Table of Contents
The why: My old site ↩
Before starting up a neocities account and claiming this domain as mine, I had a server that I paid for from a small company that I'd ssh into and do basic admin on. It took up a bit of time, but it also let me do a lot of nice things like run CGI chat servers for myself and friends, experiment with varnish and other fun things. The maintenance to keep things up to date with security CVEs and the ever present need to ip-ban half of China and Russia from spam bots scanning and pestering was enough of a headache that it started to lose it's luster after a while. At some point, when I had become too busy with work to keep up with that and blogging, I stopped updating the site as I was paying for something I never actually used anymore.
So I dropped it. My site was on github, I had the files if I wanted to push it up somewhere, but I just never had the time to do that. And so, judging from the timestamps of my blog posts, near the end of 2017 I basically stopped updating the website. I might have also started streaming at that time, based on the start of the Vod archives, so no doubt deciding to spend 2 to 4 hours of my nights, 5 days a week, also had an impact on my coding output. I still put out some writing, like my year long food journal on the impacts of primarily consuming soylent, and I maintained a small poetry website for a while, but for all intents and purposes, my contributions to the greater tech world ground to a halt as work consumed me and gaming consumed the other half of my life to provide relief.
Don't get me wrong, I still got an occasional email from someone who had stumbled across my website before and it had helped them solve a problem, and that sort of thing really lifted my spirits. But, it wasn't until 2021 when I found inspiration from Sebastion Lague's coding adventures did I turn my eyes back to blogging about programming. Granted, that series of posts lasted for all of November and then I was cold again until 2023 when I was once again bit by the bug, this time somewhat inspired by The Primagen of all people.
The funny thing about burnout, boreout, and all the other words we use to describe losing interest in a hobby we love, is that the embers never really go away. They just need to be rekindled with the right fuel. In 2021, it was the smiling voice of Sebastian Lague urging me to learn a bit of C# and have some fun in a guided way. And in 2023, it was the unbridled passion of The Primagen and LCOLONQ that stirred the feelings I had had back in middle school, high school, and in college that would inspire me to stay up late into the night, hacking away at some random bit of code just for the fun of it. Of course, what I'm about to talk about in this blog post isn't what most people would consider "sexy" coding. But, similar to how I approached my match three tutorial, I want to write blog posts for the intermediate programmer, not just for the beginner. And the idea of a site migration is not something that'll get a junior programmer excited.
So, let me tell you about why this site migration excited me, and maybe you'll start to what's so great about programming for the joy of it.
Our input data and output for this migration ↩
My old site has been rewritten from scratch a few times, but changed "frameworks" twice. The first time I made my site, I was into BNF grammars, and so I wrote my own flavor of markup called XeMark that was basically a highly condensed form of markdown with a couple odds and ends mixed in. After some time, I discovered HarpJS and found that I really liked it. My site was small at the time, and XeMark was essentially a subset of markdown so I was able to very quickly convert my posts over without much effort or fanfare.
Rolling your own mark up is fun. Inventing the wheel is great since you learn how the rubber hits the road. But it always has some degree of risk associated with it, and in this case, I didn't even realize it until this site migration you're reading about now. I'll tell you more later about this, but it's worth mentioning that having your own code bite you, years after you wrote it, is one of the many things that separates the wheat from the chaff. If you've never been bitten by some old hack or clever solution, then you're probably still a junior developer. That, or you just hate fun I suppose and never did anything worth mentioning after a couple years. Or maybe you've just had firmer guiding hands that I have? Anyway, my point is that XeMark is not markdown, and that'll come into play later on.
So, our input data for the migration is pretty simple:
- 40 cooking recipes
- 140 tech blog posts in markdown or xemark
- Two JSON metadata files
- One RSS XML feed file
The markdown files you probably expected given what I said above, but the JSON files are unique to HarpJS. Essentially, in any harp site, within any folder, you can define hidden files that won't be output in the final build of a site by prefixing them with underscores. Of these, some filenames are special such as the _layout.ejs and _data.json.
The layout file is exactly what it sounds like: a template file written in embedded javascript (ejs) which allowed my harp site to avoid repeating headers and other partials more than once. The data file is a bit more special. It looked like this:
{
"index" : {
"layout" : "index",
"title" : "Ethan's Tech Blog",
"description" : "A blog consisting of first-hand experiences with technology...",
"freq" : "daily"
},
"feed" : {
"title" : "My RSS Feed",
"layout" : false,
"freq" : "daily"
},
"git-crash-course": {
"title": "Git Crash Course",
"date": "2013-07-30",
"description" : "A short tutorial on some of the basics of using Git version control.",
"keywords" : "git,tutorial,crash course,Ethan",
"freq" : "monthly"
},
...
The metadata file for a directory in a harp site lets you pass values that's included automatically into the harp site's templates for use where the key at the top level matches the filename of your document. So, in this case, you can see how each post in the above JSON would set a title variable, a date, and other properties. All of which would be available for use in cases like a layout file like this:
<!DOCTYPE HTML>
<html>
<head>
<title>Ethan's Tech Blog | <%= title %></title>
Where the title of say, "Git Crash Course" would be included where you see <%= title %>.
Pretty simple, but pretty powerful. For most of my posts, the title in the metadata was often the same as
my first header on the page, though not always. No matter what though, I wanted to preserve this data since
some of the posts (mainly the XeMarks ones) didn't include a header in their content body, and so I needed to
load and process the EJS files in order to transfer that data over. Additionally, the keywords and dates were
needed to make sure that I ordered things properly, could tie related blog posts together for recommendations,
and even tweak the file names a little to match my new convention.
The last input I mentioned, the RSS feed, we'll get into later when we talk about Sublime Text, but it was only used to help make itself. But boy did it save me a lot of time, so it's worth an honorable mention.
As far as site migrations go, this is a tiny one. And I did consider looking through each one by one, then writing them out by hand and doing some editing, tweaking, and fixing up to weed out any low quality posts I didn't think needed to exist anymore. But, as you can tell by this posts existence, I opted out of that idea pretty quickly. I managed to get about 3 paragraphs into the first post before I said You know what? I'm going to automate this.
The reason? Well, we've talked about the input, let's talk about the output. If you view the source of this, or any of the other posts on this site you'll notice something. It's not minified. It's not squished up, in fact, it's got a lot of white space and if you look at the pre tags, you'll notice that it's got some funny commenting going out to trick your browser into not displaying a bunch of goofy whitespace before the code snippets. That's right, this website you're reading right now? It's downright artisanal if I say so myself. I wrote every line on this page by hand because when I moved to neocities I said to myself:
"You know what, Ethan? It'd be fun to just write plain HTML, no framework, just you and an editor."
And by jove that's what I did. Now, I can't quite say the same for all the posts I just migrated, but they're "written" in the exact same style as this one I'm writing now, with the same funny commenting trick for code snippets, and the same sort of spacing and handcrafted feel. So, we know our inputs and we know our outputs. So let's get to talking about the meaty part in the middle. All the code I wrote and the thought process behind it!
Parsing Markdown ↩
The first thing I did was look for a quick library to convert markdown to HTML. Considering that HarpJS was my compiler for the longest time, I thought about using it to do this part, but after digging through the source code to determine what package they're using1, I quickly realized it wouldn't work for me. If you look at the library's website, when you process markdown directly the output HTML is all very... squished. No problem I thought! We can pretty print it! And so, I turned to my usual tool to do this and quickly discovered a problem.
The "pretty" printer for Jsoup didn't match the style of my website's HTML! Worst, as I had discovered in the past it didn't produce my precious comment trick in the same way that I liked to do it. 2 And so, I was left with only a couple options:
- Look into JSoup's documentation to find out if you could customize the output as a postprocessing step
- Handle creating the HTML myself, which would mean parsing the markdown
JSoup does support output settings, but it wasn't really at the level of detail I needed, certainly not at the individual DOM node level, so that ruled out the first option. The 2nd option was attractive, but I hadn't had to do this before and so I set out on a quest to search the internet to see what libraries might be available to do such a thing.
And that, was when I spied a neat little blog post. The post was by Federico Ramirez, written in Ruby, and covered creating a parser for handling an extremely minor subset of markdown. I hadn't touched Ruby in years3 but anything you can do in one turing complete language, you can do in another. And so, remembering how much fun it was watching Tsoding create a JSON parser from scratch in Haskell in 111 lines, I decided that it'd be fun to read through the posts (it's a three part series) and then write the equivalent code with my currently preferred hobby language: Java!
And so, on October 5th of 2024, I committed the first few lines after reading the blog post and staring at the ruby code for a little bit. Well, maybe a little bit more than a bit. Using Java, we've got strong types, and Ruby? Not so much. So while the blog post had a Token class that it used for everything, I wanted to be a bit more concrete. Or, well, abstract to be precise:
import java.util.Arrays;
abstract public class AbstractToken {
protected String type;
protected String value;
public AbstractToken(String type, String value) {
this.type = type;
this.value = value;
}
public int length() {
return value == null ? 0 : value.length();
}
abstract public boolean isNull();
abstract public boolean isPresent();
@Override
public String toString() {
return "type:<%s>, value:<%s>".formatted(type, value);
}
public String getType() {
return type;
}
public String getValue() {
return value;
}
}
My base class for all tokens is pretty similar to the ruby one. We don't have the class level helpers to make a NullToken and End of File token attached to this class, those are implemented as children of our base:
public class NullToken extends AbstractToken {
public static final NullToken INSTANCE = new NullToken();
protected NullToken() {
super("NULL", "");
}
@Override
public boolean isNull() {
return true;
}
@Override
public boolean isPresent() {
return false;
}
}
The only noteworthy thing about my NullToken is that it's a singleton, because why would you have more than one?
I learned from Scala's None type, it's a nice thing to have a single value to be used in cases like this. Makes for an easy
quick check and also saves on memory. Which, potentially, is important since we're going to be processing an alright amount of text. Anyway,
you can see that the NullToken, shockingly, implements isNull and isPresent and return the
values you'd expect. The flipside of a null token is a real token. But that's a bad name, so let's take a nod from the fact that
we've got an abstract token, and name the opposing token class ConcreteToken:
public class ConcreteToken extends AbstractToken {
public ConcreteToken(String type, String value) {
super(type, value);
assert(type != null);
assert(value != null);
}
public boolean isNull() {
return false;
}
public boolean isPresent() {
return true;
}
}
We can then use this concrete token as a base itself. Giving special meaning to tokens that we only really need one of quickly and easily with a litle bit of inheritance.
public class EndOfFileToken extends ConcreteToken {
public static final EndOfFileToken INSTANCE = new EndOfFileToken();
protected EndOfFileToken() {
super("EOF", "");
}
}
and with those three defined, we've got the same basic building blocks as that blog post. Now, if you haven't yet, I would recommend you read, at least, the first section of that blog that explains what a compiler is. The visuals and explanations are probably better than what I'm about to say. Though mine will take you less time to read.
Basically, we're going to be making a parser combinator. What this means is that we'll take very very basic building blocks, and then create tokens out of each. Once we've created these tokens, we can then transform them into an abstract syntax tree (AST) which will represent our markdown document object model (DOM). With a DOM in hand, we can then traverse that structure to produce mark up of any shape or size we feel like.
When I said basic building blocks, I meant single characters. In order to process an input string of markdown, we'll create two Scanners that will do all of our dirty work for us. First up, the "Simple" scanner. I'll share the code first, then explain how this is all going to work together to make our life easier.
import java.util.HashMap;
public class SimpleScanner implements TokenScanner {
public HashMap<Character, String> tokenToType;
public SimpleScanner() {
tokenToType = new HashMap<>();
tokenToType.put('_', "UNDERSCORE");
tokenToType.put('*', "STAR");
tokenToType.put('\n', "NEWLINE");
}
@Override
public AbstractToken fromString(String input) {
if (input.isEmpty()) {
return NullToken.INSTANCE;
}
char character = input.charAt(0);
if (tokenToType.containsKey(character)) {
String tokenType = tokenToType.get(character);
return new ConcreteToken(tokenType, String.valueOf(character));
}
return NullToken.INSTANCE;
}
}
The gist of it is pretty simple, if the first character in the input we're given is one of the characters we've placed into the map, then we can construct a concrete token of that type, otherwise, we return the null node. This is useless on its own. But, if we combine the simple scanner with some more code like this:
public class TextScanner implements TokenScanner {
protected SimpleScanner simpleScanner;
public TextScanner() {
this.simpleScanner = new SimpleScanner();
}
@Override
public AbstractToken fromString(String input) {
if (input.isEmpty()) {
return NullToken.INSTANCE;
}
/* While a token isn't parseable by a simpleScanner, consume the input */
char[] characters = input.toCharArray();
StringBuilder sb = new StringBuilder(characters.length);
AbstractToken token = NullToken.INSTANCE;
for (int i = 0; i < characters.length && token.isNull(); i++) {
token = simpleScanner.fromString(String.valueOf(characters[i]));
if (token.isNull()) {
sb.append(characters[i]);
}
}
// If nothing was found, aka a simple scanner matched on the first input, then return null for text scanner
if (sb.isEmpty()) {
return NullToken.INSTANCE;
}
return new ConcreteToken("TEXT", sb.toString());
}
}
Then we can see how these two scanners can begin to form a meaningful whole for us. If the simple scanner saw a special character, we'll end up returning a token for that. If it didn't, then this text we're looking at isn't a special token of any kind and it's just text, so we can append it onto our growing list of other "meaningless" characters until we can't anymore. Then, we can call that whole chunk a TEXT token! You can probably see where this is going, since if we apply both of the scanners at the same time, then we'll always get some form of token back, and we can create a list of tokens that can then be used.
This is exactly what the Tokenizer class does!
import java.util.LinkedList;
import java.util.List;
public class Tokenizer {
List<TokenScanner> tokenScanners = List.of(
new SimpleScanner(),
new TextScanner()
);
public TokenList tokenize(String markdown) {
List<AbstractToken> tokens = tokensAsList(markdown);
return new TokenList(tokens);
}
protected List<AbstractToken> tokensAsList(String markdown) {
if (markdown == null || markdown.trim().isEmpty()) {
return List.of(EndOfFileToken.INSTANCE);
}
AbstractToken token = scanOneToken(markdown);
String remaining = markdown.substring(token.length());
List<AbstractToken> tokens = new LinkedList<AbstractToken>();
tokens.add(token);
tokens.addAll(tokensAsList(remaining));
return tokens;
}
protected AbstractToken scanOneToken(String markdown) {
for (TokenScanner scanner : tokenScanners) {
AbstractToken token = scanner.fromString(markdown);
if (token.isPresent()) {
return token;
}
}
throw new IllegalArgumentException("No scanner matched provided markdown: %s.\nAttempted Scanners: %s".formatted(
markdown,
tokenScanners.stream().map(tokenScanner -> tokenScanner.getClass().getSimpleName()).reduce("", "%s, %s"::formatted)
));
}
}
To start, I followed along with the way the ruby code did things. So we've got a recursive method that checks each of the potential scanners we've made against the input, so long as they return a token, we can append it to our list. Then recurse down to the next part. The astute among you might be thinking Isn't your stack going to be as large as the number of characters in your file?
Yes! Even though the JVM seemed to be doing some JIT work to do tail recursion to unwind the stack and didn't blow up on the posts I fed the code at this point. I still felt gross about it. So I did swap to an iterative approach later on, which I honestly feel is easier to read and understand:
List<AbstractToken> tokens = new LinkedList<>();
while (!markdown.isEmpty()) {
AbstractToken token = scanOneToken(markdown);
tokens.add(token);
markdown = markdown.substring(token.length());
}
tokens.add(EndOfFileToken.INSTANCE);
We don't need to be too clever, after all, the parsers themselves are already clever enough. I did start to apply some
Java-isms to the Ruby code that we were writing though. In the same vein as using a single NullToken, there's no reason
why we need to do this for every token: new ConcreteToken(...) I mean, the star token is always a star, so
why not use a singleton for it then?
It's easy to do, rather than everything being a concrete token, we can subclass it for the meaningful tokens. This will
help us later anyway since now our type system is speaking the same language as us without having to always say
.equals on another tokens type field. The ruby blog at this point had handled the cases for underscores,
stars, and newlines so I
added those types in:
/* Its basically the exact same for the newline and underscore class so I'm omitting them here */
public class StarToken extends ConcreteToken {
public static final String TYPE = "STAR";
public static final String VALUE = "*";
public StarToken() {
super(TYPE, VALUE);
}
}
And then to make life stay simple, added a Factory method to the ConcreteToken class to construct each
token so I could manage the list in one place.
public static ConcreteToken make(String type, String value) {
return switch (type) {
case TextToken.TYPE -> new TextToken(value);
case UnderscoreToken.TYPE -> new UnderscoreToken();
case StarToken.TYPE -> new StarToken();
case NewLineToken.TYPE -> new NewLineToken();
default -> new ConcreteToken(type, value);
};
}
The first part of the ruby blogpost basically ran out at testing the two scanners creating a token list, and while he showed an example and output, that wasn't enough for me since my plan was to build from this work out to other token types he didn't consider. So, I added some unit tests in so I could be sure that my code was working like his was.
class SimpleScannerTest {
@Test
public void empty_strings_tokenize_to_null_token() {
SimpleScanner scanner = new SimpleScanner();
AbstractToken token = scanner.fromString("");
assertEquals(NullToken.INSTANCE, token);
}
...
@Test
public void underscore_tokenize_to_underscore_type_token() {
SimpleScanner scanner = new SimpleScanner();
AbstractToken token = scanner.fromString("_italics_");
assertEquals( "UNDERSCORE", token.getType());
assertEquals( "_", token.getValue());
}
}
...
class TextScannerTest {
@Test
public void does_not_consume_tokens_simple_scanner_can_consume() {
AbstractToken token = textScanner.fromString("This text consumed, but *not this text*");
assertEquals("TEXT", token.getType());
assertEquals("This text consumed, but ", token.getValue());
}
@Test
public void returns_null_token_if_empty_input() {
AbstractToken token = textScanner.fromString("");
assertEquals(NullToken.INSTANCE, token);
}
...
}
And happily, these tests and the ones I've omitted all passed. I called it a night, and then the next day started in on the second blog post. This is where we start to see the power of the tokens. Since we have a list of meaningful objects, we can start to pattern match against the various runs of tokens that mean something to us in the context of markdown.
For example, Since we can convert a string like *bold* into the tokens STAR, TEXT, STAR
we can write code to look for that, consume those three tokens, and produce an object that states that the given
TEXT we found should be bold. Neat right? Of course, these objects we're talking about are what make up our markdown
document. So, unsurprisingly, this is where we start to get into defining our document object model (DOM)! Similar to the
tokens, we can have a base class, and then some abstract classes that extend them. These will be our abstract syntax
tree, or AST. Every single one of these nodes will have some type, and more importantly, they'll also keep track of how
many tokens were used to create them:
abstract public class AbstractMarkdownNode {
protected final String type;
protected final int consumed;
public AbstractMarkdownNode(String type, int consumed) {
this.type = type;
this.consumed = consumed;
}
public String getType() {
return type;
}
public int getConsumed() {
return consumed;
}
public boolean isPresent() {
return true;
}
public boolean isNull() {
return false;
}
}
As you can see, isNull and its friend isPresent is making another appearance, and just
as you'd expect, that means we also have a NullNode that represents nothing. If this is feeling really similar to
how we parsed the tokens, then good! It is very very similar. If you read the ruby blog post, you can see that
he explains a lot of the theory around grammars and that sort of thing, I'm not going to tell you that here, rather
let me show you what the Kleene star operation looks like in the Java code.
public abstract class TokenParser {
abstract public AbstractMarkdownNode match(TokenList tokenList);
/** Tries to match one parser, in order, and return the matching node. If none match, NullNode is returned
*/
public AbstractMarkdownNode matchFirst(TokenList tokens, TokenParser ...parsers) {
for (TokenParser tokenParser : parsers) {
AbstractMarkdownNode node = tokenParser.match(tokens);
if (node.isPresent()) {
return node;
}
}
return NullNode.INSTANCE;
}
/** Tries to match as many times as possible, returning all matched nodes. Kleene star */
public MatchedAndConsumed matchZeroOrMore(TokenList tokens, TokenParser tokenParser) {
int consumed = 0;
List<AbstractMarkdownNode> matched = new LinkedList<>();
AbstractMarkdownNode node;
while(true) {
node = tokenParser.match(tokens.offset(consumed));
if (node.isNull()) {
break;
}
matched.add(node);
consumed += node.getConsumed();
}
return new MatchedAndConsumed(matched, consumed);
}
}
The Kleene star is just a fancy way of saying that for as long as some parser continues to match,
that is, doesn't return a Null node, we'll repeatedly apply it to the input and collect each result
into a list. I didn't provide the code directly here, but our TokenList class is a simple
wrapper around a linked list of tokens that gives us a few useful primitives to work with such as
offsetting into the token list by a certain amount and returning a new list, or applying any given parser
to the head of itself and returning the result.
It was also at this point that we added in one of the most useful primitives to apply to our list's head.
The typesAheadAre method:
public boolean typesAheadAre(String ...requiredTypesInARow) {
if (this.isEmpty()) {
return false;
}
int i = 0;
for (String type : requiredTypesInARow) {
if (i > size() - 1) {
return false;
}
boolean matchesTypeAtIndex = get(i).getType().equals(type);
if (!matchesTypeAtIndex) {
return false;
}
i++;
}
if (i != requiredTypesInARow.length) {
return false;
}
return true;
}
Remember what I was saying about how STAR, TEXT, STAR meant we could do something?
This method makes it easy to express just that in code. By calling it like tokenList.typesAheadAre("STAR", "TEXT", "STAR")
you'd get back either true or false if that's the case. With that, we can start writing our parsing code that converts
a TokenList into an AST of markdown node instances. In the same way that the simple and text scanner were used
together to create something greater than the sum of their parts, the parsers work the exact same way. Here's the bold
parser code:
public class BoldParser extends TokenParser {
@Override
public AbstractMarkdownNode match(TokenList tokenList) {
if (tokenList.isEmpty()) {
return NullNode.INSTANCE;
}
if (tokenList.typesAheadAre(StarToken.TYPE, StarToken.TYPE, TextToken.TYPE, StarToken.TYPE, StarToken.TYPE)) {
return new BoldNode(tokenList.get(2).getValue(), 5);
}
if (tokenList.typesAheadAre(StarToken.TYPE, TextToken.TYPE, StarToken.TYPE)) {
return new BoldNode(tokenList.get(1).getValue(), 3);
}
return NullNode.INSTANCE;
}
}
While I haven't shown you the BoldNode class, you can see that it takes in the text data and the number of tokens
we've consumed to create it, just like I described before. If none of our possible patterns apply to the head of the token list
we return a NullNode and call it a day.
Just like the simple and text scanner, we need to repeatedly apply this parser and any others to the front of the list, then
we shift the entire list down by the amount of tokens we've consumed. Doing this is the responsibility of the, surprise, another
parser. Once we've made a parser for the simple bold, italics, and regular text data, we combine all three into something that
considers the token list in the context of a simple sentence. If we only parse one sentence at a time, then you can see that
the parser is as easy as using the helper we defined before, matchFirst, in whatever TokenParser
subclass we're working with:
public class SentenceParser extends TokenParser {
@Override
public AbstractMarkdownNode match(TokenList tokenList) {
return matchFirst(tokenList, new ItalicsParser(), new BoldParser(), new TextParser());
}
}
You've probably heard the phrase "it's turtles all the way down" before. This is parsers all the way up. From the simplest bold or text parser, then to sentences, paragraphs, body blocks, and all the way up until our root markdown node itself. We simply have to construct an application of whatever parsers we've made in a specific order and we'll get a rather complicated structure from uncomplicated parts that are straightforward to test individually.
Sentences are really just a list of other nodes in a group, and their AST node class reflects that:
public class ParagraphNode extends AbstractMarkdownNode {
public static final String TYPE = "PARAGRAPH";
private final List<AbstractMarkdownNode> sentences;
public ParagraphNode(List<AbstractMarkdownNode> sentences, int consumed) {
super(TYPE, consumed);
this.sentences = sentences;
}
public List<AbstractMarkdownNode> getSentences() {
return sentences;
}
}
Similar to that, a body is just a list of paragraphs (at least at this point in the blog post), and it looks exactly like what you'd expect too:
public class BodyNode extends AbstractMarkdownNode {
public static final String TYPE = "BODY";
private final List<AbstractMarkdownNode> paragraphs;
public BodyNode(List<AbstractMarkdownNode> paragraphs, int consumed) {
super(TYPE, consumed);
this.paragraphs = paragraphs;
}
public List<AbstractMarkdownNode> getParagraphs() {
return paragraphs;
}
}
Their parsers, since we've got such a simple idea of which tokens we have to process right now, are simple to follow too. And read basically how you might describe them to a friend in english. A paragraph is where you have at least one sentence in a row, they're separated by two newlines. Oh, and if you're at the end of the file then you don't need those newlines.
public class ParagraphParser extends TokenParser {
@Override
public AbstractMarkdownNode match(TokenList tokenList) {
MatchedAndConsumed matchedAndConsumed = matchAtLeastOne(tokenList, new SentenceParser());
if (matchedAndConsumed.getMatched().isEmpty()) {
return NullNode.INSTANCE;
}
TokenList afterSentences = tokenList.offset(matchedAndConsumed.getConsumed());
if (
afterSentences.typesAheadAre(NewLineToken.TYPE, NewLineToken.TYPE) ||
afterSentences.typesAheadAre(NewLineToken.TYPE, EndOfFileToken.TYPE)
) {
int consumed = matchedAndConsumed.getConsumed() + 2;
return new ParagraphNode(matchedAndConsumed.getMatched(), consumed);
}
if (afterSentences.typesAheadAre(EndOfFileToken.TYPE)) {
int consumed = matchedAndConsumed.getConsumed() + 1;
return new ParagraphNode(matchedAndConsumed.getMatched(), consumed);
}
return NullNode.INSTANCE;
}
}
The body parser is even simpler than this:
public class BodyParser extends TokenParser {
@Override
public AbstractMarkdownNode match(TokenList tokenList) {
// Consume initial whitesppace
MatchedAndConsumed m = matchZeroOrMore(tokenList, new NewLineParser());
TokenList prefixTrim = tokenList.offset(m.getConsumed());
MatchedAndConsumed paragraphs = matchZeroOrMore(prefixTrim, new ParagraphParser());
if (paragraphs.getMatched().isEmpty()) {
return NullNode.INSTANCE;
}
return new BodyNode(paragraphs.getMatched(), paragraphs.getConsumed() + m.getConsumed());
}
}
The matchAtLeastOne helper in the sentence parser is built on top of the matchZeroOrMore helper. Simply
do the latter and check if you got anything, if so then return it, otherwise return a null node. This is
feeling like our code is working hand in hand with our understanding! Pleasant right? One of the nice things
about all of this of course is that since we're not actually modifying the token list in any parser,
we can jump around in it with the offset helper and do quick look aheads to see if we've got an
end to the file after whatever we just parsed. Which makes it easy for a parser to add onto its list of consumed
tokens to try to make the next parser's job easier.
Though, this begs the question, if each parser isn't incrementing where we are in the list of tokens. What is?
Well, it's parsers all the way up, and so, our final parser is the MarkdownParser
public class MarkdownParser extends TokenParser {
public AbstractMarkdownNode parse(TokenList tokens) {
BodyParser bp = new BodyParser();
AbstractMarkdownNode body = bp.match(tokens);
int consumed = body.getConsumed();
TokenList remainingTokens = tokens.offset(consumed);
if (remainingTokens.typesAheadAre(EndOfFileToken.TYPE)) {
consumed++;
}
if (consumed != tokens.size()) {
throw new IllegalArgumentException(
"Syntax Error, consumed tokens did not match parsed tokens! Length mismatch %s vs %s\n".formatted(consumed, tokens.size()) +
"unconsumed tokens: %s".formatted(tokens.offset(consumed))
);
}
return body;
}
@Override
public AbstractMarkdownNode match(TokenList tokenList) {
return parse(tokenList);
}
}
Unlike the other parsers, this one vomits if we don't end up consuming the same number of tokens as the input was. This helps to signal to us that whatever we just gave it was invalid markdown. Following along with the blog post, I constructed various inputs and watched what worked and what didn't. While it certainly wasn't able to parse one of my blog posts yet, it was getting there. That said, before expanding the list of tokens, parsers, and what have you out further, I kept reading that ruby blog to the third part. DOM transformation!
The third and final post is really simple. So simple, that we can describe it in one sentence: Make a visitor for your AST and build HTML while you traverse. However, the devil is in the details. The Ruby code takes advantage of its dynamic nature, and the author continues to mirror the structure of the tokens, AST nodes, and visitors to create a separate visitor per node type:
But over in Java world, we've got types. And if I pass in an abstract node type, it's not going to let me just treat it as a body node with children or leaf node like italics willy nilly. Nope, since we've been following along pretty faithfully to this point, our node isn't a generic DOM node that always has children or siblings you might find in a super generic DOM, but rather very specific bits and pieces. This is both a blessing and a curse, but we can work around this by implementing double dispatch.
Which,
as you can see in the commit is a fancy way of saying each markdown node subclass will implement an
accept method, and each visitor will be passed into this before the given node passes itself
to the visitor to be handled by an overloaded method like so:
@Override
public void visit(BodyNode node) {
for (AbstractMarkdownNode bodyPart : node.getBodyParts()) {
indent();
bodyPart.accept(this);
}
}
This enables us to maintain the type safety of our code, and define how we want to handle each subtype
of node in a way that knows about the given fields for each. There's no generic AbstractMarkdownNode
visit method, so we never have to be concerned about casting between types or other such things, the compiler
deals with calling the right method at the right time for each subclass.
Of course, this has its own maintenance burden in that
we have to implement a new visit method each time we make a new node type, but this is acceptable. There are techniques
that can abstract some of this away, and the Java library itself uses those in its file traversal code if you ever want
to go digging into how the FileVisitor works. But since our site migration project isn't really meant to
be used to migrate any other site but ours, and the input types are limited, this is actually a really good way of letting
the compiler become our TODO list as we work.
Each time we parse a blog post and fail because we didn't consume all of the tokens, we can look at the post, determine which markdown features we're not supporting yet, and then begin to add those in. If they happen to result in a new type of node in our AST, then we'll add it in and the compiler will prompt us to fill out all the details for the double dispatch, carrying us along until we've gone from the topmost parse, to the down-est of turtles.
But I'm getting ahead of myself a litle bit. After walking through the 3 part ruby blog, we can handle a very very limited set of markdown. We can even produce a bit of HTML using a visitor that builds up a string over time:
public class HtmlStringVisitor extends BaseAstVisitor {
String indentString;
int indentLevel;
StringBuilder stringBuilder;
public HtmlStringVisitor() {
stringBuilder = new StringBuilder();
indentLevel = 0;
indentString = " ";
}
protected void createTagWithTextFromNodeValue(MarkdownNode node, String tag) {
stringBuilder.append("<%s>".formatted(tag));
stringBuilder.append(node.getValue());
stringBuilder.append("</%s>".formatted(tag));
}
@Override
public void visit(BoldNode node) {
createTagWithTextFromNodeValue(node, "strong");
}
private void indent() {
stringBuilder.append(getIndentString().repeat(indentLevel));
}
@Override
public void visit(ItalicsNode node) {
createTagWithTextFromNodeValue(node, "em");
}
@Override
public void visit(TextNode node) {
stringBuilder.append(node.getValue());
}
@Override
public void visit(BodyNode node) {
for (AbstractMarkdownNode bodyPart : node.getBodyParts()) {
indent();
bodyPart.accept(this);
}
}
@Override
public void visit(ParagraphNode node) {
stringBuilder.append("<p>\n");
indentLevel++;
indent();
for (AbstractMarkdownNode child : node.getSentences()) {
child.accept(this);
}
indentLevel--;
stringBuilder.append("\n</p>");
stringBuilder.append("\n");
}
private String getIndentString() {
return indentString;
}
public String getHTMLString() {
return stringBuilder.toString();
}
}
But this really doesn't match how complex our data actually is yet. And even worse, following the ruby post along exactly and trying out the examples given to us, I found that it doesn't seem like it works for all the same inputs even when I carefully walked through the code and felt like I had everything translated over correctly.
So, I wrote a bunch of unit tests, and hammered on it until my parser was able to translate the
string "__Foo__ and *text*.\n\nAnother para." into a form that became a DOM and
output HTML for me. I iterated a lot on my unit testing structure, starting off with a quick
and dirty form like this
public class TokenizeAndParseTests {
public void assertTypeAndValueOf(AbstractMarkdownNode node, Class<? extends MarkdownNode> expectedClass, String expectedValue) {
assertInstanceOf(expectedClass, node);
MarkdownNode realNode = expectedClass.cast(node);
assertEquals(expectedValue, realNode.getValue());
}
@Test
public void sample_text_from_ruby_blog_post() {
String sampleFromRubyBlog = "__Foo__ and *text*.\n\nAnother para.";
Tokenizer tokenizer = new Tokenizer();
TokenList tokens = tokenizer.tokenize(sampleFromRubyBlog);
MarkdownParser markdownParser = new MarkdownParser();
AbstractMarkdownNode dom = markdownParser.parse(tokens);
assertInstanceOf(BodyNode.class, dom);
BodyNode root = (BodyNode) dom;
AbstractMarkdownNode firstP = root.getBodyParts().get(0);
assertInstanceOf(ParagraphNode.class, firstP);
ParagraphNode p1 = (ParagraphNode) firstP;
assertTypeAndValueOf(p1.getSentences().get(0), ItalicsNode.class, "Foo");
assertTypeAndValueOf(p1.getSentences().get(1), TextNode.class, " and ");
assertTypeAndValueOf(p1.getSentences().get(2), BoldNode.class, "text");
AbstractMarkdownNode secondP = root.getBodyParts().get(1);
assertInstanceOf(ParagraphNode.class, secondP);
ParagraphNode p2 = (ParagraphNode) secondP;
assertTypeAndValueOf(p2.getSentences().get(0), TextNode.class, "Another para.");
}
}
Then, as I created more types of tokens, updated parsers, and iterated on them, moved to a provider style test where the test itself was generic, but the inputs and expectations varied instead:
@ParameterizedTest
@MethodSource("provideTestCases")
public void verify_sample_text_becomes_nodes(
int expectedBodyCounts,
int expectedListCounts,
int expectedParagraphCounts,
String sampleText,
List<NodeAndValue> nodesToValue
) {
TokenList tokens = tokenizer.tokenize(sampleText);
AbstractMarkdownNode dom = markdownParser.parse(tokens);
Flattener flattener = new Flattener();
dom.accept(flattener);
LinkedList<AbstractMarkdownNode> nodes = flattener.getNodes();
Iterator<NodeAndValue> iter = nodesToValue.iterator();
for (AbstractMarkdownNode node : nodes) {
NodeAndValue expected = iter.next();
assertTypeAndValueOf(node, expected.clazz, expected.value);
}
assertEquals(expectedBodyCounts, flattener.getBodyCounts());
assertEquals(expectedListCounts, flattener.getListCounts());
assertEquals(expectedParagraphCounts, flattener.getParagraphCounts());
}
private static Stream<Arguments> provideTestCases() {
return Stream.of(
Arguments.of(2, 0, 2, "__Foo__ and *text*.\n\nAnother para.",
List.of(
new NodeAndValue(ItalicsNode.class, "Foo"),
new NodeAndValue(TextNode.class, " and "),
new NodeAndValue(BoldNode.class, "text"),
new NodeAndValue(TextNode.class, "."),
new NodeAndValue(TextNode.class, "Another para.")
)
)
);
}
private record NodeAndValue(Class<? extends MarkdownNode> clazz, String value) {}
This made it nice and quick to add in a new test case for what I expected my code to do. Which is important in development. The faster you can tell that something is failing, the faster you can fix it. The sooner you discover a problem, the more likely you are to have just been adjusting the code that broke it. This type of thing is what Martin Fowler likes to hammer on in his various books. It's also what Michael Feathers tackles in his book on legacy code. And it's just damn good advice.
I could write an entire blog post about how useful testing and refactoring your code can be, but for now I'll simply state that defining the proper boundaries for where you want your tests to sit is vital. In the above case, I was confirming that when I parsed some string, I got back certain nodes in a certain order. I did this by flattenning the dom structure out. This was easy to do because the DOM accepts a visitor, and while I was using a visitor to make HTML like I showed up, I could also apply any visitors to them I wanted. Like this:
public class Flattener extends BaseAstVisitor {
private final LinkedList<AbstractMarkdownNode> nodes;
private int paragraphCounts;
...
public Flattener() {
this.paragraphCounts = 0;
...
this.nodes = new LinkedList<AbstractMarkdownNode>();
}
public LinkedList<AbstractMarkdownNode> getNodes() {
return nodes;
}
@Override
public void visit(ParagraphNode node) {
super.visit(node);
paragraphCounts++;
}
...
@Override
public void visit(TextNode node) {
this.nodes.add(node);
}
public int getBodyCounts() {
return bodyCounts;
}
}
Pretty simple, we walk the entire DOM, add each node to our list if it's a leaf, and keep track of how many nodes we saw that had children like the body, or sentence nodes. In the end, we've got a list of data that can be shown to the user, as well as an idea of if we pulled out the right number of blocks from the markdown. By doing this, we make it simple to add more test cases like this whenever I try a new post out and see it fail.
Arguments.of(1, 1, 0, " - but what about\n - with space at the start\n\n",
List.of(
NV(TextNode.class, " but what about"),
NV(TextNode.class, " with space at the start")
)
)
Whenever one of these high level tests revealed an issue, if it was some hidden gotcha or edge case I hadn't realized existed, I'd be able to drop down to whatever level the issue was at and add a more specific test. If the problem was in the parser? Then I could add in a test against that. If the problem was in the tokenizer? then I could drop a test or two into the tokenizer to handle the edges and then see the parsers in the layers above start to work as expected from my parameterized test cases passing.
This made for a really nice workflow, and for a week or so I'd spend 10 or so minutes a night just adding in a new token type, making a parser, and then tweaking tests and getting them to pass before moving along to trying out another blog post to see if there was a new bit of mark up I couldn't handle yet. I did the easy ones first. But soon enough started working on data that was an "exercise to the reader" from the ruby blog post. Such as lists.
A list in markdown is easy to write, it's a dash then some text, then a newline. So of course, we made a new token for that:
public class DashToken extends ConcreteToken {
private static final String VALUE = "-";
public static final String TYPE = "DASH";
public static final DashToken INSTANCE = new DashToken();
protected DashToken() {
super(TYPE, VALUE);
}
}
And lists are their own node within the markdown DOM, so we need to define a new class for them:
public abstract class ListNode extends AbstractMarkdownNode {
public static final String TYPE = "LIST";
private final List<AbstractMarkdownNode> items;
public ListNode(List<AbstractMarkdownNode> items, int consumed) {
super(TYPE, consumed);
this.items = items;
}
public List<AbstractMarkdownNode> getItems() {
return items;
}
abstract public boolean isOrdered();
}
The type is abstract because a list can be ordered, or unordered. And once both of those child types were defined, it was simple to make sure that the output HTML would send out the correct ol or ul based on that by updating the visitor.
@Override
public void visit(ListItemNode node) {
stringBuilder.append("<li>\n");
indentLevel++;
indent();
for (AbstractMarkdownNode listText : node.getRuns()) {
listText.accept(this);
}
indentLevel--;
stringBuilder.append("\n</li>\n");
}
@Override
public void visit(UnorderedListNode listNode) {
stringBuilder.append("<ul>\n");
indentLevel++;
indent();
for (AbstractMarkdownNode item : listNode.getItems()) {
item.accept(this);
}
indentLevel--;
stringBuilder.append("\n</ul>\n");
}
Remember how I said the compiler would guide us along on what we needed to implement? This was it in action, and it helped keep me focused and locked in while I worked. Handling a new node type meant asking myself where did it fit into the rest of the AST. A list isn't actually part of a paragraph, it's another block level element of the document, so it's up to the body to parse it. So, updating the body parser tests with something to verify we're doing it right:
@Test
public void parses_lists_as_body() {
AbstractMarkdownNode node = bodyParser.match(new TokenList(List.of(
DashToken.INSTANCE, new TextToken("1st list item no 1"), NewLineToken.INSTANCE,
DashToken.INSTANCE, new TextToken("1st list item no 2"), NewLineToken.INSTANCE,
DashToken.INSTANCE, new TextToken("1st list item no 3"), NewLineToken.INSTANCE,
NewLineToken.INSTANCE,
new TextToken("Paragraph"),
NewLineToken.INSTANCE, NewLineToken.INSTANCE,
DashToken.INSTANCE, new TextToken("2nd list 1 item"), NewLineToken.INSTANCE,
DashToken.INSTANCE, new TextToken("2nd list 2 item"), NewLineToken.INSTANCE,
DashToken.INSTANCE, new TextToken("2nd list 3 item"), NewLineToken.INSTANCE,
EndOfFileToken.INSTANCE
)));
assertNotEquals(NullNode.INSTANCE, node);
assertInstanceOf(BodyNode.class, node);
BodyNode bodyNode = (BodyNode) node;
AbstractMarkdownNode listOne = bodyNode.getBodyParts().get(0);
assertInstanceOf(ListNode.class, listOne);
assertEquals(3, bodyNode.getBodyParts().size());
AbstractMarkdownNode p = bodyNode.getBodyParts().get(1);
assertInstanceOf(ParagraphNode.class, p);
AbstractMarkdownNode listTwo = bodyNode.getBodyParts().get(2);
assertInstanceOf(ListNode.class, listTwo);
}
This is a simple test of course, technically it's not just text after a dash that counts as a valid list item, rather, it's any sentence after a dash followed by a newline. If we didn't treat it that way, then we could have formatting like bold, italics, or links within a list which would be a problem. Thinking about it that way, you can probably already see the implementation in your minds eye of my first implementation of it. Though, for whatever reason4, I decided that both a star and a dash were valid ways to start a list item:
public class ListItemParser extends TokenParser {
@Override
public AbstractMarkdownNode match(TokenList tokenList) {
boolean firstTokenIsDash = tokenList.typesAheadAre(DashToken.TYPE);
boolean firstTokenIsStar = tokenList.typesAheadAre(StarToken.TYPE);
if (!(firstTokenIsDash ^ firstTokenIsStar)) {
return NullNode.INSTANCE;
}
int consumed = 1;
MatchedAndConsumed potentialListItems = matchZeroOrMore(tokenList.offset(consumed), new SentenceParser());
if (potentialListItems.getMatched().isEmpty()) {
return NullNode.INSTANCE;
}
consumed += potentialListItems.getConsumed();
boolean eofOrNewline = tokenList.offset(consumed).typesAheadAre(EndOfFileToken.TYPE) || tokenList.offset(consumed).typesAheadAre(NewLineToken.TYPE);
if (!eofOrNewline) {
return NullNode.INSTANCE;
}
consumed += 1;
return new ListItemNode(potentialListItems.getMatched(), consumed, firstTokenIsDash);
}
}
With a way to parse a single list item, it's painfully obvious that an actual list node is just an application of the above parser multiple times in a row.
public class ListParser extends TokenParser {
@Override
public AbstractMarkdownNode match(TokenList tokenList) {
MatchedAndConsumed itemsMatched = matchAtLeastOne(tokenList, new ListItemParser());
if (itemsMatched.getMatched().isEmpty()) {
return NullNode.INSTANCE;
}
return new UnorderedListNode(itemsMatched.getMatched(), itemsMatched.getConsumed());
}
}
And as we mentioned before, this is a block level element that the body parser needs to be aware of. So, we've got to update the body parser to handle it. While the body parser previously only cared about applying the paragraph parser, now it needs to match one of many parsers over and over again. To make it flexible, we can track those in a list that we can add to in the future for other node types, and then loop until we find a match.
public class BodyParser extends TokenParser {
List<TokenParser> parsersToApply;
public BodyParser() {
parsersToApply = new LinkedList<TokenParser>();
parsersToApply.add(new ListParser());
parsersToApply.add(new ParagraphParser());
parsersToApply.add(new NewLineParser());
}
@Override
public AbstractMarkdownNode match(TokenList tokenList) {
// Consume initial whitespace
MatchedAndConsumed m = matchZeroOrMore(tokenList, new NewLineParser());
TokenList trimmed = tokenList.offset(m.getConsumed());
List<AbstractMarkdownNode> bodyParts = new LinkedList<>();
boolean consumeMore = true;
while (consumeMore) {
// Match first
AbstractMarkdownNode node = matchFirst(trimmed, parsersToApply.toArray(TokenParser[]::new));
if (node.isPresent()) {
bodyParts.add(node);
trimmed = trimmed.offset(node.getConsumed());
}
consumeMore = node.isPresent();
}
if (bodyParts.isEmpty()) {
return NullNode.INSTANCE;
}
int bodyPartConsumption = bodyParts.stream().mapToInt(AbstractMarkdownNode::getConsumed).sum();
return new BodyNode(bodyParts, bodyPartConsumption + m.getConsumed());
}
}
With the above framework in place, I was ready to handle the straightforward context free blocks such as code blocks, headers, and other such things. Things were going pretty well. Then, I hit an interesting case. Headers and the # symbol, as well as the fact that in some flavors of markdown, you can represent a header with text, a newline, then a bunch of dashes or equal signs.
This, unfortunately, adds context to the tokenization process or the parsing process, and makes things much much more difficult to handle. It started off simple enough, I had escaped a # with a \ character before it (remember xemark?) and decided to handle that. Doing so required rewrites to the text scanner since the best way to avoid adding a bunch of extra work to every parser was to make sure the tokens only became tokens when they had meaning.
public AbstractToken fromString(String input) {
if (input.isEmpty()) {
return NullToken.INSTANCE;
}
char[] characters = input.toCharArray();
StringBuilder sb = new StringBuilder(characters.length);
AbstractToken token = NullToken.INSTANCE;
boolean isEscaped = false;
for (int i = 0; i < characters.length; i++) {
token = simpleScanner.fromString(String.valueOf(characters[i]));
switch (token.getType()) {
case NullToken.TYPE -> sb.append(characters[i]);
case EscapeCharacterToken.TYPE -> {
if (isEscaped) { // if a \ was before this one, then escape the escape
sb.append(characters[i]);
isEscaped = false;
} else {
isEscaped = true;
}
}
default -> {
// If we are not escaping but have found a meaningful token, then cease
// processing the string we've been building and carry on so the next
// scanner could handle it
if (!isEscaped) {
if (sb.isEmpty()) {
return NullToken.INSTANCE;
}
return new TextToken(sb.toString());
}
// We are escaping a literal
sb.append(characters[i]);
}
}
}
if (sb.isEmpty()) {
return NullToken.INSTANCE;
}
return new TextToken(sb.toString());
}
This handled the case of \# properly, and # was treated as a separate TextToken.
Doing so kept my sentence parser simple, since now I didn't need to think about
heading tokens in the middle of a sentence anymore. Great! But, I only ever escaped
the pound sign in xemark files. In markdown files, it was handled properly by the
site's compiler. And so, I needed a way to take pound signs that weren't at the start
of a line and strip them of meaning. So, enter the collapseTokensWithoutMeaning
method of the Tokenizer's parsing method:
public TokenList tokenize(String markdown) {
List<AbstractToken> tokens = tokensAsList(markdown);
List<AbstractToken> processed = collapseTokensWithoutMeaning(tokens);
return new TokenList(processed);
}
private List<AbstractToken> collapseTokensWithoutMeaning(List<AbstractToken> tokens) {
for (int i = 1; i < tokens.size(); i++) {
AbstractToken token = tokens.get(i);
if (token.equals(PoundToken.INSTANCE)) {
AbstractToken previousToken = tokens.get(i - 1);
boolean poundTokenOrNewline = previousToken.equals(PoundToken.INSTANCE) || previousToken.equals(NewLineToken.INSTANCE);
if (!poundTokenOrNewline) {
tokens.set(i, new TextToken(PoundToken.VALUE));
}
}
}
return tokens;
}
This method would expand, adding new cases to weed out the special symbols in the middle of text
where they didn't actually mean anything. For example, in the case of a link, we need to treat the
symbols []: as special for link definitions, as well as []() for inline links. But if it was just a
random unmatched bracket? A colon somewhere in a sentence that wasn't part of a link? Or just some
parenthetical note. We didn't need to treat ( or ) as a ParenStartToken and ParenStopToken,
they could just be text.
private void collapseColonsThatAreNotPartOfDefinitions(List<AbstractToken> tokens, AbstractToken token, int i) {
if (token.isOneOfType(ColonToken.TYPE)) {
// Does this come after a ] ?
AbstractToken previous = tokens.get(i - 1);
boolean hasBracketBehind = previous.isOneOfType(BracketEndToken.TYPE);
if (!hasBracketBehind) {
// If not this is just a colon in text somewhere.
tokens.set(i, new TextToken(token.getValue()));
}
if (i + 1 < tokens.size() && tokens.get(i + 1).isOneOfType(TextToken.TYPE)) {
TextToken next = (TextToken) tokens.get(i + 1);
boolean whiteSpaceAfterColon = next.getValue().startsWith(" ");
if (whiteSpaceAfterColon) {
tokens.set(i, new TextToken(token.getValue()));
}
}
}
}
private void collapseMeaninglessBrackets(List<AbstractToken> tokens, AbstractToken token, int i) {
// If it's a bracket, then normalize the text in between.
// But leave the inline formatting such as bold, italics, underline alone
if (!token.isOneOfType(BracketStartToken.TYPE)) {
return;
}
// Scan forward to find the end bracket
int endingBracketIndex = i;
for (int j = i + 1; j < tokens.size(); j++) {
if (tokens.get(j).isOneOfType(BracketEndToken.TYPE)) {
endingBracketIndex = j;
break;
}
if (tokens.get(j).isOneOfType(BracketStartToken.TYPE)) {
// Wait, [ [ ? the first of these cannot be a link indicator.
// Unless I want to enable something like [link[]] but I don't think I have that case
break;
}
}
if (endingBracketIndex != i) {
// If we found the ending bracket then normalize the text between
removeNonFormatRelatedTokensFromRange(i, endingBracketIndex, tokens);
} else {
// Otherwise, this bracket is just a random stand alone bracket doing nothing.
tokens.set(i, new TextToken(token.getValue()));
}
}
private void removeNonFormatRelatedTokensFromRange(int startExclusive, int endingExclusive, List<AbstractToken> tokens) {
for (int i = startExclusive + 1; i < endingExclusive; i++) {
AbstractToken tokenToCheck = tokens.get(i);
if (tokenToCheck.isOneOfType(
AngleStartToken.TYPE,
AngleStopToken.TYPE,
ColonToken.TYPE,
DashToken.TYPE,
EqualsToken.TYPE,
NewLineToken.TYPE,
ParenStartToken.TYPE,
ParenStopToken.TYPE
)) {
tokens.set(i, new TextToken(tokenToCheck.getValue()));
}
}
}
As you can see, things get complicated when we start processing and tweaking the meaning of tokens. We end up having to do little things like converting anything that's part of a link into text, or scanning back and forth across the token list and modifying it in place to change things around. As I mentioned before, the unit tests helped a lot with this, but it was still a lot.
This was all fine, until I had finished with the above code, and then started thinking about how
I'd handle the links themselves. Markdown, unfortunately, is not context free. And links
were one of the first types of data since I've started that really required something greater than
them to exist. Some way to track the link definitions, global state to draw on for when its time
to convert [this](text) into <a href="text">this</a>
I thought about it for while. Then I happened to remember that I had started the project on the 5th of October, and it was now the 22nd. The goal was to migrate my website over, and while I love getting distracted with a side quest, I took a step back for a moment and decided that I had had a lot of fun reinventing the wheel. I understood how the rubber hit the road. But now, I wanted to actually get on with it so that I could focus on other hobby projects. While thinking about the context problem, I had gone ahead and looked at open source libraries that did markdown parsing for ideas.
It probably shouldn't surprise you, that after seeing their AST, Visitor structure, and parsing of commonmark, I decided that it was time to sit down with a library that handled all the weird wacky inputs, context and all, and focus in on getting the output right.
Converting markdown into HTML ↩
Unsurprisingly, having an understanding of the principles behind the library made it really simple to pick it up and start going. Commonmark does pretty much the same thing, in principle, as the code I was writing from scratch before, it just does it in a way that actually handles all the very weird edge cases and contexts of markdown. While it'd be really neat to figure all that out myself, time is limited, I want to do some other projects, and this, frankly, was taking up too much of that hobby time.
So let's talk about the basics. Converting a file to the markdown AST of commonmark is easy and simple with commonmark, reading the README will give you all you need, but to reiterate:
String inputMarkdownFile = ... Parser parser = Parser.builder().build(); Node document = parser.parseReader(new FileReader(inputMarkdownFile));
In my case, we don't need to use anything besides the defaults for the parser. I don't use github flavored markdown in my posts, and it was pretty barebones. Like I said before, XeMark was a close enough subset of markdown that I didn't even need to do anything special there. So, great! Now that I have a node, then what? Well, if I wasn't customizing the output, we'd write this:
HtmlRenderer renderer = HtmlRenderer.builder().build(); String html = renderer.render(document); Files.writeString(outputFile, html, StandardOpenOption.TRUNCATE_EXISTING, StandardOpenOption.CREATE);
But, this will just give you unindented, squished together markdown, great for sending across the wire, bad for my eyesight and editing. So, instead, I do this:
Optional<FileMeta> maybeFileMeta = getMetaForPost(inputMarkdownFile);
adjustHeaderSizes(document);
addHeaderIfNeeded(document, fileMeta);
updateLinks(document);
FileMeta fileMeta = maybeFileMeta.orElse(determineMetaFromFile(document));
HtmlRenderer renderer = HtmlRenderer.builder().nodeRendererFactory(
new HtmlNodeRendererFactory() {
@Override
public NodeRenderer create(HtmlNodeRendererContext htmlNodeRendererContext) {
return new BlagTemplate(fileMeta, htmlNodeRendererContext);
}
}
).build();
This won't mean too much yet, but basically, we're passing along our own NodeRenderer
that's going to handle transforming the various markdown nodes into HTML. Well then, doesn't this
sound really similar to how I described our HtmlStringVisitor in the previous section?
Yup. Because it's the exact same thing!
public class BlagTemplate extends Template implements Visitor {
FileMeta fileMeta;
public BlagTemplate(FileMeta title, HtmlNodeRendererContext context) {
super(context);
this.fileMeta = title;
this.context = context;
}
@Override
public Set<Class<? extends Node>> getNodeTypes() {
return Set.of(
Heading.class,
Code.class,
...
HardLineBreak.class
);
}
@Override
public void visit(IndentedCodeBlock indentedCodeBlock) {
addIndent();
html.tag("pre");
html.line();
increaseIndent();
String[] lines = indentedCodeBlock.getLiteral().split("\n");
for (String line : lines) {
addCommentIndent();
html.text(line);
html.line();
}
decreaseIndent();
html.line();
addCommentIndent();
html.tag("/pre");
html.line();
}
...
}
I'm omitting a lot here, but the commonmark class we're implementing is the Visitor which
provides us with the requirements to implement the various overloads of the Node types. Additionally,
we need to implement and provide NodeRenderer#getNodeTypes and provide back the list of subtypes we want
to handle. This is actually pretty clever because it enables us to create a visitor that only looks at
specific types and then passes off the renderering of anything it doesn't care about back to the library.
This is particularly useful because I used a lot of different visitors to do some tweaks and processing of
the data before giving it over to the "real" renderer. For example, in the code snippet I showed where we
focused in on the change to the renderer builder. I also had the methods adjustHeaderSizes,
addHeaderIfNeeded, and updateLinks. Let me show you those!
private static void adjustHeaderSizes(Node document) {
LargestHeaderVisitor headerVisitor = new LargestHeaderVisitor();
document.accept(headerVisitor);
document.accept(new NormalizeHeader(headerVisitor.largestHeader));
}
private static void addHeaderIfNeeded(Node document, FileMeta fileMeta) {
String title = fileMeta.title();
final int[] numberOfHeadings = {0};
document.accept(new AbstractVisitor() {
@Override
public void visit(Heading heading) {
numberOfHeadings[0]++;
visitChildren(heading);
}
});
if (numberOfHeadings[0] != 0) {
return; // Not needed.
}
Heading header = new Heading();
Text text = new Text();
text.setLiteral(title);
header.setLevel(1);
header.appendChild(text);
document.prependChild(header);
}
private static void updateLinks(Node document) throws IOException {
UpdateLinksVisitor updateLinksVisitor = new UpdateLinksVisitor();
document.accept(updateLinksVisitor);
Files.writeString(linkFile, String.join("\n", updateLinksVisitor.getLinksSeen()) + "\n", StandardOpenOption.APPEND, StandardOpenOption.CREATE);
System.out.println();
}
The only one that's totally self-contained is addHeaderIfNeeded which creates an anonymous
visitor that just keeps track of how many headers we've seen, if we don't see any then it means I've got
an ancient blogpost from the XeMark days that didn't have a header so I should add one in so the post doesn't
just jump into a paragraph right away.
The other two helpers use some small classes I made that are pretty straightforward. First up, let me show you
LargestHeaderVisitor first. As its name suggests, it's used to find the largest header of a file.
public class LargestHeaderVisitor extends AbstractVisitor {
public int largestHeader = 6;
@Override
public void visit(Heading heading) {
if (heading.getLevel() < largestHeader) {
largestHeader = heading.getLevel();
}
super.visit(heading);
}
}
Small and simple right? Since we're dealing with HTML, we know the smallest a header could be is 6, so
we can just assume that as our starting point, and then if the heading level is a larger header (a small number)
then we can start tracking that one. The last two lines from adjustHeaderSizes actually use
this number to normalize the data via document.accept(new NormalizeHeader(headerVisitor.largestHeader));.
It probably shouldn't surprise you that this is just another visitor:
public class NormalizeHeader extends AbstractVisitor {
private final int knownLargestHeader;
public NormalizeHeader(int knownLargestHeader) {
this.knownLargestHeader = knownLargestHeader;
}
@Override
public void visit(Heading heading) {
heading.setLevel(heading.getLevel() - knownLargestHeader + 1);
super.visit(heading);
}
}
So, the combination between these two visitors results in our markdown document having its headers increased if they aren't already at the largest level. Why? Because on my old site I had an h1 as the site title. Then, an h2 as the section title in the layout. And lastly, the titles all had h3 as what wrapped their titles. Or well, most of them did. Some of the old files didn't, so, the normalize visitor handles all of these cases by just subtracting the largest I found and adding one. The math is pretty simple, but it might be nice to see it out to confirm it works in at least one example:
| Original | Largest Header | Result |
|---|---|---|
| 6 | 6 | 1 |
| 6 | 5 | 2 |
| 6 | 4 | 3 |
| 6 | 3 | 4 |
| 6 | 2 | 5 |
| 6 | 1 | 6 |
If your first instinct is to think: wait, but what if the original is 3 and the largest found is smaller that that? Then I applaud your concern! And also remind you that we're only working with one document at a time, so it's not possible to be in a scenario where the original header we're currently modifying is less than the largest found header because if its level was lower, it would be larger that the largest!
Anyway, with our headers normalized, the markdown files are now ready to fit into the new sites layout where the
post is the largest header on the page. Great. So, what about some of the other helper methods? Well,
updateLinks is simple too. It, well, updates the links!
public class UpdateLinksVisitor extends AbstractVisitor {
private final LinkedList<String> linksSeen;
public UpdateLinksVisitor() {
this.linksSeen = new LinkedList<String>();
}
public LinkedList<String> getLinksSeen() {
return this.linksSeen;
}
@Override
public void visit(Link link) {
link.setDestination(potentiallyUpdateLink(link.getDestination()));
linksSeen.add(link.getDestination());
visitChildren(link);
}
@Override
public void visit(LinkReferenceDefinition linkReferenceDefinition) {
linkReferenceDefinition.setDestination(potentiallyUpdateLink(linkReferenceDefinition.getDestination()));
linksSeen.add(linkReferenceDefinition.getDestination());
visitChildren(linkReferenceDefinition);
}
private String potentiallyUpdateLink(String destination) {
// Ignore links like /images/tech-blog/ I want to keep those pointing to tech-blog
if (destination.contains("/images/")) {
return destination;
}
String updatedLink = destination;
if (updatedLink.contains("/tech-blog/")) {
updatedLink = updatedLink.replace("/tech-blog/", "/blag/");
}
return updatedLink.replace("oldsite.name", "peetseater.space");
}
}
In markdown there are two ways to handle linking off somewhere. You can either do an inline line, like
[mylink](inline), or you can declare the link somewhere else with [link]:foo
and then just reference the link like [link] in the text. So, the visitor has to handle
both LinkReferenceDefinition and Link and then tweak their destination. In
one case, where I reference images used in each post, I don't want to rewrite, but otherwise, I want to
convert any full domain links from my old site name to my new site name.
There's still one other useful visitor I made that I haven't mentioned yet. Remember how I talked about our input file having JSON files with metadata before? Obviously, we're not going to use a markdown visitor to do anything with that, but there were actually a couple cases where I didn't set a title in that metadata. So, what's a programmer to do if you don't have data in one place? Pull it from another!
// In the loading section from before:
Optional<FileMeta> maybeFileMeta = getMetaForPost(inputMarkdownFile);
FileMeta fileMeta = maybeFileMeta.orElse(determineMetaFromFile(document));
...
private static FileMeta determineMetaFromFile(Node document) {
LargestHeaderVisitor largestHeaderVisitor = new LargestHeaderVisitor();
document.accept(largestHeaderVisitor);
FindTitleVisitor titleVisitor = new FindTitleVisitor(largestHeaderVisitor.largestHeader);
document.accept(titleVisitor);
String title = titleVisitor.getPotentialTitle();
return new FileMeta(
title,
Optional.empty(),
Optional.of((LocalDate.now()).format(DateTimeFormatter.ISO_LOCAL_DATE)),
Optional.empty(),
Optional.of("Ethan")
);
}
private static Optional<FileMeta> getMetaForPost(String inputMarkdownFile) throws FileNotFoundException {
Path markdownPath = Paths.get(inputMarkdownFile);
Path metaFile = markdownPath.getParent().resolve("_data.json");
if (!Files.exists(metaFile)) {
return Optional.empty();
}
// The _data.ejs contains the filename without the extension as the object key
String fileKey = getFileKey(inputMarkdownFile);
JsonParser parser = Json.createParser(new FileReader(metaFile.toAbsolutePath().toString()));
if (!parser.hasNext()) {
return Optional.empty();
}
JsonParser.Event rootEvent = parser.next();
if (JsonParser.Event.START_OBJECT != rootEvent) {
return Optional.empty();
}
JsonObject root = parser.getObject();
if (!root.containsKey(fileKey)) {
return Optional.empty();
}
JsonObject rawMetadata = root.getJsonObject(fileKey);
return Optional.of(FileMeta.fromJsonObject(rawMetadata));
}
There's a bit of boilerplate here where we're finding the appropriate meta data json object node to load up, but overall it's a pretty simple use of the javax.json package, which I like since I don't have to do too much thinking about serialization and can just write a simple method like this to get the data I want:
public record FileMeta(
String title,
Optional<String> description,
Optional<String> date,
Optional<String> keywords,
Optional<String> author
) {
static FileMeta fromJsonObject(JsonObject jsonObject) {
return new FileMeta(
jsonObject.getString("title"),
Optional.ofNullable(jsonObject.getString("description", null)),
Optional.ofNullable(jsonObject.getString("date", null)),
Optional.ofNullable(jsonObject.getString("keywords", null)),
Optional.ofNullable(jsonObject.getString("author", null))
);
}
...
}
Anyway, we're getting off track, that helper method to figure out a fallback for when the metadata
doesn't have a title defined is re-using our LargestHeaderVisitor again, and also
using a new Visitor named FindTitleVisitor. That visitor finds the first header of the
given size and returns it.
public class FindTitleVisitor extends AbstractVisitor {
private final int headerToFind;
private String potentialTitle;
public FindTitleVisitor(int largestHeader) {
this.headerToFind = largestHeader;
this.potentialTitle = "";
}
@Override
public void visit(Heading heading) {
if (heading.getLevel() == headerToFind) {
potentialTitle = getHeaderText(heading);
}
}
private String getHeaderText(Heading heading) {
TextContentRenderer textContentRenderer = new TextContentRenderer.Builder().build();
return textContentRenderer.render(heading);
}
public String getPotentialTitle() {
return potentialTitle;
}
}
As all things in this migration, we're relying on the fact that I always have one large header and
then any other headers are smaller in my posts. Which means that this visitor finds the one header
element that I'm using as the title for the post. And so, if we pull out the text for that node with
TextContentRenderer then we've got the data we need.
Pretty nice right? So, now that I've talked your ear off about how we can use lots of little visitors
to massage the data and whatnot, we can turn our attention back to BlagTemplate and see
some of the interesting little edge cases its handling and fun little helpers its using to make our
output look good.
Let's start with the fact that each document is just body content. We're outputing HTML for a full page. So, we need to output the headers and footer. Luckily for us, commonmark has hooks for this type of thing in the node renderer:
@Override
public void beforeRoot(Node rootNode) {
renderDocumentStart();
}
@Override
public void afterRoot(Node rootNode) {
renderDocumentEnd();
}
The two render methods are mine of course, they do exactly what they say they do. The smaller of the two is the footer. And while it may feel a bit backwards, let's look at that one first.
@Override
protected void renderDocumentEnd() {
endBlockTag("article");
endBlockTag("main");
endBlockTag("body");
endBlockTag("html");
}
As you can see, we're ending some html tags in reverse order to what we probably started them in. The helper
method endBlockTag is one of my own helpers I've defined in my Template subclass in
case I ever want to migrate some of the other types of posts from my old site. I only migrated cooking and
tech blog posts this time, but technically there was more than just that. Anyway, the helper and its friend
look like this:
public void startBlockTag(String tag) {
addIndent();
html.tag(tag);
html.line();
increaseIndent();
}
public void endBlockTag(String tag) {
html.line();
decreaseIndent();
addIndent();
html.tag("/" + tag);
html.line();
}
As you can see, a block tag starts off with an indent so it lands in the right place, then proceeds to start up the opening tag and skip a line before increasing the current indent level up. The end to a block tag reverses this process, moving our starting column backwards, indenting one last time, then adding in the ending tag before moving to the next line for the next block to start up. The helper method to add in the indent is a simple loop up to the current indentation level with plain old spaces.
protected void addIndent() {
for (int i = 0; i < indent; i++) {
html.raw(" ");
}
}
What's setting that indent variable? The helpers that were used above of course.
public void increaseIndent() {
for (int i = 0; i < spacesPerIndent; i++) {
this.indent++;
}
}
public void decreaseIndent() {
for (int i = 0; i < spacesPerIndent; i++) {
this.indent = Math.max(0, this.indent - 1);
}
}
Now, this is all well and good for the block tags which basically correspond to normal chunks of the body
we're displaying bit by bit. But what about the inline ones? What about the void tags that never open and
are just bundles of metadata for the browser? We've got helpers for those too of course. So, now let's
turn our attention over to the renderDocumentStart helper I skipped earlier.
@Override
protected void renderDocumentStart() {
startBlockTag("html");
startBlockTag("head");
inlineTag("meta", Map.of("charset", "UTF-8"));
inlineTag("meta", Map.of("name", "viewport", "content", "width=device-width, initial-scale=1.0"));
fileMeta.description().ifPresent(description -> {
inlineTag("meta", Map.of(
"name", "description",
"content", description
));
});
fileMeta.keywords().ifPresent(keywords -> {
inlineTag("meta", Map.of(
"name", "keywords",
"content", keywords
));
});
fileMeta.date().ifPresent(yyyyMMDD -> {
inlineTag("meta", Map.of(
"name", "dcterms.created",
"content", yyyyMMDD
));
});
inlineTag("meta", Map.of("name", "robots", "content", "index, follow"));
inlineTag("meta", Map.of("name", "revisit-after", "content", "1 month"));
inlineTag("title", Escaping.escapeHtml(fileMeta.title()), Map.of());
inlineTag("link", Map.of("href", "/sakura-pink.css", "rel", "stylesheet", "type","text/css", "media", "(prefers-color-scheme: light)"));
inlineTag("link", Map.of("href", "/sakura-dark-solarized.css", "rel", "stylesheet", "type","text/css", "media", "(prefers-color-scheme: dark)"));
endBlockTag("head");
startBlockTag("body");
startBlockTag("header");
startBlockTag("nav");
inlineTag("a", "<button>Home</button>", Map.of("href", "/"));
inlineTag("a", "<button>Recipes</button>", Map.of("href", "/cooking/index.html"));
inlineTag("a", "<button>Blog</button>", Map.of("href", "/blag/index.html"));
inlineTag("a", "<button>Stream</button>", Map.of("href", "https://www.twitch.tv/peetseater"));
inlineTag("a", "<button>Video Archive</button>", Map.of("href", "/video-archive"));
endBlockTag("nav");
endBlockTag("header");
addIndent()
html.tag("hr");
html.line();
startBlockTag("main");
startBlockTag("article");
}
We can see the use of startBlockTag again, but this time we've got the head
element being setup too. And the head is a place in an HTML document that ends up with a lot of meta
tags that don't actually have children at all. Case in point, the meta tag for the charset.
public void inlineTag(String tag, Map<String, String> attr) {
this.inlineTag(tag, "", attr);
}
public void inlineTag(String tag, String contents, Map<String, String> attr) {
addIndent();
html.tag(tag, attr, contents.isBlank());
html.raw(contents);
if (!contents.isBlank()) {
html.tag("/" + tag);
}
html.line();
}
We're leveraging the fact the commonmark call of html.tag(tag, attr, contents.isBlank())'s
signature is this:
public void tag(
String name,
java. util. Map<String, String> attrs,
boolean voidElement
)
It includes an option to emit a self-closing tag if the element is considered a void element. And so, we don't emit the closing tag if the contents are blank, but only if we've got something to display. This nicely lets us reference tags with just attributes from the document render method by passing the name of the tag and the map of attributes. And, if we do have some contents, then we'll call the proper overload and wrap it up in a start and ending tag.
There's a number of optional elements inside of the FileMeta class and so we use isPresent
to run a quick thunk of code if we've got a value to use, otherwise we don't bother emitting things like the
description, keywords, or created date at all. Repeating the inline meta tags and including the styles pretty much
finishes off all of our head tag. So then the rest of the document before the blog post is just the navigation.
The navigation is a nav bar and a bunch of buttons on this site, so unsurprisingly that's exactly what we get.
Since we're using the startBlockTag helpers we get the right indentation, and the inline helpers don't add
any of their own, so we end up with some nicely arranged HTML in our output. With the header and navigation completed,
we're now ready to open up the article tag and then let the body of the markdown file actually start to process.
This is where the fun begins of course. We can now deal with weird edges and funny styles I like in my HTML. Revisiting
the previous code I shared when talking about the BlagTemplate's constructor, you can now see how all those
helpers of mine are coming to our aid in making it nice and simple to write up our customized code block renderers:
protected void addCommentIndent() {
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("<!--");
for (int i = 0; i < indent - 5; i++) {
stringBuilder.append("-");
}
stringBuilder.append(">");
html.raw(stringBuilder.toString());
}
@Override
public void visit(IndentedCodeBlock indentedCodeBlock) {
addIndent();
html.tag("pre");
html.line();
increaseIndent();
String[] lines = indentedCodeBlock.getLiteral().split("\n");
for (String line : lines) {
addCommentIndent();
html.text(line);
html.line();
}
decreaseIndent();
html.line();
addCommentIndent();
html.tag("/pre");
html.line();
}
We've got the usual use of addIndent and friends, but this time we've got our final helper
addCommentIndent which handles my preferred way of indenting pre tags to avoid needing extra
Javascript on the page to render code without a bunch of leading whitespace. The only other thing work mentioning
here is that the entirety of the contents of the pre tag are stored inside of the literal for the instance.
So, we've got to split that up by newines otherwise we'd only output something that would render like this:
This line is fine,
but this is really bad looking.
The use of html.text will handle escaping the <, >, and any other HTML entity that might need
it in whatever code we're putting out onto the page. Otherwise, it's pretty similar to the way we handled other
block tags before.
So, besides the HTML comments, what else did I need to customize in the site migration? Well, regular text nodes have to deal with some XeMark traces:
@Override
public void visit(Text text) {
/* The older jeykl based posts do ###text with no space between ### and text which fails to parse as a header in commonmark */
boolean mightBeAHeaderInDisguise = text.getLiteral().startsWith("#");
// NOT TO DO: Handle edge case of using-encrypted-search-in-chromium?
// I editted the file instead because no thanks.
if (mightBeAHeaderInDisguise) {
char[] chars = text.getLiteral().toCharArray();
char c = chars[0];
int level = 1;
for (int i = 1; i < chars.length; i++) {
char toCheck = chars[i];
if (toCheck == '#') {
level++;
continue;
} else {
break;
}
}
String htag = "h" + level;
html.line();
addIndent();
html.tag(htag);
html.text(text.getLiteral().substring(level));
html.tag('/' + htag);
html.line();
} else {
html.text(text.getLiteral());
}
}
Some of the really really old posts had contents like this:
###Header Text Here And then the body content here
Which commonmark doesn't pick up as being a header, I guess becuase there's no space between the # and the text. Now... the proper way to handle this would be to read the README section called customize parsing and the properly handle the case of the silly pound signs. But that's a lot of work, and I only had a few of these and there really wasn't anything too complicated about each case. All of them followed the same pattern, and all of them were headers that could safely be converted into the level of header they wanted without causing trouble for the rest of the page, so I just hardcoded the change from Text to Header in and called it a day.
Another case where I had to do a bit of tweaking and fiddling to get things to look correct was the HTML blob that's possible to toss into markdown whereever you want.
@Override
public void visit(HtmlBlock htmlBlock) {
String[] lines = htmlBlock.getLiteral().split("\n");
if (lines.length == 1) {
if (lines[0].startsWith("<img") || lines[0].startsWith("<script")) {
addIndent();
html.raw(lines[0]);
html.line();
} else {
html.raw(lines[0]);
}
} else {
html.line();
for (int i = 0; i < lines.length; i++) {
if (i == lines.length - 1) {
decreaseIndent();
}
addIndent();
html.raw(lines[i]);
html.line();
if (i == 0) {
increaseIndent();
}
}
}
}
One of the interesting things about the html block it pretty much counts single line bits of html like when you link an image without using the markdown syntax, or when you include a Github gist via a script tag. I didn't like it when I saw the output of a file look like
some nice indented HTML
<p>
some text
</p>
<script type="blablabla">
<p>
more text
</p>
so, the way to handle it was to check if the html block was just one line long, and then narrow down things by
what the type of tag was. If I didn't do this, it would pick up on the usage of em tags that spanned multiple
lines that I used here or there. Or the usage of the <blockquote></blockquote> tags in
some posts where I'd quoted people. Weirdly, even though commonmark provides an HtmlInline type in addition to the
HtmlBlock type I was visiting, none of the markdown I had ever had a usage of it for me to tweak.
And that was mostly it, the only other node type worth mentioning is probably the soft break type:
@Override
public void visit(SoftLineBreak softLineBreak) {
html.line();
addIndent();
}
Which is very small, but useful. A soft break is when you're in the middle of typing a paragrpah, but because you like to not have eyes that bleed constantly, you press enter and continue your thoughts with the expectation that since you didn't add two returns, you're still typing up text in the same paragraph. If we didn't visit those nodes during renderering, we'd end up with a similar situation as what I showed before when talking about the code block node types. With text indented once, and then never again.
Other node types all looked pretty much something like this:
@Override
public void visit(BulletList bulletList) {
startBlockTag("ul");
visitChildren(bulletList);
endBlockTag("ul");
}
@Override
public void visit(OrderedList orderedList) {
startBlockTag("ol");
visitChildren(orderedList);
endBlockTag("ol");
}
@Override
public void visit(ListItem listItem) {
startBlockTag("li");
visitChildren(listItem);
endBlockTag("li");
}
I needed to add these in, but how did I know what to tweak and what to ignore? What was the process for figuring out the weird edge cases I noted above?
The iterative approach↩
As I said before, if I didn't customize the commonmark NodeRenderer, the resulting HTML would look
something like this. Say, for some markdown like this:
## a header This is the body and stuff.
It would end up looking like this:
<h2>a header</h2><p>This is the body and stuff</p>
Not exactly readable when you've got 20+ paragraphs, links, blockquotes, and everything else in between. Some blocks would break the lines down of course, but it was an inline mess of data that a browser would love, but I would hate.
That said, the fact that it indented nothing was really useful. What'd I'd do is pretty simple:
- Run my script to render the entire directory to an output directory, also stdout
- Scroll the standard up out to find where there was text flush with the left margin
- Determine what type of data was in the markdown that was causing this
- Add the type into the node renderer
- Repeat
Given the limited types markdown has to offer, this didn't take that long. I wasn't reading the entirety of every single post each time, but just scrubbing the scroll up at a slow enough rate that I'd catch the unindented data and examine it, then a little bit of tinkering later and bada bing, bada boom, we've got
@Override
public void visit(BlockQuote blockQuote) {
startBlockTag("blockquote");
visitChildren(blockQuote);
endBlockTag("blockquote");
}
and we're able to repeat the process. That's not to say I didn't read all the blog posts again. I did actually. But only twice, and only after getting pretty much everything else done and I wanted to just go over things with a comb to see if I had missed any weird things.
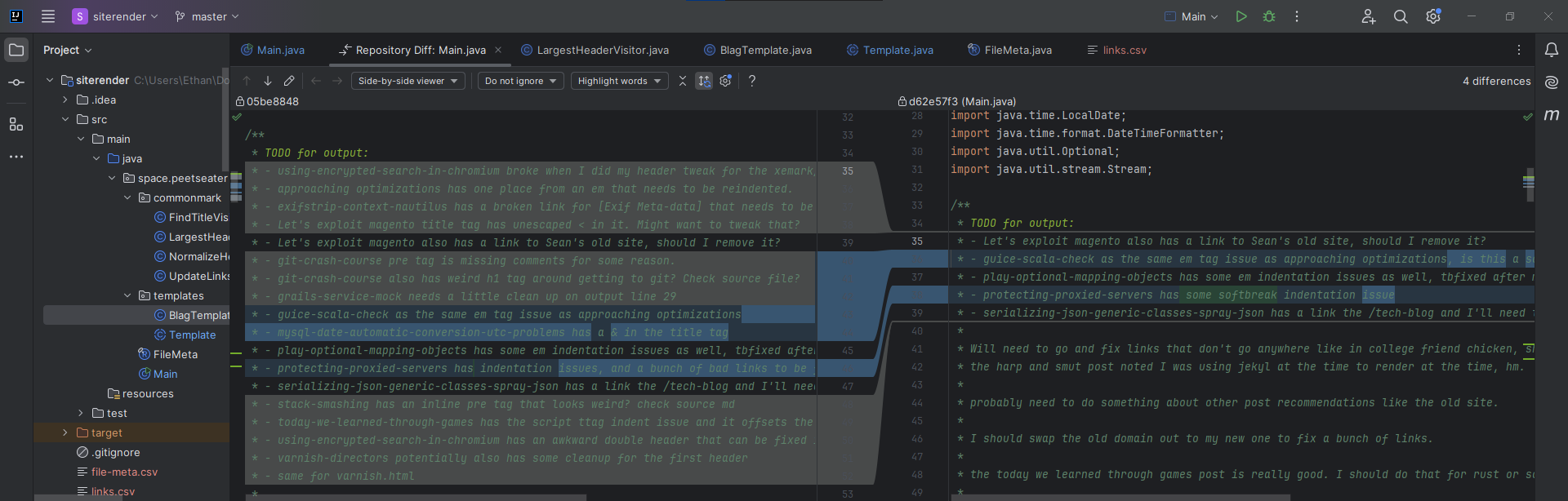
As you can see in my notes in the screenshot. I'd find weird things as I read through the posts, make a note of them and then once I had finished, I'd go ahead and fix them up and commit to git once I had addressed them and remove the note. This worked well for the prolonged period of fixing things since I was only really putting a few minutes a day into this during the week, and not really more than an hour or so at a time on the weekends. Eventually, I sat down for a longer session and finished mostly everything off and ran the script for a final time to create the HTML files. But once that was done, there was still a few things left to do.
I don't want to write a script for that↩
The RSS feed
One of the things I had on my old site, which was automatically generated, was the RSS Feed for the tech blog posts. This was primarily based on the metadata in the JSON files, but of course, we don't have that anymore. So then, what are we to do about generating the feed elements like this:
<item>
<title>Circe, beyond the basics</title>
<link>https://peetseater.space/blag/circe-beyond-basics</link>
<guid>https://peetseater.space/blag/circe-beyond-basics</guid>
<pubDate>Fri, 26 May 2017 00:00:00 GMT</pubDate>
<description>
![CDATA[Looking at examples of how to use the scala json library circe in more involved ways than what is explained in its guide]]
</description>
</item>
Well, we'll just write them out. I only had 12 new posts on this site after all. The time it takes to write 12 items into a feed, versus the time it takes to write a script to read the HTML files, fetch the data from the appropriate meta elements, then add it to the RSS in the right place, in the right format, was not really the same. So. I skipped writing a script for that. I did technically already have all the data in a CSV from some initial work I had been doing, but again. I was feeling extra lazy, so no script for this.
The blog index page
Along a similar vein, I also didn't write a script to make the index page for the site. I certainly could have, but instead I turned to my most reliable too. Sublime Text 2. One of the features I use the most with Sublime Text has always been the way you can instantly have more than one cursor and manipulate data across multiple places. I use it when I program to quickly rename variables, I use it to convert lists of ids into lists of commands to execute for the content identified by those ids, I just sort of use them everywhere. Hell, my default way of highlighting a word is to press ctrl D since it expands the selection around the word I have the cursor in.
So as you can see I'm able to really easily select all the <title> elements in the RSS feed we just
made and collect the title. You can probably see how this is handy. The fact that the link to the page is right beneath it
in the feed is extra helpful, because if I want to make a link like the index page has, I can just do this:
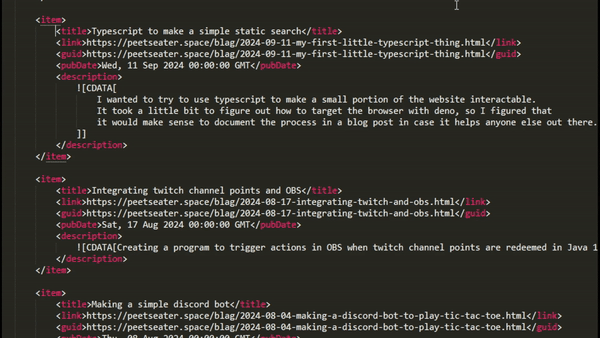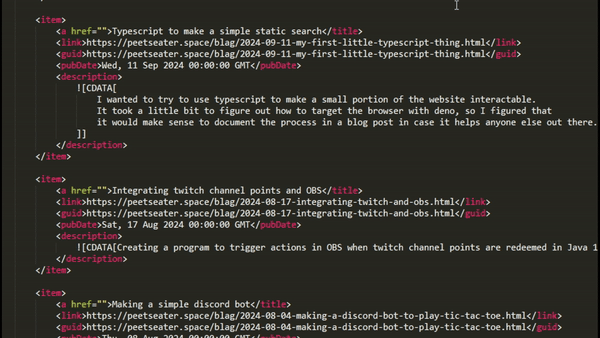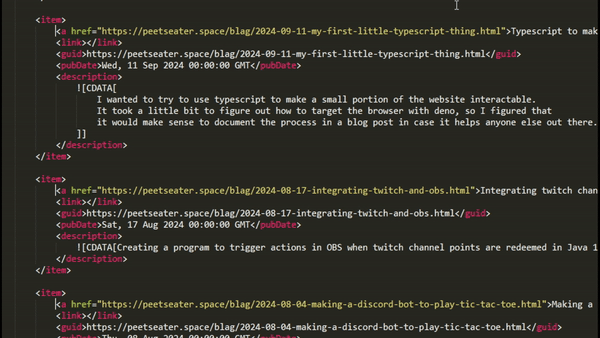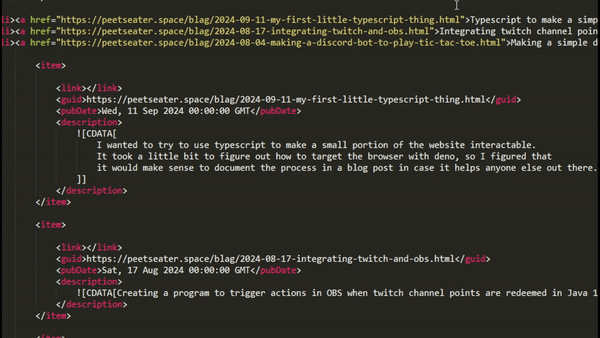
By creating a cursor at every title element, then taking advantage of the fact that the RSS feed has the same number of characters in every positions, I can do a quick: down arrow, home, move forwards 6 characters, shift + end to highlight to the end of the line, then shift and move left until I'm past the link tag and I've got the source of the href. Again, everything is in the same position, so I can cut it, move to the href attribute and paste and then I've got the anchors for every file I need ready to be copied. One Ctrl+X and I've cut all of them out and can paste them all into one spot where I can then transform my list.
Of course, if you look at the index page, you can see that I added in the years to organize the posts a little bit. This wasn't an automated thing like my fancy multi-cursor trick, but it did still take advantage of the fact that we just built up the index list from the feed data. The RSS feed is in reverse chronological order already, so all I had to do was go figure out where the boundaries were and then break up the list at each point. Simple. Again, no script required because I've got a perfect good text editor that can... edit the text really efficiently.
The recipes I migrated
As you can see by clicking on the cooking link there's now actually more than one
recipe on the website. I used to only have a single recipe under the /recipes path, but my old site had
a whole bunch under a cooking path. So, the obvious thing is to choose the path of least resistance and swap everything
over to use the cooking path, right?
Right. But all old posts are pointing to the old recipe path. So, we need to update them. The last time I updated my header links I used a script. But, for this particular issue I wasn't updating just my navigation, I was updating the navigation and any posts that were linking off to those cooking posts. Which, even though I mainly write about tech stuff on the tech blog, I do sometimes. I mean, come on, have you tried my amaretto cookies? They're good and I will shill them to you whenever I can. But, as you can guess by the fact that we're still in the "you don't need a script for this" section, I didn't bother even doing what I did before.
Why? Because we can do this in one line:
find . -type f -exec sed -i 's|/recipes/index.html|/cooking/index.html|g' {} \;
That said don't run that. I, thankfully, keep everything in a git repository, so if I screw something
up I can revert and fix it. That command, with find . , however, managed to do this
$ git status error: inflate: data stream error (invalid distance too far back) error: corrupt loose object '62572ac197e02cdac8acbd493bd2af5e7127625a' fatal: loose object 62572ac197e02cdac8acbd493bd2af5e7127625a (stored in .git/objects/62/572ac197e02cdac8acbd493bd2af5e7127625a) is corrupt "
So, if you were to run something similar, make sure that if you're doing a big ol recursive find + sed
replacement, you use -name .git -prune -o to ignore the git folder or others like it. Now,
thankfully, I also publish my changes to a remote. So all I had to do to fix my now-corrupted index, was
to pull down the repo to a different folder and copy of the .git folder. Everything worked again and I was
able to inspect and commit the changes to the files that I intended to modify.
You should always have a backup ready when you're doing stuff like this. Any sort of inline sed command basically demands you have a backup to revert to if something goes wrong. I don't think I can really emphasize that enough. Don't let past you make problems for future you if you can help it. The tech debt always comes back after a while after all.
We have an RSS feed, we should give people the link
But hey, let's not learn our lesson. We can use sed again to modify the navigation to add in a link to the RSS feed with a quick command! Our RSS link looks like this:
<a id="rss" href="/blag/feed.xml"><img src="/images/RSS_Logo.png" title="RSS Reader Link "/></a>
So, If I want to quickly add it to all the navs in all the HTML files, we should be able to do another find and replace on the link that came before it and produce the result we want.
find . -type f -name "*.html" -not -path "./.git/*" -exec sed -i.bak 's|<a href="/video-archive"><button>Video Archive</button></a>| <a href="/video-archive"><button>Video Archive</button></a>\n <a id="rss" href="/blag/feed.xml"><img src="/images/RSS_Logo.png" title="RSS Reader Link "/></a>|g' {} +
Note that extra spacing for the indentation. We don't want to not match the indentation of the surrouding navigation elements after all. And with another quick command we've got the navigation updated again and really, we just have one last thing to do. Which, this time, I do want to write a script for.
The new naming convention for posts ↩
At first, I did a bit of a sublime text fu to manipualte the links and build dates for each item in the feed again to try to construct a shell script that would do what I wanted:
mv aws-connection-pool-future-sequence-danger.html 2017-Nov-29-aws-connection-pool-future-sequence-danger.html
find ../ -type f -name "*.html" -exec sed -i 's|aws-connection-pool-future-sequence-danger.html|2017-Nov-29-aws-connection-pool-future-sequence-danger.html|g' {} +
find . -type f -name "*.xml" -exec sed -i 's|aws-connection-pool-future-sequence-danger.html|2017-Nov-29-aws-connection-pool-future-sequence-danger.html|g' {} +
# repeat for each post ^
But it didn't seem to play along. I tried doing \( -name "*.html -o -name "*.xml" \) to do the finds in one go,
I broke it up when I saw that a test run of the commands, I checked with grep that I didn't have a weird character preventing
a match. But after staring at it for a few minutes I wasn't sure if I wanted to try to figure out why something running in
git bash might not work properly with windows file formats if that was the case here. So, I figured I'd write a quick script to
do the find replace for me. After all, code can't really lie to me like a weird pseudo shell might.
package space.peetseater;
import java.io.IOException;
import java.nio.file.*;
import java.nio.file.attribute.BasicFileAttributes;
public class ReplaceTheLinks {
String[][] replacements = new String[][]{
new String[]{"aws-connection-pool-future-sequence-danger", "2017-Nov-29-aws-connection-pool-future-sequence-danger"},
...
new String[]{"git-crash-course", "2013-Jul-30-git-crash-course"}
};
public String doReplacements(String input) {
String output = input;
for (String[] tuple : replacements) {
String find = tuple[0];
String replaceWith = tuple[1];
output = output.replaceAll(find, replaceWith);
}
return output;
}
public void replaceInPaths(Path dir) throws IOException {
if (Files.isDirectory(dir)) {
SimpleFileVisitor<Path> visitor = new SimpleFileVisitor<Path>() {
@Override
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
if (!file.getFileName().toString().endsWith("ml")) { // html or xml thanks
return FileVisitResult.CONTINUE;
}
String contents = Files.readString(file);
String newContents = doReplacements(contents);
Files.writeString(file, newContents, StandardOpenOption.WRITE, StandardOpenOption.TRUNCATE_EXISTING);
return FileVisitResult.CONTINUE;
}
};
Files.walkFileTree(dir, visitor);
} else {
String contents = Files.readString(dir);
String newContents = doReplacements(contents);
Files.writeString(dir, newContents, StandardOpenOption.WRITE, StandardOpenOption.TRUNCATE_EXISTING);
}
}
}
Of course, doing this with a giant list of just the names isn't a perfect choice. While nearly
all the posts have multiple parts to the url slug that leave them unique, some other ones don't. For example,
the blog post for varnish causes an issue since the word "varnish"
is used in quite a few places. So, without being careful I'd end up with a link like www.2014-Feb-17-varnish-cache.org
which is no good.
That said, it's not too hard to avoid. I can cause as many problems as I want because I can just use git add -p when I
commit the changes to make sure I don't do anything silly. If you've never used it before, it's the interactive mode for adding
patches, one hunk at a time:
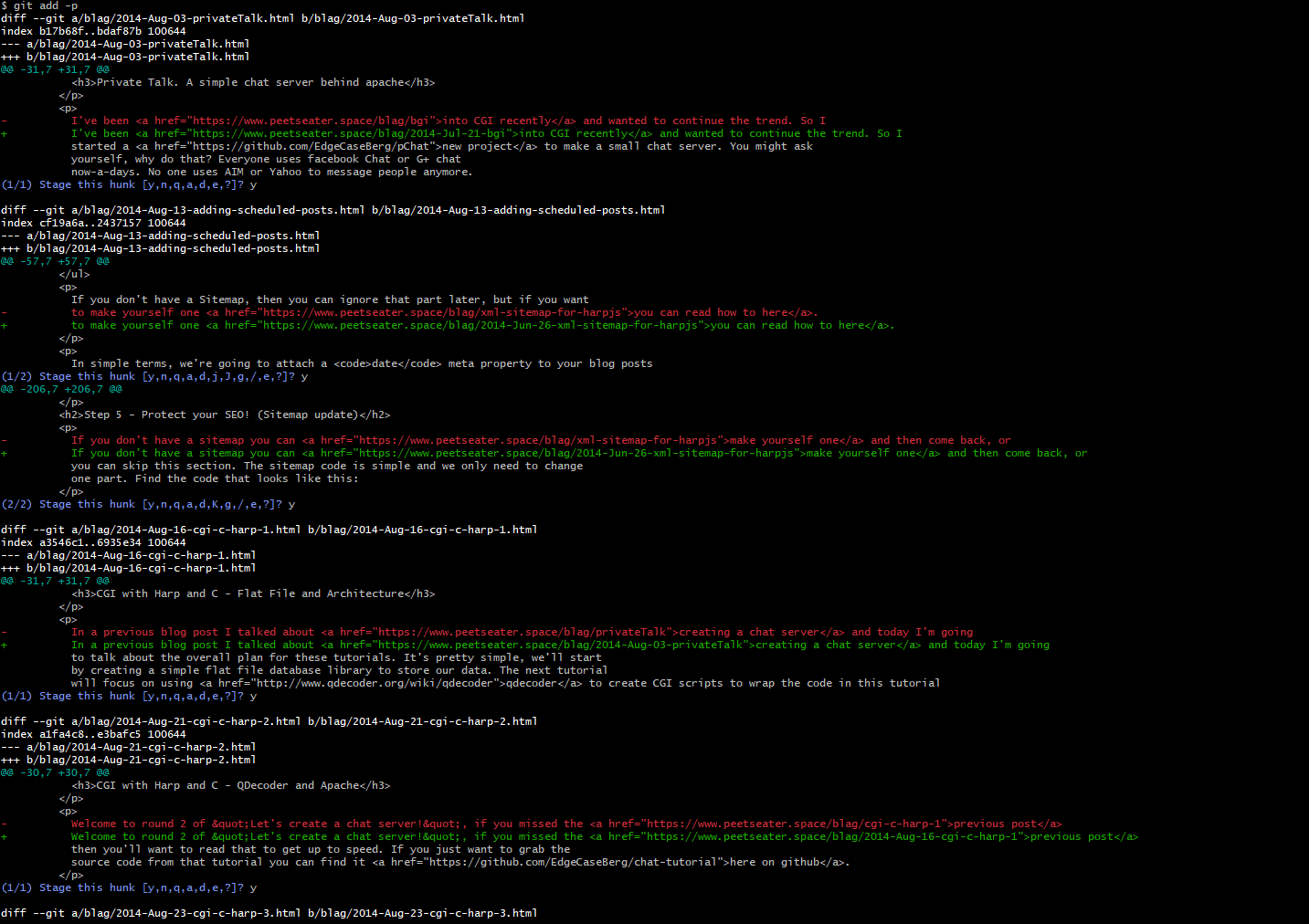
As you can see, each hunk is shown to me with an easy to read green and red diff. I press y if I want the changes, e if I want to tweak them, and n if I don't want it. If there's an entire file I know is good, I can press a to accept all the changes at once. And if there's a file I don't want any changes at all from, then I can use d for that. And with that, I had all the changes I wanted done for my site migration!
Final wrap up and thoughts ↩
According to my git log, I started in on my fun side quest of creating a markdown parser on October 5th around 6:30pm, and then coded until 12:30am where I paused with my first shot at a paragraph parser. Today, when I'm writing this outro bit, is November 24th around 5pm. So, the whole process of doing this site migration and also writing up my explanation about it took close to two months.
Which is horrendously slow. I can't but laugh. But, considering that I took a detour to implement my own markdown parser and generator and I had fun. I think it was fine. Sometimes it's just a good time reinventing the wheel for the sake of understanding why someone would craft their wheel out of wood or rubber. You learn a lot along the way, and find out what not to do as well as why some patterns work better than others.
Some parts of the migration were a slog. I mean, the last time I added proper code to the migration and wasn't just doing slight tweaks to address one posts weird one off issue was on the 10th. So it's been 2 weeks of just doing little tweaks here and there, adjusting links, fiddling with some CSS or what have you. All the things I don't really want to do but that I have to in order to feel satisfied that I properly migrated my site. It doesn't surprise me that I'm itching to move on to my next project, and that I'm looking forward to when I can finally go over all the code on stream and give a deeper dive of an explanation than this post did for anyone who's curious.
The last thought I had was that I'm really thankful that I have a lot of habits that have stayed the same, and that my habits are generally future proof for future me to not have a problem. I mean, if I didn't keep styles consistent and regular, then my sublime text tricks of multicursors and manipulating hundreds of lines at once wouldn't work. If I didn't keep track of when I posted each post, I couldn't swap to my new style for the older posts. Heck, even the fact that my weird little XeMark was a subset of markdown came in handy.
It's really interesting opening a time capsule, and older blog posts that I wrote over a decade ago are like that for me. I can see where I learned new things, I can remember when certain life events happened and how they impacted me. Just in the frequency of posting I can tell when I threw myself into work, when I was obsessed with something, and for better or worse, when I burned myself out and took a long break. The fact that there's a four year gap from 2017 to 2021 isn't a coincidence. It's when I started streaming to twitch, and it's when I really needed a break from a lot of personal things. It's no coincidence that my foray back into blogging coincides with finding Sebastian Lague's tutorials. There's another gap in there when I took on a new role at work and my focus shifted from being deep in the weeds on technical things, to being a bit higher up in the conceptual ladder of the Robert Katz scale.
And now we're in another section of my life where I'm blogging actively again, but this time, instead of the short and sweet posts of the past me. Where everything was new and I wanted to share even the smallest little thing I saw, I'm now trying to write longer posts. Trying to fill in the gap that I see in a lot of CS blogs, the long-form posts that try to teach an entire project to someone, not just a tiny sample of something, but a full system and framework, guiding people through my thought process and design in things, and trying to give folks something interesting at the end. There was only one blog post in 2023, but it took me months to write because creating an match 3 game from scratch isn't a simple afternoon project.
I think this is a good direction for me. I enjoy teaching people things and algorithms are fun. Programming for the sheer joy of it is way more fun than programming just to get something done. Though that's also why it took me 2 weeks to finish up this site migration, since those chore-type things drain my motivation a lot. But hey, here's to hoping that my motivation stays high for many more blog posts to come and we make some interesting things in the future!
If you read even half of this post, thanks. I hope you got something out of it. It's not like any of this code will be relevant to anyone else's site, but you never know, getting a run down on how to use commonmark and how to customize the output for your own tastes might be helpful to someone someday. I don't have ads on my site or anything, so if this helped at all, feel free to swing by my channel and leave me a note. I'd love to hear from you.