix! All I need
to do is pop up one directory in my workspace, and create a src/lib.rs file with
this in it:
pub mod dupdb; pub mod sql;
And if I pop back over to the frontend?
Finished `dev` profile [unoptimized + debuginfo] target(s) in 2.65s
Sweet! So now I've got access to the DupDb and the SQL methods! So, we can return to the original question we started this section off with. How do we get data from the database to the jobs dealing with them? A quick search on the internet for some guidelines finds me a few things to consider:
- Reddit user finding that writes can be very slow when done from multiple threads
- There's some discussions around if connection can/should be able to be sent across channels that is interesting, but isn't sparking any particular thoughts for me yet.
-
This github issue suggests having
a separate connection per thread, so long as SQLite was built with
SQLITE_OPEN_NOMUTEX. - I went down a rabbit hole following links in the discussion and found this code using an r2d2 connection pool and tokio's async runtime. Which, while not want I'm going to do here, is interesting to read through all the same. It's fun how they setup the queries that can be executed as enums! A nifty design choice I think.
All of our connections are going to be read only since there's 0 need for me to write anything. So, the concerns that are noted by the reddit user:
The thing about sqlite is that it's not very concurrent. For the most part, if one connection is in the middle of a long running write-transaction, and has overflowed it's in-memory buffer and started writing to the actual file on disk, no other transaction can be writing to the file.
Don't seem too relevant a concern for me. That said, sharing a mutex on a single connection
sounds a lot like we'll end up with a single point that everyone's going to be waiting around in the
code, and while we could setup another Arc<Mutex>, it seems a bit unneccesary. So,
let's add a single connection to each thread for now and then we'll move along. When I work with databases
and I know that I'll only ever need to do read queries, I like opening the connection in readonly mode.
I'm not sure if SQLite has any, but I know that when one does this for things like MySQl, it enables a
bit of optimization under the hood sometimes.
/// Panics if db cant be opened.
fn open_db_connection(sqlite_path: &str) -> Connection {
match Connection::open_with_flags(
sqlite_path,
OpenFlags::SQLITE_OPEN_READ_ONLY |
OpenFlags::SQLITE_OPEN_NO_MUTEX |
OpenFlags::SQLITE_OPEN_URI
) {
Err(error) => {
panic!("Cannot open database connection {error}");
},
Ok(conn) => conn
}
}
We'll verify that that database path is correct before we try
to bind the TCP port in our main function. Because this can panic, and we
want to avoid panicking after we've bound a port since if we
do then the Drop implementation won't be called for the
port bindings. So, we'll open and close a connection as a test:
fn main() {
let (sqlite_path, host, port, pool_size) = parse_args();
println!(
"starting dupe db with parameters {:?} {:?} {:?} {:?}",
sqlite_path, host, port, pool_size
);
// Verify connection first (this can panic) so that we don't
// have to worry about unbinding the TCP port in a moment
let db_connection = open_db_connection(&sqlite_path);
drop(db_connection);
// HTTP setup
let listener = match TcpListener::bind(format!("{host}:{port}")) {
Ok(listener) => listener,
Err(error) => panic!("Could not bind TcpListener {:?}", error),
};
...
Then, we can open a new connection as part of the job submitted to each worker.
let sqlite_path = sqlite_path.clone();
fixed_thread_pool.execute(move || {
let db_connection = open_db_connection(&sqlite_path);
if handle_connection(tcp_stream, db_connection) == ProgramSignal::StopProgram {
...
}
});
And then we just need to tweak the connection handler to take in the connection to make this all compile.
fn handle_connection(tcp_stream: TcpStream, readonly_connection: Connection) -> ProgramSignal
I'm not particularly happy with how everything feels mushed together like this, but for the time being I'll hold my nose so that we can accomplish our simple goal of getting some data out into the browser. Let's write some SQL to that effect:
const SELECT_ALL_DUPES: &str = "
SELECT hash, file_path
FROM dupdb_filehashes
WHERE hash IN (
SELECT hash
FROM dupdb_filehashes
GROUP BY hash
HAVING COUNT(DISTINCT file_path) > 1
)
ORDER BY hash
";
And then do a little bit of query parsing and running to make the usual list of tuples:
fn get_dups(conn: &Connection) -> Vec<(String, String)> {
let mut statement = conn.prepare_cached(SELECT_ALL_DUPES)
.expect("Could not fetch prepared select_dups query");
let rows = statement.query_map([], |row| {
Ok((
row.get::<usize, String>(0)
.expect("could not retrieve hash column 0 for select row"),
row.get::<usize, String>(1)
.expect("could not retrieve file_path column 1 for select row")
))
});
let mut dups = Vec::new();
match rows {
Err(binding_failure) => {
eprintln!("Unable to select rows from table: {}", binding_failure);
},
Ok(mapped_rows) => {
for result in mapped_rows {
let tuple = result
.expect("Impossible. Will fail in query_map before this ever occured");
dups.push(tuple);
}
}
}
dups
}
Our last step is simple. Use send_200 to return those tuples
in a string form for the browser:
match parse_http_request_line(first_line) {
("GET", "/duplicates") => {
let duplicate_tuples = get_dups(&readonly_connection);
let mut response_body = String::new();
for (hash,file_path) in duplicate_tuples {
response_body.push_str(&format!("{hash}\n{file_path}\n"));
}
send_200(&response_body, tcp_stream);
}
("GET", "/shutdown") => {
send_200("Shutting down...", tcp_stream);
return ProgramSignal::StopProgram
},
...
Assuming I haven't done anything too silly, let's fire up the application using one of the sqlite databases created by the dupdb's test suite and then open the browser at our new duplicates endpoint:
$ cargo run -- -db ../duplicate-file-monitor/.dupdb/dupdb-test.db -s 2 -h localhost -p 7878
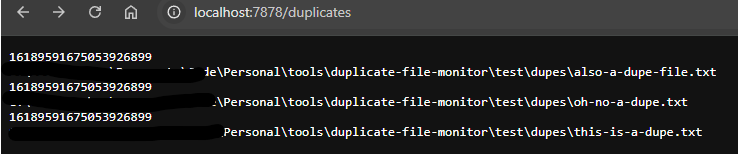
It works! Though, my first instinct is to collapse things a bit, and only emit the hash whenever it changes so we'd end up with something like
12345 full path full path 2 full path 3 23456778 full path full path ...
But thinking ahead a bit, I suppose we'll probably be doing some javascript like
response.text().split("\n").reduce(...)
So... Actually, let's make this even easier to work with. Let's put two
newlines inbetween each entry, that way we don't have to care too much about the
fact that we'd either need to do something like i % 2 === 0 to determine
if the line we're on is a hash or path, and we'll be able to just split by newlines
again.
response_body.push_str(&format!("{hash}\n{file_path}\n\n"));
Simple. And if I wanted to test this in the browser real quick, I could whip up a quick and dirty pipeline:
let map = fetch("/duplicates")
.then((response) => response.text())
.then((text) =>
text
.split("\n\n")
.map((lines) => lines.split("\n"))
.reduce((accum, lines) => {
if (!accum[lines[0]]) {
accum[lines[0]] = [];
}
accum[lines[0]].push(lines[1]);
return accum;
}, {})
);
console.log(await map);
Which shows me that I need to filter out empty strings, but the gist of it works as expected.
{
"": [undefined]
16189591675053926899: Array(3)
0: "\\test\\dupes\\also-a-dupe-file.txt"
1: "\\test\\dupes\\oh-no-a-dupe.txt"
2: "\\test\\dupes\\this-is-a-dupe.txt"
length: 3
}
Cool we've got the basic concept now! Database connected, files listed off, heck, I could use this to manually see all the duplicates when I initialize dupdb against a folder. But we're not done yet!
No REST for the wicked ↩
Normally, when I'm setting up real web servers I enjoy using
REST
as my guide. Roy Fielding's original dissertation is a fun read
if you're ever bored, and not terribly hard to get through I think.
But it is a bit too restrictive for what we're doing today,
and I don't really want to use JSON 11
as indicated by my use of .text() above.
That said, we can at the very least define the interface that our eventualy
frontend code will need to use. I think that we can keep this very very
minimal since our needs are pretty dang small. The proof of concept endpoint
/duplicates will work just fine. Given that this all runs locally,
it's very very cheap to dump that text information out and then stuff each
path into an <img src> and let things load.
Now, for the other option, we've got a choice. Do we use Javacript to send off a DELETE request for a path to the server? Or do we use an HTML form and POST it? The DELETE request is somewhat tempting since it has no body to parse, which means no extra work in our background for that, and instead we'd just match the entirety of the URL and then treat that as the file path to remove. Something like:
DELETE /C://my//path//here.jpg HTTP/1.1
We won't be able to remove a file named "shutdown" or "duplicates", but also, we're working will full paths, always, so that's not really a problem so long as we setup our match statement in the right precedence order. So this could work. OR, we could use a POST, in which case we'll need to handle something like this:
POST /remove HTTP/1.1 Host: localhost:7878 Connection: keep-alive Content-Length: 128 ... Content-Type: application/x-www-form-urlencoded ... Accept-Encoding: gzip, deflate, br, zstd Accept-Language: en-US,en;q=0.9 filepath=Code%5CPersonal%5Ctools%5Cduplicate-file-monitor%5Ctest%5Cdupes%5Cthis-is-a-dupe.txt
Either way, we're going to have to deal with a bit of url-decoding in order to get back the actual path. So, that'll be the main trickiness of this approach. On the bright side, the HTML side will be stupidly simple, since it will amount to basically having a form setup like this:
<form action="/remove" method="POST" target="_blank">
<input type="hidden" value="The file path here" name="filepath">
<button type="submit">Remove this dup</button>
</form>
Though, we can do it via Javascript if we want to, or just be clever about the response and maybe do a redirect back to a fragment in order to jump the user down to the place where they left off... we'll decide that later. For now, we need to be able to handle a POST request's contents! While the semantics of a DELETE request probably fit in better with our idea of what we're doing, a POST is easier to implement on a button since I remember the whole "method=DELETE" thing for a form being spotty in the past. 12 So, probably best for us to use what the browser supports.
So how do we url decode something?
1. Control names and values are escaped. Space characters are replaced by `+', and then reserved characters are escaped as described in RFC1738, section 2.2: Non-alphanumeric characters are replaced by `%HH', a percent sign and two hexadecimal digits representing the ASCII code of the character. Line breaks are represented as "CR LF" pairs (i.e., `%0D%0A').
2. The control names/values are listed in the order they appear in the document. The name is separated from the value by `=' and name/value pairs are separated from each other by `&'.
source
While small, the linked RFC lists off quite a few things that have to be dealt with in order to properly handle the edge cases of what can appear. It's non-trivial sounding to me. And so, while I'd love to take another detour, this one I think I'll leave to the community at large. Off to crates io we go! 13

I'll plan on using the form_urlencoded
library, which implements a parse function that can give me back a string. Of course,
in order to actually use it, we need the request body. So. How do we do that? There's a bit of a
problem with the code we stole from the rust book:
let buf_reader = BufReader::new(&tcp_stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
It stops when it reaches an empty line. That's all well and good for if we only wanted the headers and expected zero body. But... well. We need the body! And I can't re-use the buf reader, because if I do then
error[E0382]: use of moved value: `buf_reader`
--> dupdb-frontend\src\main.rs:121:49
|
91 | let buf_reader = BufReader::new(&tcp_stream);
| ---------- move occurs because `buf_reader` has type `BufReader<&TcpStream>`,
which does not implement the `Copy` trait
92 | let http_request = buf_reader
93 | .lines()
| ------- `buf_reader` moved due to this method call
...
121 | let http_post_body: Vec<u8> = match buf_reader
| ^^^^^^^^^^ value used here after move
So... Ok. how do we deal with this? The main issue is that if you do something like
bufReader.lines().collect() it will never go past that point
because the browser will never send the EOF out, so we have to be able to stop the
collection at some point. An HTTP request, if we refer to the spec, is this:
Request = Request-Line ; Section 5.1
*(( general-header ; Section 4.5
| request-header ; Section 5.3
| entity-header ) CRLF) ; Section 7.1
CRLF
[ message-body ] ; Section 4.3
And the spec is pretty clear that we can use the content length header to figure out how to read the body:
The presence of a message-body in a request is signaled by the inclusion of a Content-Length or Transfer-Encoding header field in the request's message-headers.
And so, I think we need to write a little helper to read out the headers for us, as well as potentially returning a message body if there is one. Let's whip that up!
fn get_http_from(tcp_stream: &TcpStream) -> (Vec<String>, Option<Vec<u8>>) {
let mut buf_reader = BufReader::new(tcp_stream);
let mut headers: Vec<String> = vec![];
loop {
let mut utf8_line = String::new();
match buf_reader.read_line(&mut utf8_line) {
Ok(0) => {
return (headers, None);
},
Ok(bytes_read) => {
if utf8_line.is_empty() || utf8_line == "\r\n" {
break;
}
headers.push(utf8_line);
},
Err(error) => {
// I suppose we have received non utf-8 in the header lines.
// Which is QUITE odd... let us abort with whatever we have.
eprintln!("Error while reading HTTP request: {error}");
return (headers, None);
}
}
}
let content_length = match headers
.iter()
.find(|line| line.starts_with("Content-Length"))
{
None => return (headers, None),
Some(line) => {
let raw_content_length = line.split(" ").skip(1).take(1).collect::<String>();
let content_length: usize = raw_content_length.trim().parse().unwrap();
content_length
}
};
let body_bytes: Vec<u8> = buf_reader
.bytes()
.take(content_length)
.map(|u8| u8.unwrap())
.collect();
(headers, Some(body_bytes))
}
This probably isn't the best implementation of things. I mean, I should
probably re-use the mutable string for buffer filling rather than allocating
a new one, also, I should probably maybe not use .bytes() because
I'm not entirely sure if it's going to read out a single byte at a time which
would probably be dreadfully slow... But you know what. The important thing
is if this works or not!
Replacing my current code with this helper, and then adding in a little debug route will tell us that:
fn handle_connection(
tcp_stream: TcpStream, readonly_connection: Connection
) -> ProgramSignal {
let (http_request_headers, maybe_http_body) = get_http_from(&tcp_stream);
let first_line = http_request_headers.iter().next().map_or("Nonsense!", |s| s);
match parse_http_request_line(first_line) {
...
("POST", "/remove") => {
if maybe_http_body.is_none() {
send_400("Invalid request, send an http body fool!", tcp_stream);
return ProgramSignal::ContinueOnMyWayWardSon;
}
let http_body = String::from_utf8_lossy(&maybe_http_body.unwrap()).to_string();
send_200(&format!("working on it {http_body}"), tcp_stream);
},
...
And submitting a form:
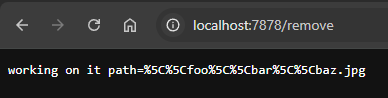
Woohoo! We've got some bytes, so now we can return to the whole "x-www-form-urlencoded" thing. Let's convert our vector of bytes into a vector of tuples that we can then use for what this route is actually supposed to do. First off, we need to add the crate in since I really don't want to deal with decoding this myself:
cargo add form_urlencoded
And then we can use it and println to show that yes, it really does work:
use form_urlencoded::parse;
...
("POST", "/remove") => {
if maybe_http_body.is_none() {
send_400("Invalid request, send an http body fool!", tcp_stream);
return ProgramSignal::ContinueOnMyWayWardSon;
}
let http_body = maybe_http_body.unwrap();
let path_tuple_to_remove = parse(&http_body).find(|(name, _)| {
name == "path"
});
if path_tuple_to_remove.is_none() {
send_400("Invalid request, no path found in form body", tcp_stream);
return ProgramSignal::ContinueOnMyWayWardSon;
}
let (_, www_form_encoded_value) = path_tuple_to_remove.unwrap();
send_200(&format!("working on it {www_form_encoded_value}"), tcp_stream);
}
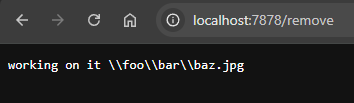
Houston, we have an identify function! Or well, anyway. We've got something that successfully decodes the form body. Let's now make it perform the actual task it's supposed to do:
if maybe_http_body.is_none() {
send_400("Invalid request, send an http body fool!", tcp_stream);
return ProgramSignal::ContinueOnMyWayWardSon;
}
let http_body = maybe_http_body.unwrap();
let path_tuple_to_remove = parse(&http_body).into_owned().find(|(name, _)| {
name == "path"
});
if path_tuple_to_remove.is_none() {
send_400("Invalid request, no path found in form body", tcp_stream);
return ProgramSignal::ContinueOnMyWayWardSon;
}
let (_, path_to_remove) = path_tuple_to_remove.unwrap();
if !fs::exists(&path_to_remove).unwrap_or(false) {
send_400(&format!("No file exists at path {path_to_remove}"), tcp_stream);
return ProgramSignal::ContinueOnMyWayWardSon;
}
let _ = fs::remove_file(&path_to_remove);
send_200(&format!("File at {path_to_remove} has been removed"), tcp_stream);
Congratulations me. I have created a way for anyone with http access to my computer to delete files off of it. What a beautiful security risk! The good news is that this does seem to work as expected. Submitting my test string returns a 400:
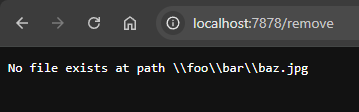
And if I Give it a random file I just made via touch test.txt?
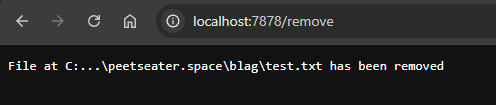
Awesome! So that's a listing endpoint and a delete endpoint done. Now we just need one more little thing and then we'll be ready to move on! This one will be quick, no parsing, no nonsense, just a simple file return:
("GET", whatever) => {
let file_reference = &whatever[1..];
if !fs::exists(&file_reference).unwrap_or(false) {
send_400("No file there m8", tcp_stream);
} else {
match fs::read_to_string(file_reference) {
Ok(bytes) => send_200(&bytes, tcp_stream),
Err(error) => send_400(&format!("{error}"), tcp_stream),
};
}
}
This one is slightly more security conscious. If not unintentionally.
It only lets people get back files that are located somewhere from the root of
the file. Though I suppose it would probably allow ../ now that
I think about it… But hey, whatever. Again, we can ignore these types
of concerns because this is something running on my local machine that's only
used by me! And it works quite well:
Alright. With that in place we can start writing some HTML!
What's an "electron"? ↩
I always enjoy taking potshots at electron apps for being bulky and wastes of memory. I think someone once tooted its horn because it "gives you all the same inspection and development tools as you have in the browser" or something. You know what else gives you those tools?

The browser
So, since we've got a tiny little web server, let's serve some tiny little HTML that does exactly what we need! We'll iterate on the interface a bit as we go, but my plan is to try to keep things light and simple. To start let's just put up a small skeleton of code:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Dup DB</title>
</head>
<body>
<header>
<h1>Duplicates on System</h1>
</header>
<main>
loading...
</main>
</body>
</html>
One of the nice things about working in pure HTML is that it's easy to develop exactly what you want. For example, since I primarily care about images, I want to be able to show them all neatly in a row. But, there's definitely a possibilty that a duplicate file might not be an image, in which case, I'd like to put in a placeholder. I could make a placeholder image. But HTML is XML by another name, and so we can just inline some SVGs instead!
<div>
<svg width="400" height="400">
<rect x="0" y="0"
width="400" height="400"
stroke="red" fill="#eeeeee"
stroke-width="5"
/>
<line x1="20" x2="380" y1="20" y2="380" stroke="red" stroke-width="5"/>
<line x1="20" x2="380" y1="380" y2="20" stroke="red" stroke-width="5"/>
</svg>
<p>
Filename here
</p>
<form method="POST" action="/remove" target="_blank">
<input type="hidden" name="path">
<button>Remove this File</button>
</form>
</div>
This simple graphic looks like this:

We can use this as a template and have Javascript generate a bunch of these
for us. Shouldn't be too hard to do. Nowadays if you use <template>
browsers mark them as display:none automatically and then you
can use them instead of manually creating the dom elements in Javascript which is
somewhat convenient. So, assuming the above is wrapped in an element with an id,
I can do the following:
const main = document.getElementsByTagName("main")[0];
const template = document.getElementById("duplicate-record");
function newDup(filepath) {
const div = template.content.cloneNode(true);
div.querySelector("p").textContent = filepath;
div.querySelector("input").value = filepath;
main.appendChild(div);
}
Then proceed to call it a few times to dump a bunch onto the page.
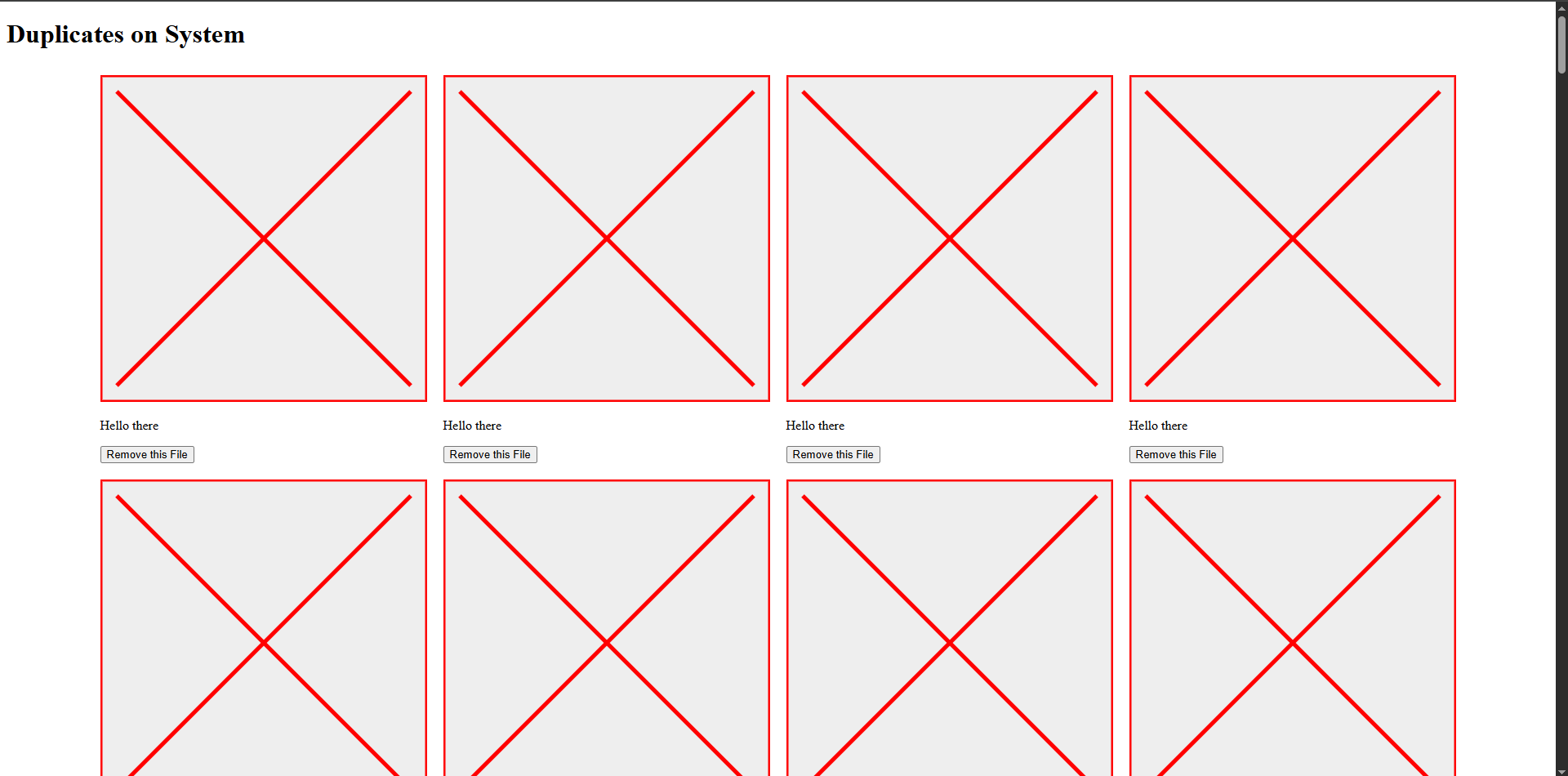
Granted. They're going vertical which isn't much fun. But we know how to fix that! A little while ago I had some fun with flexbox and learned how to use that and CSS grids. I think that I can probably do the same thing here. Before we load up the duplicates listing from the server, let's tweak and figure out what a bunch of these look like next to each other when we apply some CSS on top.
<style>
main {
display: flex;
flex-wrap: wrap;
justify-content: center;
}
main div {
padding: 10px;
}
</style>
This will wrap up all the divs in the main tag, and assuming that things don't get too wacky when I modify it to show an image instead of the SVG, we'll have something pretty nice looking:
So let's see what happens when I want to use an image instead of an svg... we'll need to give the img a max height and width, and probably wrap it in a container with the explicit dimensions so that it stays inside the box we define without bleeding out too much... I suppose the first thing I should try is just stuffing an image in and seeing what happens.

Ah. Right. We can't load file:// protocols from a browser's
window that's open in https://. But hey. We've already
got our cool path that loads whatever I ask it for... so what if we
use that? I'll need the urlencoding crate since percent
encoding for a form is different than percent encoding for a uri 14
but once we've got that in place, I can tweak my previously hyperspecifically
not using anything with spaces or special characters in it code to now deal
with that. And while we're at it, since we'll be serving up images
from this, let's ignore mime types and just pray the browser can deal with
octet streams in a way that makes sense:
("GET", whatever) => {
let file_reference = &whatever[1..];
let file_reference = match decode(file_reference) {
Ok(cow) => cow.into_owned(),
Err(error) => {
eprintln!("Can't read file reference properly: {error}");
String::new()
}
};
if !fs::exists(&file_reference).unwrap_or(false) {
send_400("No file there m8", tcp_stream);
} else {
if file_reference.ends_with(".html") {
match fs::read_to_string(file_reference) {
Ok(content) => {
send_200(&content, tcp_stream)
},
Err(error) => send_400(&format!("{error}"), tcp_stream),
};
} else {
match fs::read(file_reference) {
Ok(bytes) => {
send_200_bytes(&bytes, tcp_stream)
},
Err(error) => send_400(&format!("{error}"), tcp_stream),
};
}
}
}
...
fn send_200_bytes(content: &Vec<u8>, mut tcp_stream: TcpStream) {
let status = 200;
let status_line = format!("HTTP/1.1 {status} OK");
let length = content.len();
let headers = format!("Content-Length: {length}\r\nContent-type: application/octet-stream");
let response = format!("{status_line}\r\n{headers}\r\n\r\n");
match tcp_stream.write_all(response.as_bytes()) {
Ok(_) => {
let _ = tcp_stream.write_all(content);
},
Err(error) => {
eprintln!("Failed to write response to output {:?}", error);
}
}
}
Listen, I know I'm writing Spaghetti right now. We're "prototyping" right now. And prototyping is all about making this face:
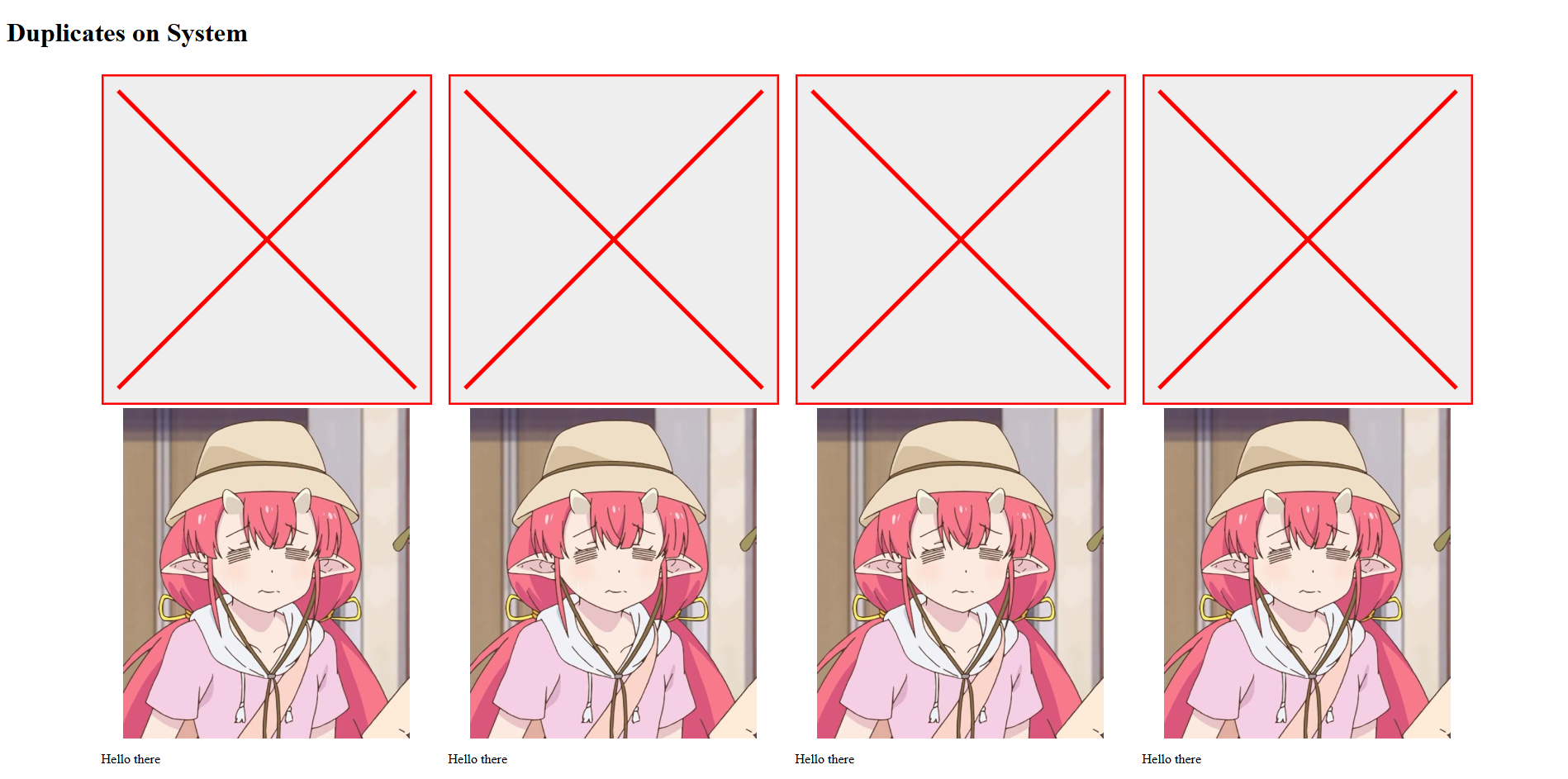
And thinking about how the fact that I can always just devote a blogpost to trying to write this up the "right" way later on after we prove out that the tool is worth putting more effort into! For now, the simple CSS is working as expected:
figure {
min-width: 400px;
min-height: 400px;
max-width: 400px;
max-height: 400px;
margin: 0;
display: flex;
justify-content: space-around;
}
figure img {
min-height: 400px;
max-width: 400px;
max-height: 400px;
}
And we just need to make sure that the SVG only appears if we fail to load the image src as an image. And also of course, if we load an image properly, then we should remove the svg! We can accomplish this using the onload and onerror handlers for the image element:
... in the template ...
<svg width="400" height="400">
<rect x="0" y="0" width="400" height="400" stroke="red" fill="#eeeeee" stroke-width="5" />
<line x1="20" x2="380" y1="20" y2="380" stroke="red" stroke-width="5"/>
<line x1="20" x2="380" y1="380" y2="20" stroke="red" stroke-width="5"/>
</svg>
<figure>
<img onerror="removeImage(this)" onload="onloadImage(this)">
</figure>
... in the JS ...
function removeImage(img) {
img.parentNode.remove();
}
function onloadImage(img) {
if (img.complete) {
img.parentNode.previousElementSibling.remove();
}
}
We're relying on the exact ordering of the elements. And while that's probably a bit funky to do in bigger projects. I think the fact that our template HTML is right there that it's highly unlikely we'll make a tweak in one place, and then forget to do it in the JS function that's right next to us. One way we could deal with this is by creating closures for the handlers and then doing the work in the new method:
function newDup(filepath) {
const div = template.content.cloneNode(true);
div.querySelector("p").textContent = filepath;
div.querySelector("input").value = filepath;
const svg = div.querySelector("svg");
const figure = div.querySelector("figure");
const img = div.querySelector("img")
img.src = filepath;
img.onload = () => {
if (img.complete) {
svg.remove();
}
}
img.onerror = () => {
figure.remove();
}
main.appendChild(div);
}
But... why make a bunch of extra anonymous functions if you don't have to? Anyway. We've got an SVG on a bad file, image on a good one, and now we just need to connect the dots here. Let's wire up our duplicates endpoint and load all those in instead of a placeholder image. So. I'll change this:
dummy_data = new Array(100);
dummy_data.fill('a file path on my system to the oni');
for (var i = 0; i < dummy_data.length; i++) {
newDup(dummy_data[i]);
}
to something somewhat similar to what I had mentioned before:
fetch('/duplicates')
.then((response) => response.text())
.then((text) => {
const entrie = text.split("\n\n");
const grouped_by_hash = entrie.reduce((accum, lines) => {
const [hash, path] = lines.split("\n");
if (!accum[hash]) {
accum[hash] = [];
}
accum[hash].push(path);
return accum
}, {});
for (const key in grouped_by_hash) {
if (!key) {
continue;
}
const files = grouped_by_hash[key];
for (var i = 0; i < files.length; i++) {
newDup(files[i]);
}
}
})
.then(() => {
main.firstChild.remove();
})
This, applied to the test database I had before (the one with the 3 dup txt files), results in the expected SVGs showing up:
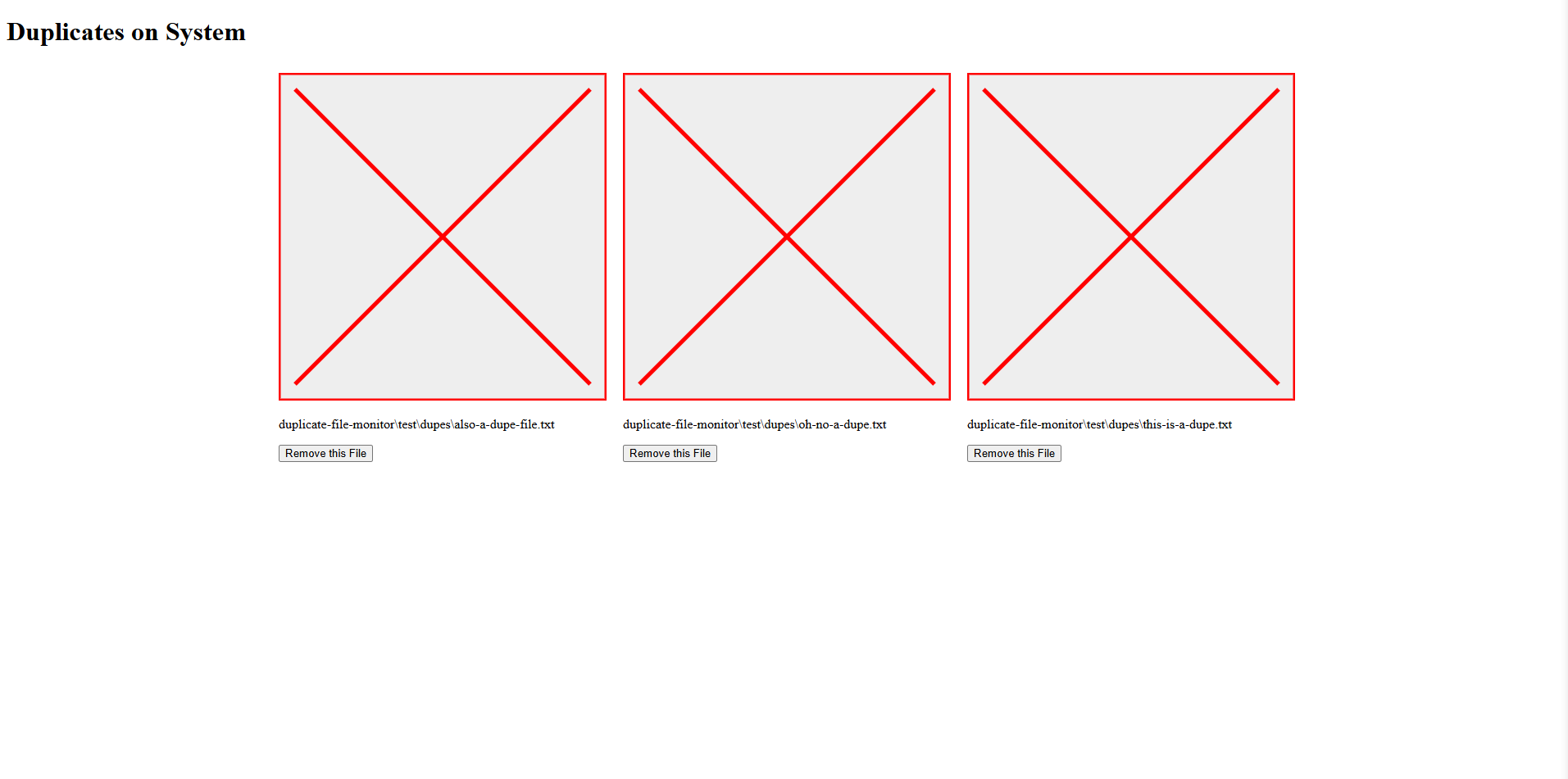
The button to move a duplicate works right now as well. Though we've still got
the target=_blank in the form, and it'd be a much smoother experience
to post up to the removal endpoint and then get redirected back over to the root.
This will result in the database results being loaded again which will result in
the removed file no longer appearing. 15
fn send_303_home(mut tcp_stream: TcpStream) {
let status = 303;
let status_line = format!("HTTP/1.1 {status} SEE OTHER");
let headers = format!("Location: /");
let response = format!("{status_line}\r\n{headers}\r\n\r\n");
match tcp_stream.write_all(response.as_bytes()) {
Ok(_) => return,
Err(error) => eprintln!("Failed to write response to output {:?}", error)
}
}
And with a minor tweak to the callsite to use this helper, I have a functioning interface to remove duplicates from my system that the dupdb application has detected.
Deployed and wrapped up ↩
So, what's left? Well, running
cargo run -- -db ~/.dupdb/dupdb.sqlite.db -s 4 -h localhost -p 7878
Whenever I want to open and us this seems a bit awkward. It seems like setting up a simple shell script to launch it whenever I feel the need to use it would be smart. There's not a lot to say about that beyond the fact that I'll need to use absolute paths for everything:
C:\abs\path\to\target\release\dupdb-frontend.exe -db C:\abs\path\to\.dupdb\dupdb.sqlite.db -s 4 -h localhost -p 7878 >> log.txt 2>&1
But hey, the system works. The code is… fine. I guess. I'm not terribly happy with it, yes it's only 300 or so lines of rust code and 100 lines of HTML/JS combined. But there's definitely a feeling that it could be improved. It's a lot of "lets get this done for now" type code, and it would probably be better to use a proper library or framework for dealing with all the nuance of HTTP. That said, the tiny miniscule server we have running takes up exactly how many resources you'd think it would:
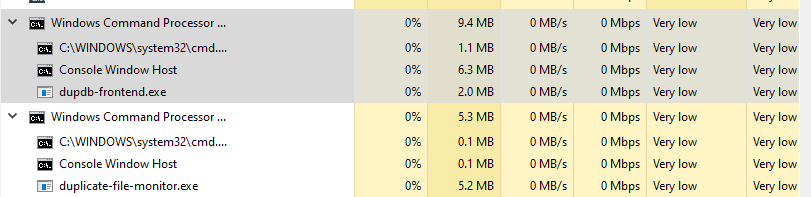
Which is to say: none at all. Considering I'd like to just have this constantly running in the background as I do all my usual activities like streaming, gaming, and what have you. That's ideal behavior.
I'll probably stare at the code for a while and decide if I want to either organize things into a lib file (rather than the amount of code sitting in the main) or investigate and look into proper HTTP server framework/libraries. It would probably be interesting to compare the resulting executable size and performance comparatively to what I have here now. For the record, the exe is 1.68MB and when I load or use the page I see it take up a while 1% of the CPU. So, that's probably going to be pretty tough to beat. But we'll see about it later, for now, I hope you enjoyed my strange detour into HTTP RFCs and plain HTML/JS for my little project.